微服务 - 多级缓存
本节主要介绍多级缓存的内容。
概念
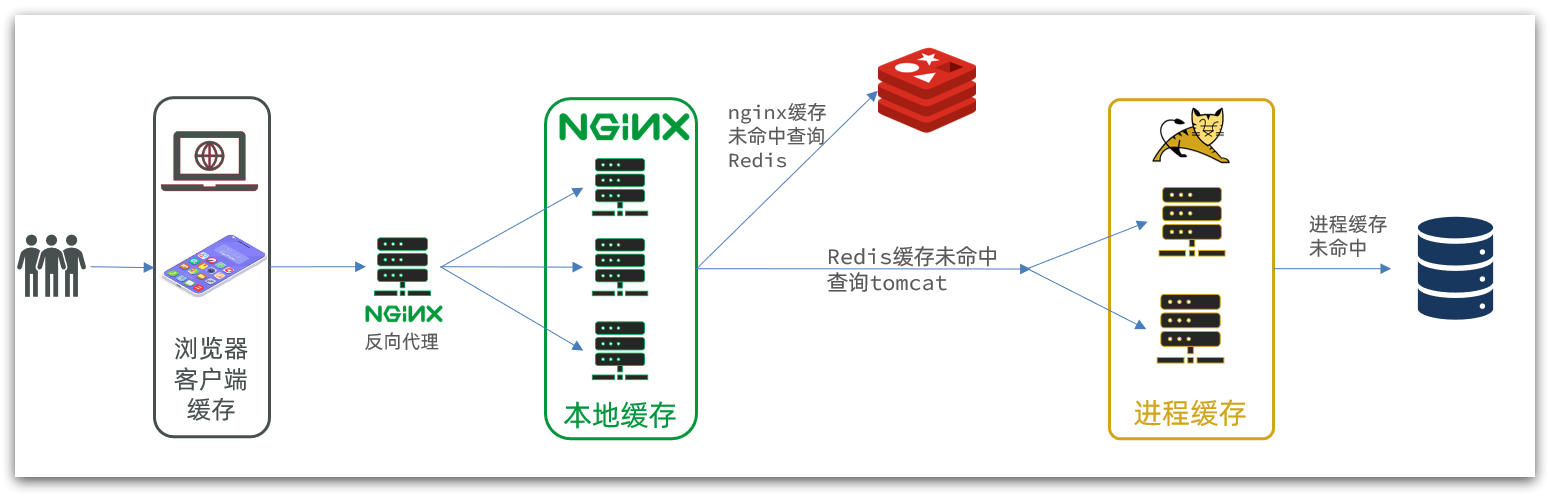
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:
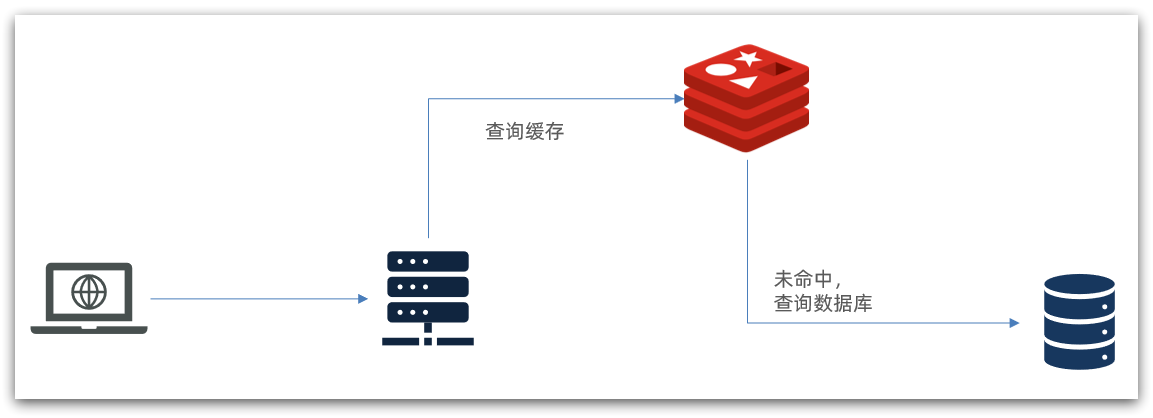
从上述请求的流程可知,存在下面的问题:
