第3章 数据存储与检索
概述
从最基本的层面看,数据库只需做两件事:向它插入数据时,就保存数据;之后查询时,就返回对应数据。
数据库核心:数据结构
#!/bin/bash
function db_set()
{
echo "$1,$2" >> database
}
function db_get()
{
grep "^$1," database | sed -e "s/^$1,//" |tail -n 1
}
function testfun()
{
db_set "name" "Jason"
db_set "age" "16"
db_get "name"
db_set "name" "Helen"
db_get "name"
db_get "age"
}
testfun2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
对应简单场景,追加到文件结尾的方式足够高效,许多数据库使用的日志也是采用追加式更新方式。
但是,对于日志文件保存大量记录的情况,db_get函数的执行效率会很低。
进而引出索引的概念,索引是基于原始数据派生而来的额外数据结构。很多数据库允许单独添加和删除索引,而不影响数据库的内容,它只会影响查询性能。
由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
需要权衡:适当的索引可以加速读取查询,但每个索引都会减慢写速度。默认情况下,数据库通常不会对所有内容进行索引,它需要应用开发人员或数据库管理员,基于对应用程序典型查询模式的了解,来手动选择索引。目的是为应用程序提供最有利加速的同时,避免引人过多不必要的开销。
哈希索引
索引策略:保存内存中的hash map,把每个键一一映射到数据文件中特定的字节偏移量,这样就可以找到每个值的位置,如图所示。
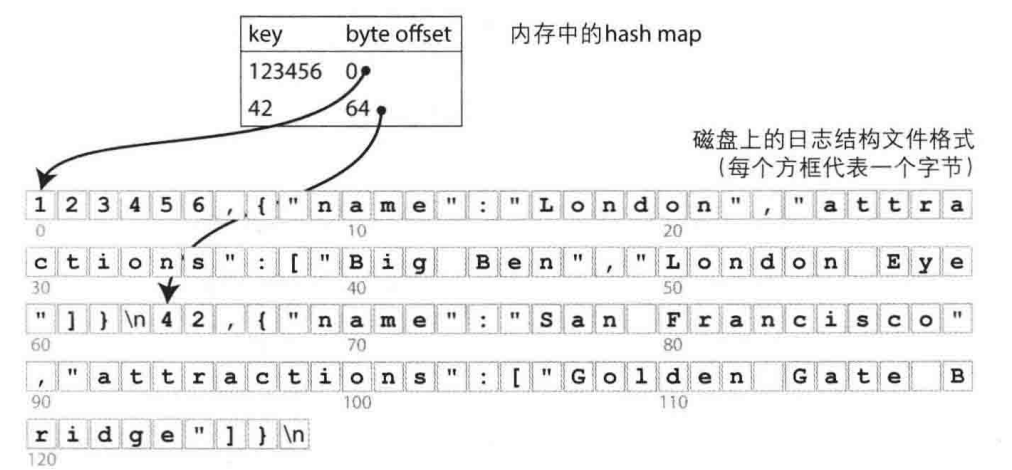
- 写入:每当在文件中追加新的key-value对时,还要更新hash map来反映刚刚写人数据的偏移量(包括插人新的键和更新已有的键)。
- 读取:当查找某个值时,使用hash map来找到文件中的偏移量,即存储位置,然后读取其内容。
如过不断追加信息加到一个文件,那么如何避免最终用尽磁盘空间?
———— 将日志分解成一定大小的段,当文件达到一定大小时就关闭它,并将后续写人到新的段文件中。然后可以在这些段上执行压缩。压缩意味着在日志中丢 弃重复的键,并且只保留每个键最近的更新。为了提高效率,可以同时对多个段进行合并和压缩,采用后台线程处理方式。合并过程中,依旧可以读写旧的段文件,合并完成后,将读写操作切换到新的合并段上,将旧的段文件进行清理。

同时需要考虑以下因素
- 文件格式
- CSV并非最佳文件格式,更快更简单方法是二进制格式。
- 删除记录
- 崩溃恢复
- 部分写入的记录
- 并发控制
一个追加的日志乍看起来似乎很浪费空间:为什么不原地更新文件,用新值覆盖旧值?
