问题 - 数据库与缓存不一致如何解决
更新缓存的的Design Pattern有四种:Cache aside, Read through, Write through, Write behind caching。
概述
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品等。怎么解决呢?
一般有如下几种方案:
Cache Aside Pattern 旁路缓存:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
Read/Write Through Pattern : 缓存与数据库集成为一个服务,服务保证两者的一致性,对外暴露API接口。调用者调用API,无需知道自己操作的是数据库还是缓存,不关心一致性。
Write Behind Caching Pattern:调用者只操作缓存,其他线程去异步处理数据库,实现最终一致。
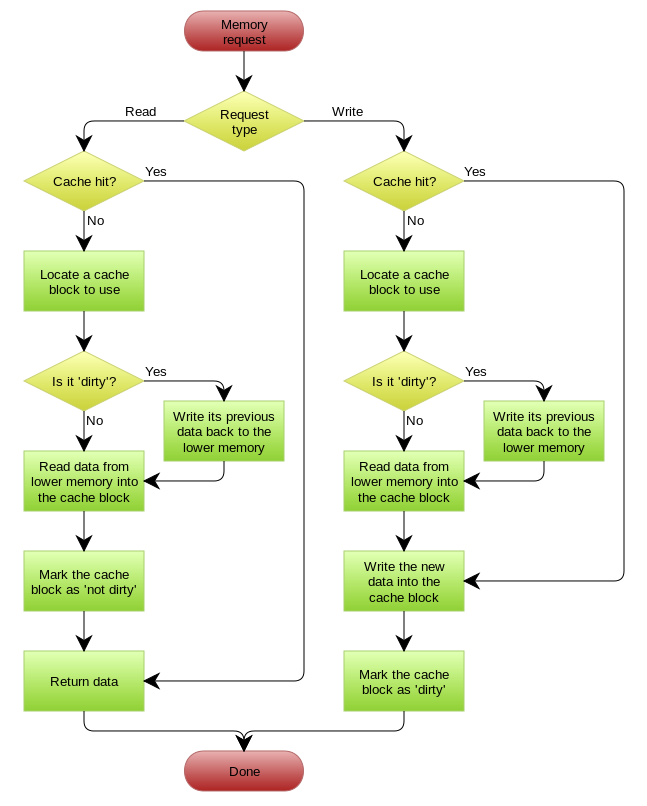
Cache Aside Pattern
具体逻辑如下:
- 失效:应用程序先从cache取数据,如果没取到,则从数据库中取数据,成功后,再更新到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
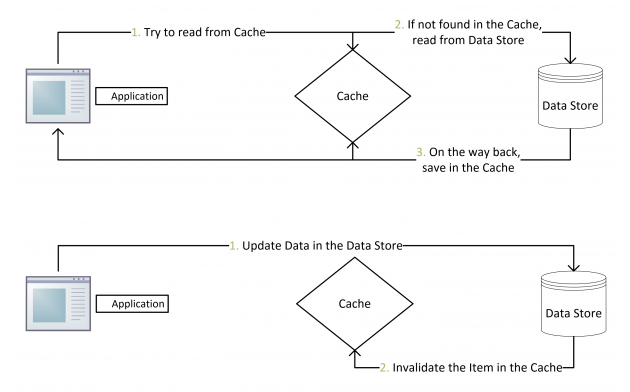
Read/Write Through Pattern
Read Through
在查询操作中更新缓存。当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)。
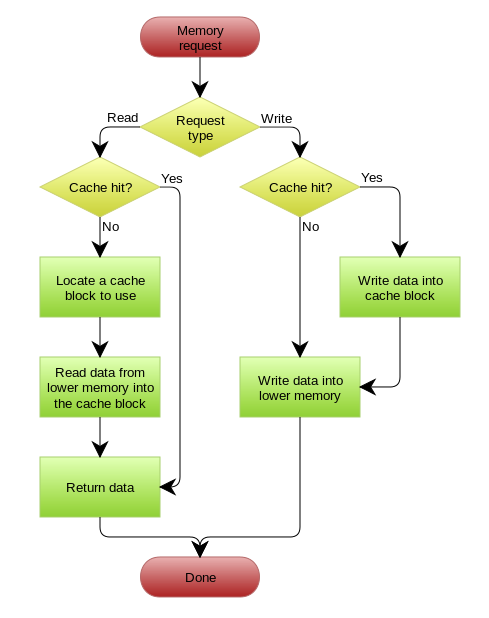
Write Behind Caching Pattern
在更新数据的时候,只更新缓存,不更新数据库。而缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(直接操作内存),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。