ElasticSearch数据 - 分析与处理
主要介绍elasticsearch的数据分析与处理功能。
数据聚合
聚合(aggregations) (opens new window)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合的种类
聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL实现聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
Bucket聚合语法
语法如下:
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
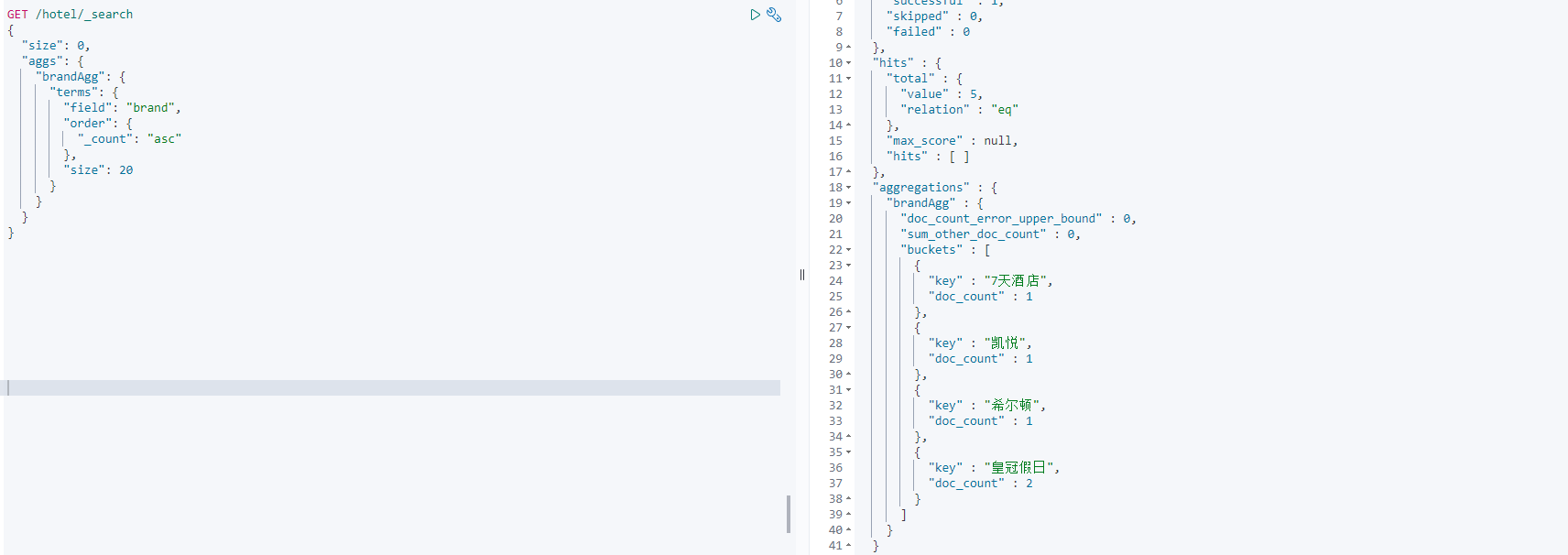
聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc"
},
"size": 20
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
结果如图:
限定聚合范围
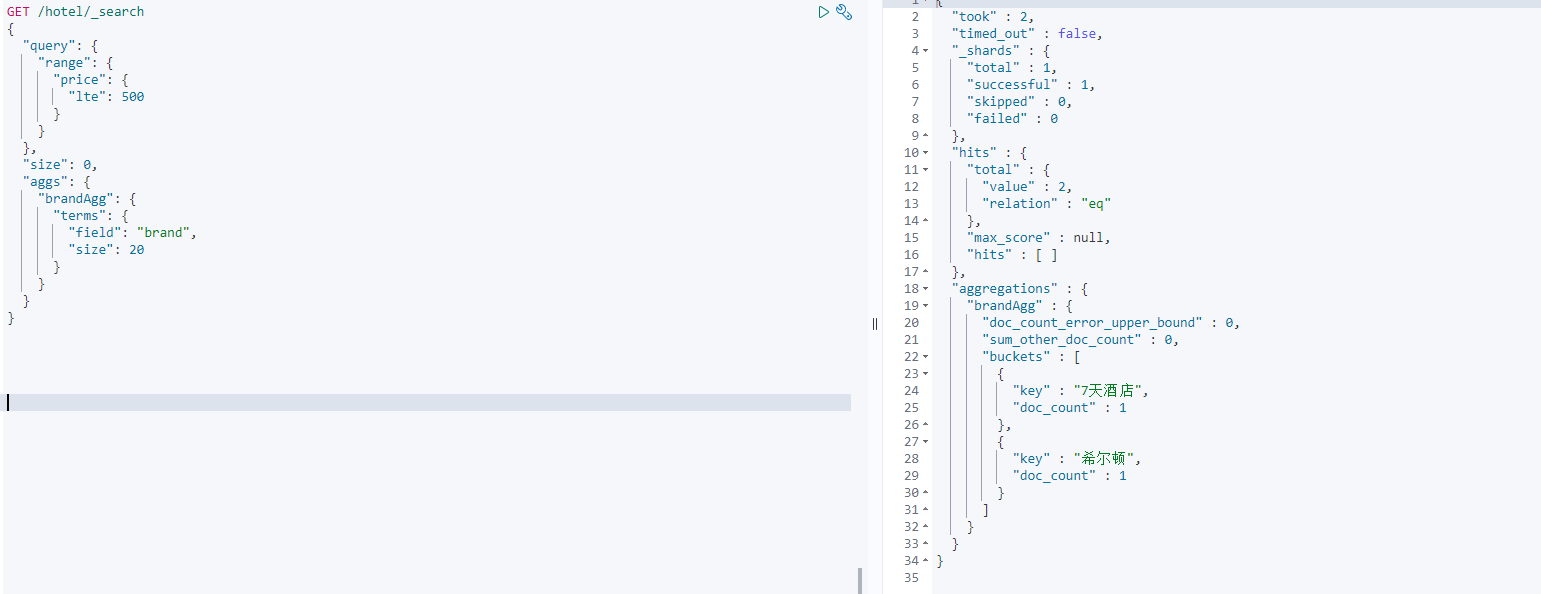
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这次,聚合得到的品牌明显变少了:
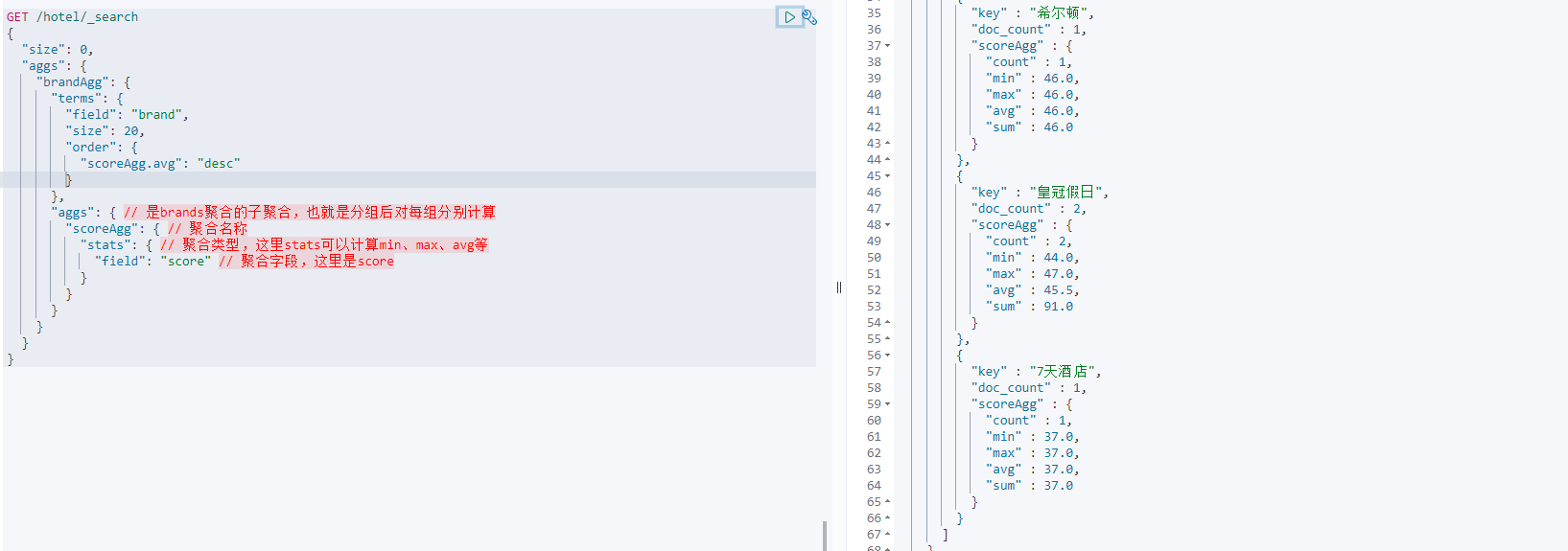