但是,结果证明追加式的设计非常不错,主要原因有以下几个:
- 追加和分段合并主要是顺序写,它通常比随机写人快得多,特别是在旋转式磁性盘上。
- 如果段文件是追加的或不可变的,则并发和崩溃恢复要简单得多。例如,不必担心在重写值时发生崩溃的情况,留下一个包含部分旧值和部分新值混杂在一起的文件。
- 合并旧段可以避免随着时间的推移数据文件出现碎片化的问题。
缺点:
- 哈希表必须全部放入内存,键值对过多很难维护。
- 区间查询效率不高,只能逐个查询。
SSTables和LSM-Tree
要求key-value对的顺序按键排序,这种格式称为排序字符串表(Sorted String Table,SSTable)
SSTable相比哈希索引的日志段,具有以下优点:
合并段更加简单高效,即使文件大于可用内存。
在文件中查找特定的键时,不再需要在内存中保存所有键的索引。
由于读请求往往需要扫描请求范围内的多个key-value对,可以考虑将这些记录保存到一个块中并在写磁盘之前将其压缩。然后稀疏内存索引的每个条目指向压缩块的开头。除了节省磁盘空间,压缩还减少了I/O带宽的占用。
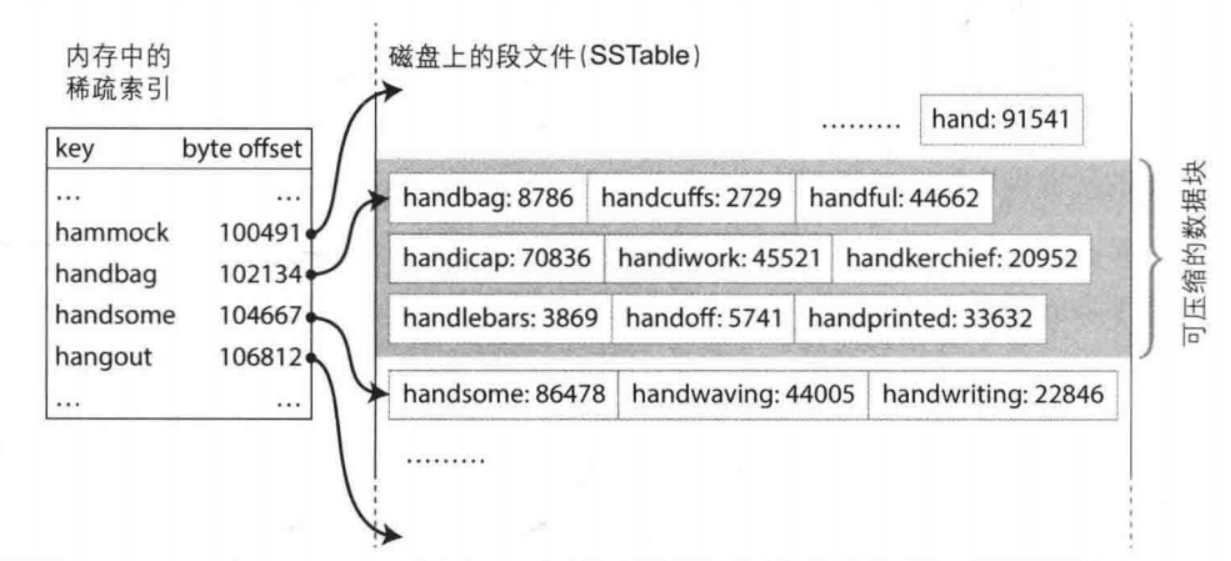
构建和维护SSTable
存储引擎的工作流程:
- 当写人时,将其添加到内存中的平衡树数据结构中。这个内存中的树有时被称为内存表。