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
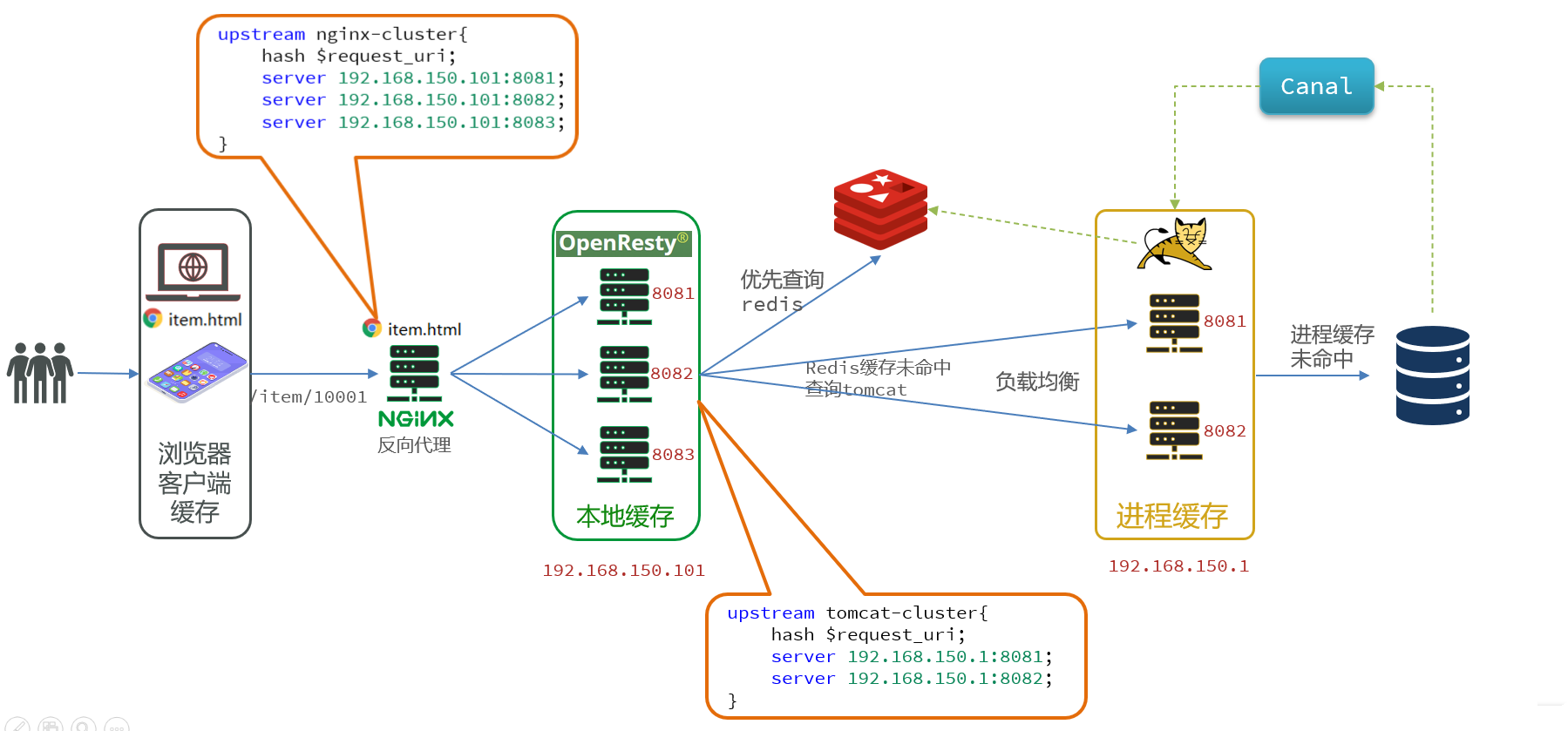
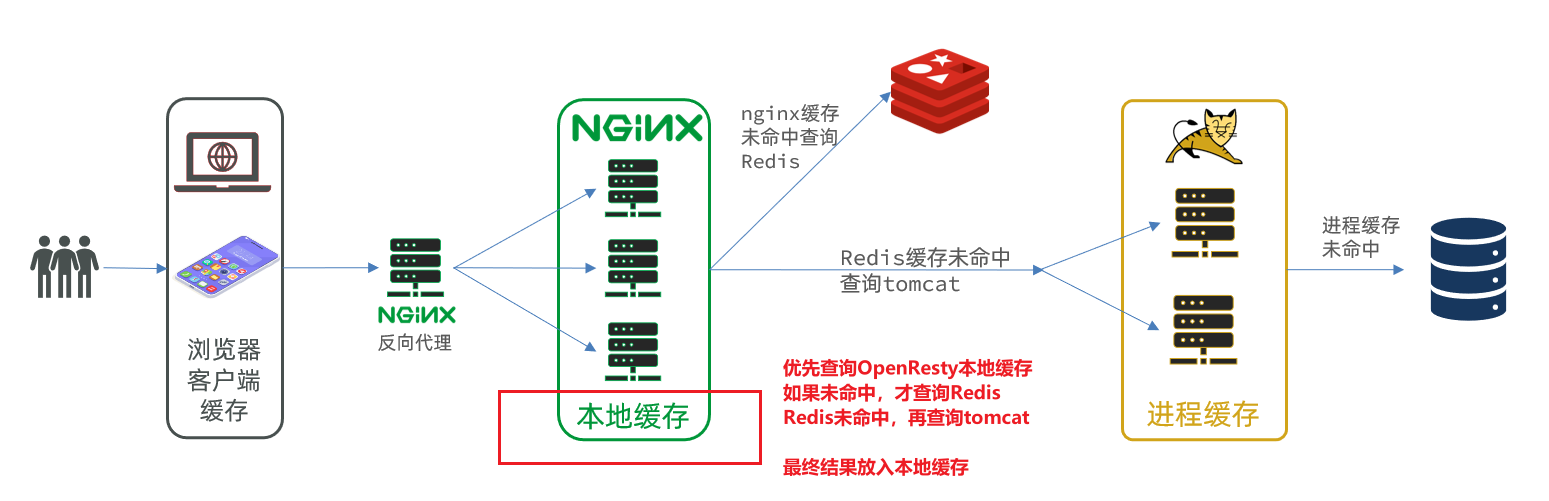
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
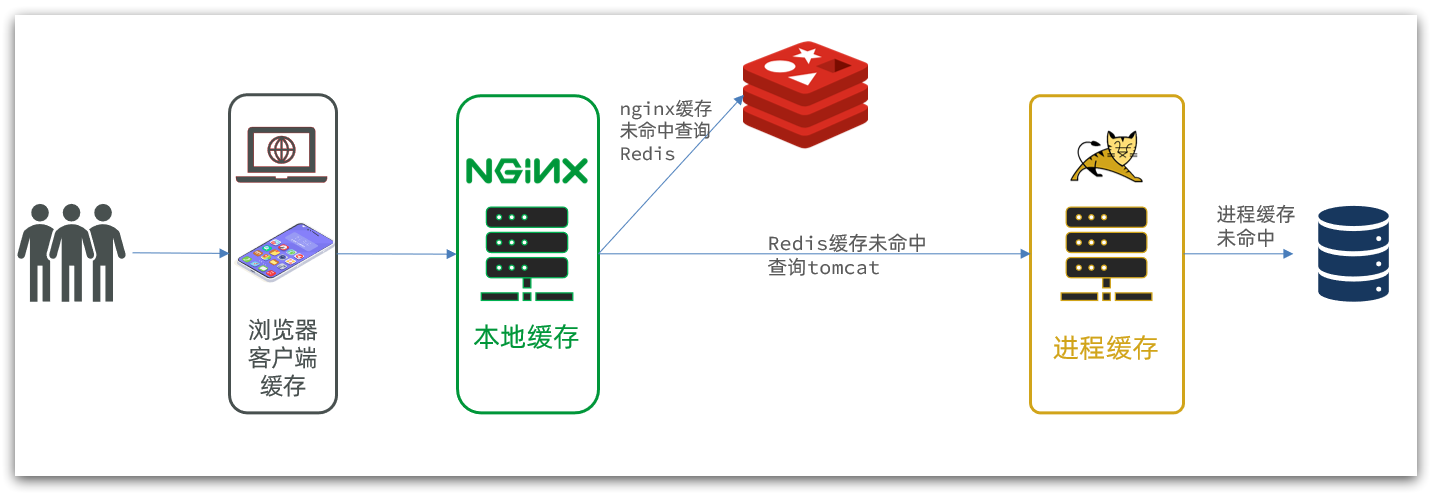