- 当内存表大于某个阈值时,将其作为SSTable文件写人磁盘。由于树已经维护了按键排序的key-value对,写磁盘可以比较高效。新的SSTable文件成为数据库的最新部分。当SSTable写磁盘的同时,写人可以继续添加到一个新的内存表实例。
- 为了处理读请求,首先尝试在内存表中查找键,然后是最新的磁盘段文件,接下来是次新的磁盘段文件,以此类推,直到找到目标。
- 后台进程周期性地执行段合并与压缩过程,以合并多个段文件,并丢弃那些已被覆盖或删除的值。
上述工作流程正是LevelDB和RocksDB这类key-value存储引擎库所使用的。
从SSTable到LSM-Tree
基于合并和压缩排序文件原理的存储引擎通常都被称为LSM存储引擎。
性能优化
针对查询数据库中某个不存在的键时,LSM-Tree算法可能比较慢(必须先检查内存表,然后将段一直回溯访问到最旧的段文件)。为了优化这种访问,存储引擎通常使用额外的布隆过滤器,如果数据库中不存在某个键,它能够很快告诉你结果,从而节省了很多对于不存在的键的不必要的磁盘读取。
对比B-tree和LSM-tree
LSM-tree因为磁盘是顺序写入的,保证写速度快;而B-tree则更加适用于读操作。
LSM-tree优缺点:
优点:
- 吞吐量:B-tree索引必须写至少两次数据,一次写入预写日志(write-ahea log,WAL),一次写入树的页本身。LSM-tree能承受更高的写入吞吐量。