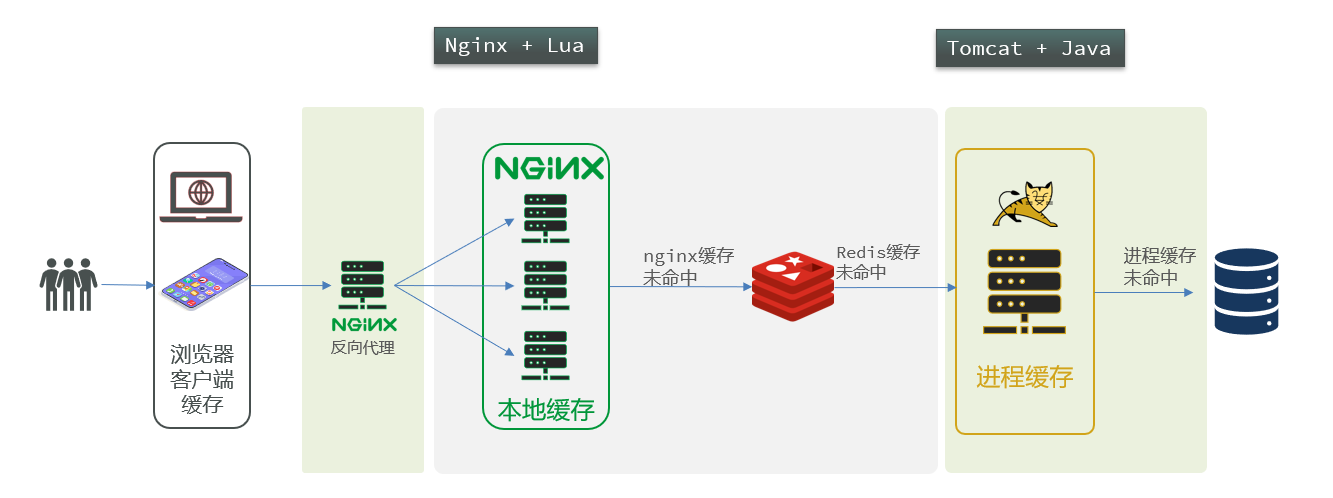
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
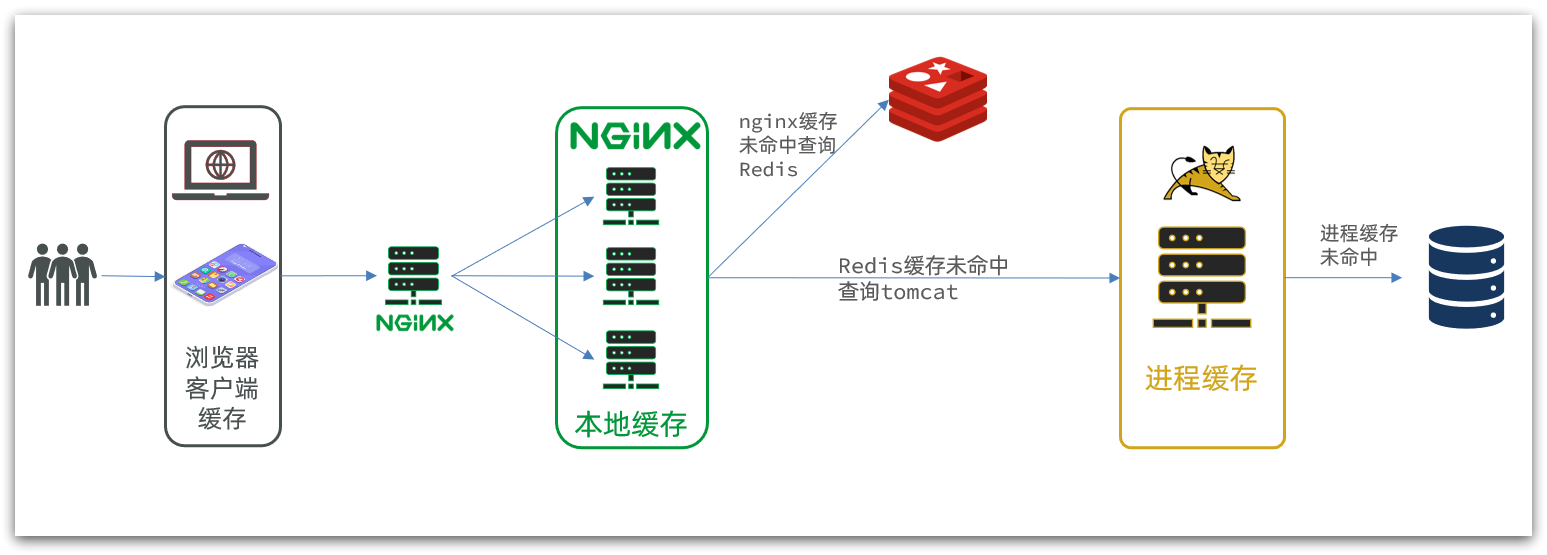
另外,我们的Tomcat服务将来也会部署为集群模式:
可见,多级缓存的关键有两个:
在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合 **Lua ** 这样的语言。
JVM进程缓存
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 本地进程缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
本地进程缓存采用Caffeine实现。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Nginx本地缓存
OpenResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
数据同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
而异步实现又可以基于MQ或者Canal来实现:
1)基于MQ的异步通知:
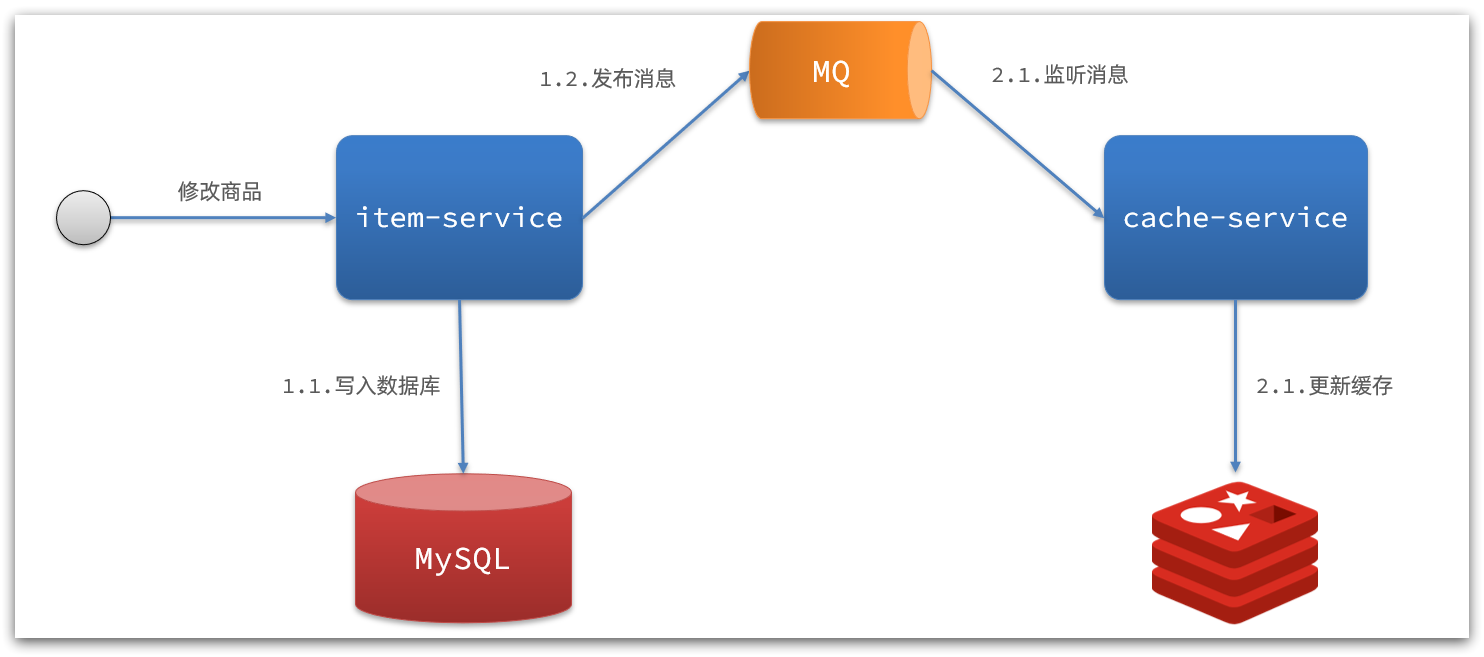
解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新
依然有少量的代码侵入。
2)基于Canal的通知
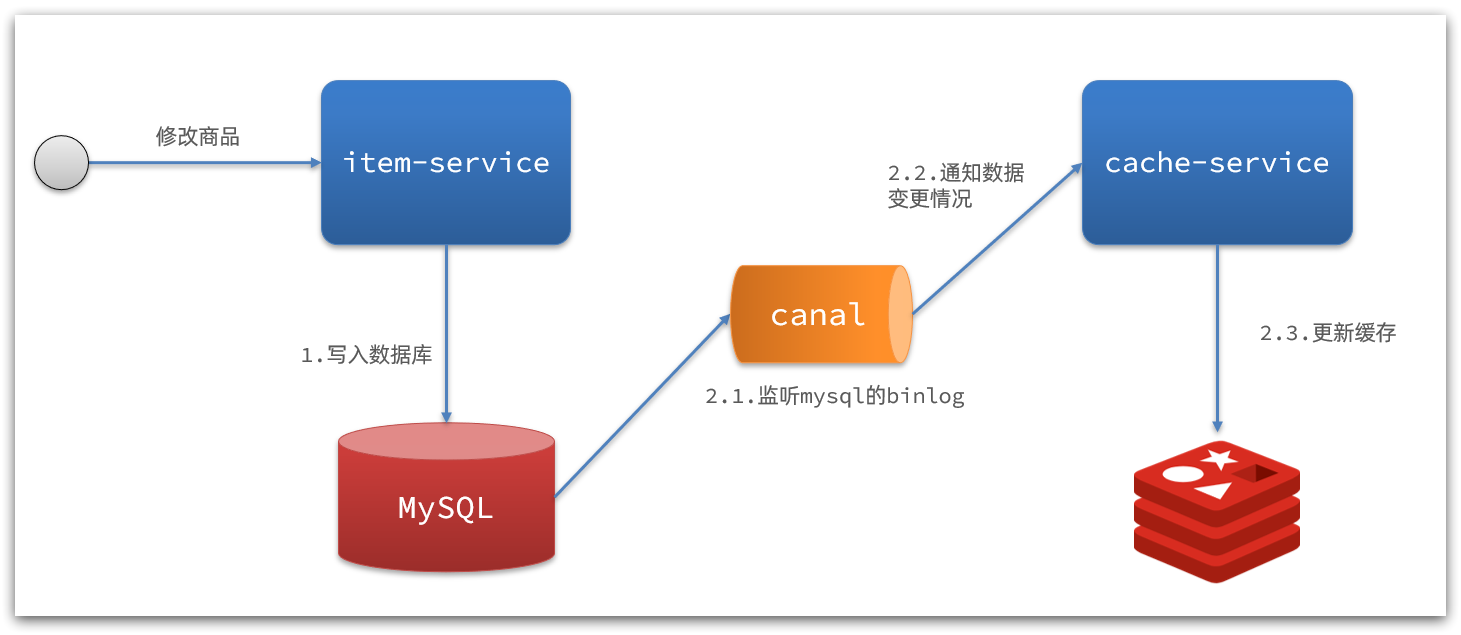
多级缓存总结