- 磁盘空间:LSM-tree可以支持更好地压缩,通常磁盘文件比B-tree小得多。
- 碎片化:B-tree存在页分裂等问题导致某些磁盘空间无法使用;LSM-tree定期重写SSTable以消除碎片化。
缺点:
- 压缩过程有时会干扰正在进行的读写操作
- 磁盘有限的写入带宽需要满足写入和后台压缩进程。
事务处理与分析处理

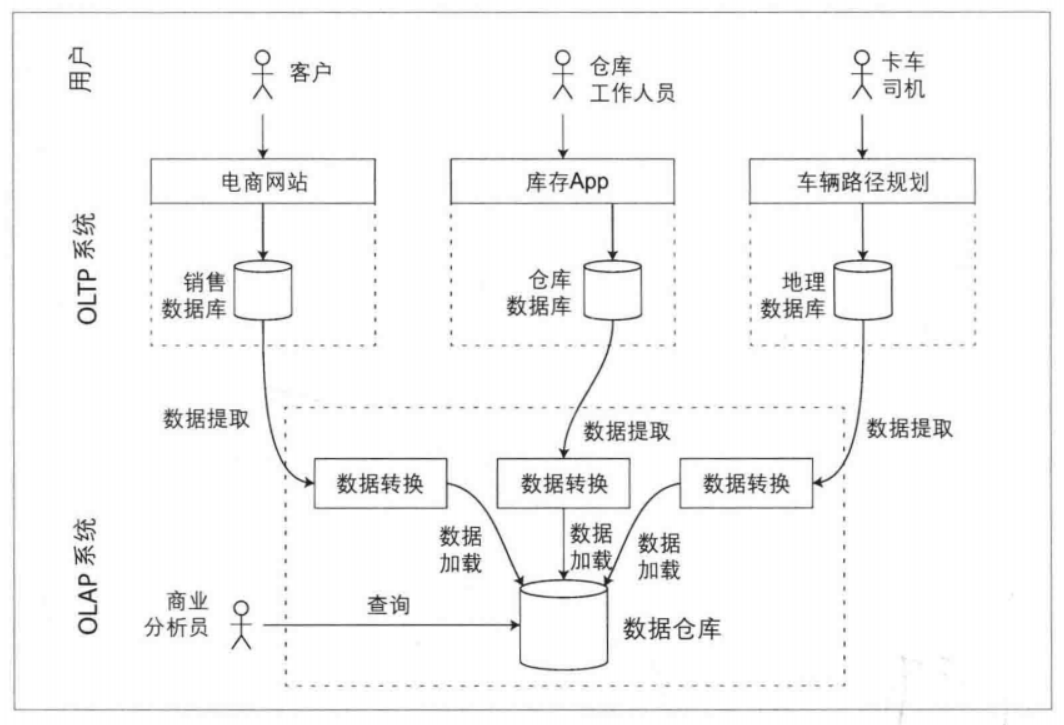
数据仓库是单独的数据库,包含公司所有各种OLTP系统的只读副本。从OLTP数据库(使用周期性数据转储或连续更新流)中提取数据,转换为分析友好的模式,执行必要的清理,然后加载到数据仓库中。将数据导人数据仓库的过程称为提取一转换一加载(Extract-Transform-Load,ETL)。
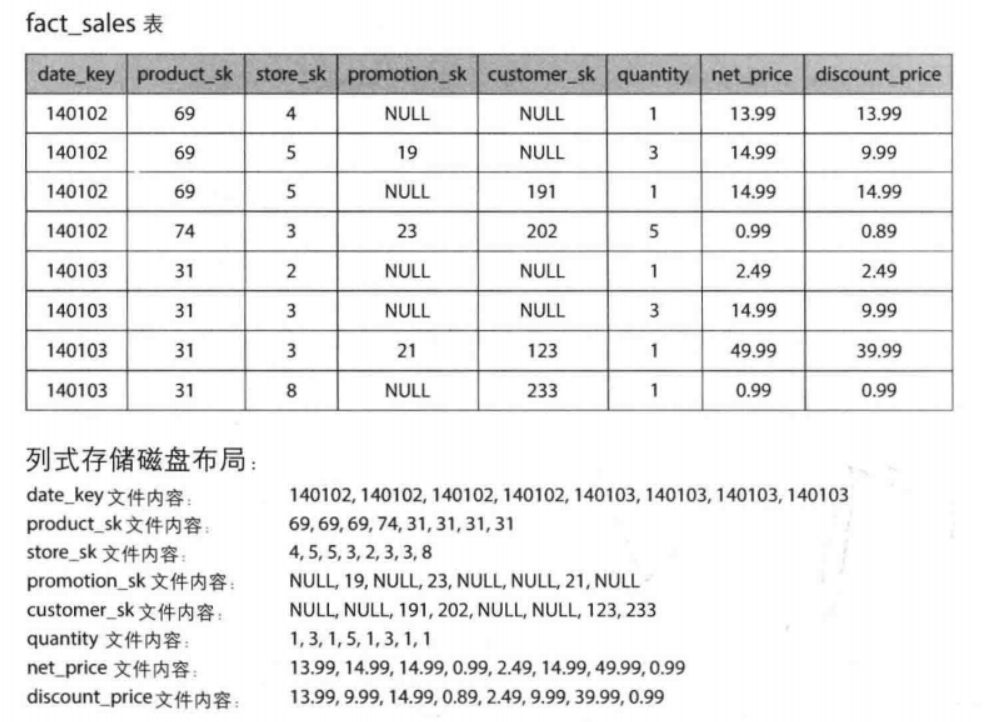
列式存储
实际生活应用中,数据仓库一次查询操作往往只需要访问其中某几列进行分析,但是,面向行的存储引擎仍然需要将所有行(每个由超过100个属性组成)从磁盘加 载到内存中、解析它们,并过滤出不符合所需条件的行。这可能需要很长时间。
面向列存储思想:不要将一行中的所有值存储在一起,而是将每列中的所有值存储在一起。如果每个列存储在一个单独的文件中,查询只需要读取和解析在该查询中使用的那些列,这可以节省大量的工作。