Metric聚合语法
上节课,我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"scoreAgg": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
小结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
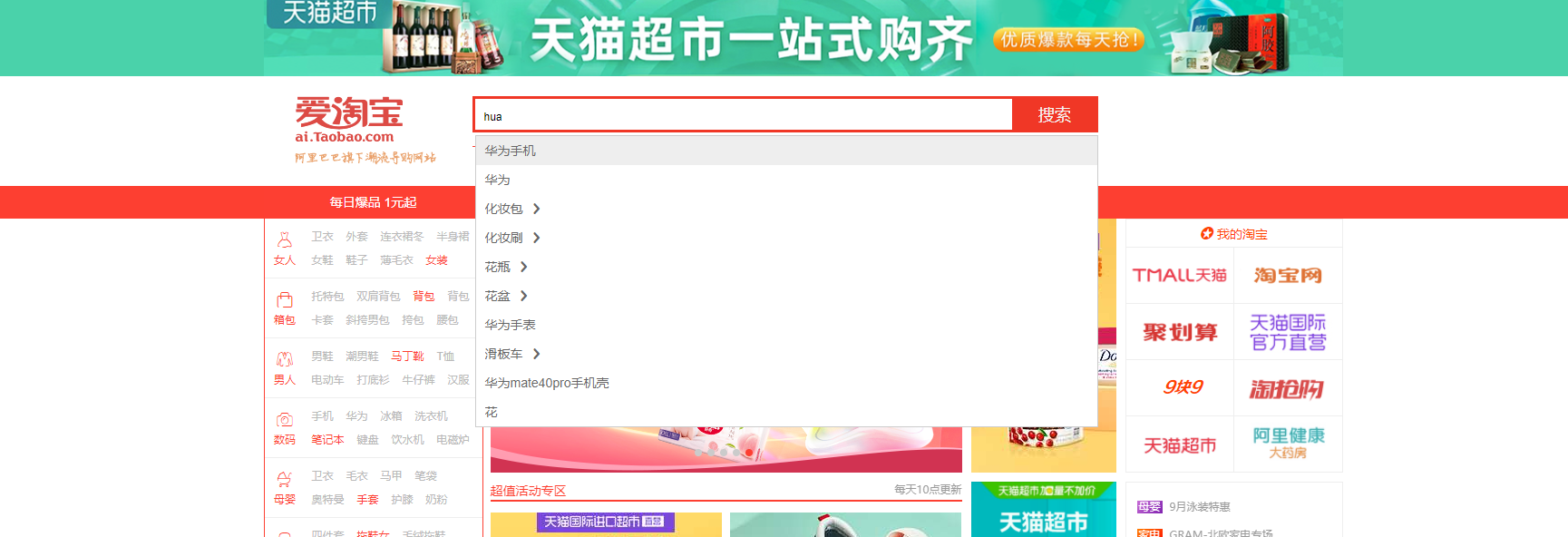
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件 (opens new window)。
可以直接使用elasticsearch-analysis-pinyin-7.12.1.zip 拼音分词器的安装包:
安装方式与IK分词器一样,分三步:
- 解压
- 上传到虚拟机中,elasticsearch的plugin目录。(docker volume inspect es-plugins)
- 重启elasticsearch
- 测试
详细安装步骤可以参考IK分词器的安装过程。
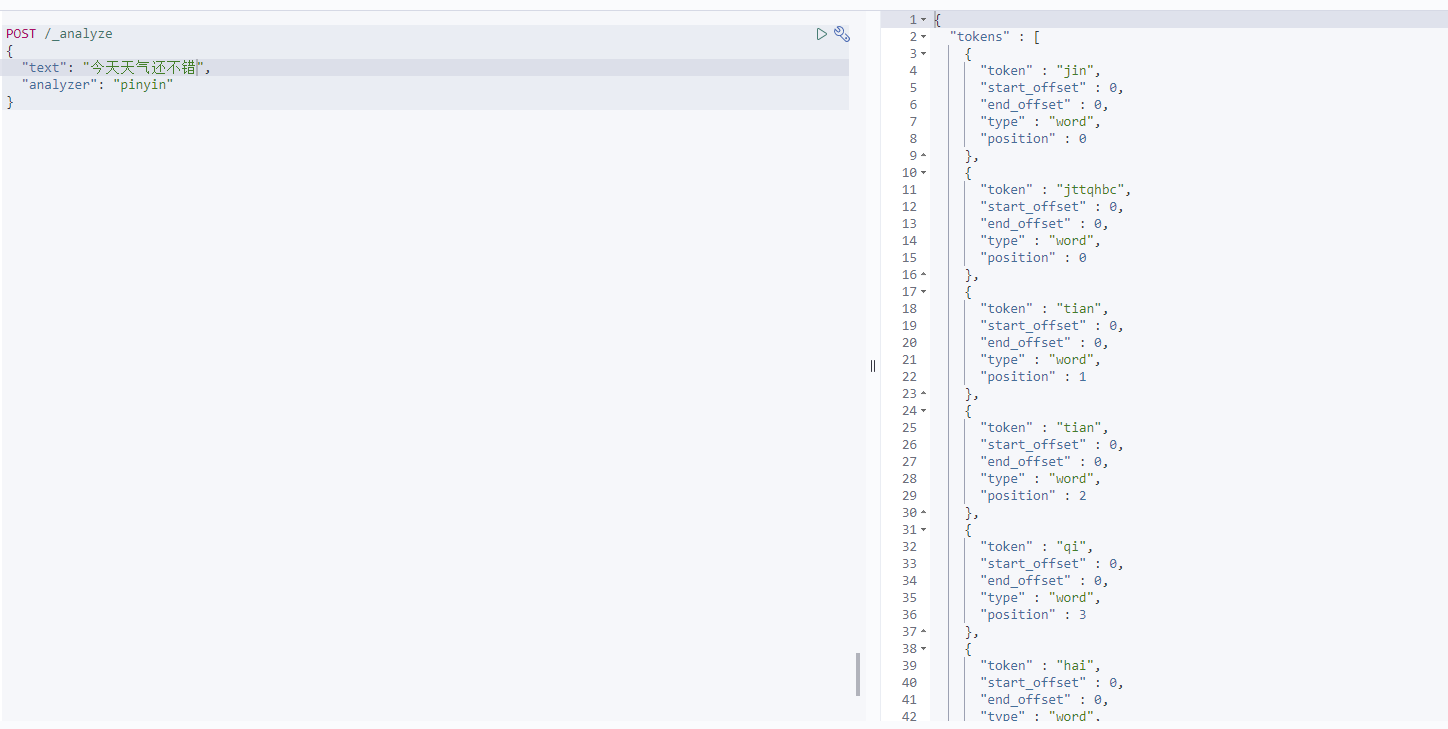
测试用法如下:
POST /_analyze
{
"text": "今天天气还不错",
"analyzer": "pinyin"
}
2
3
4
5
结果:
自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
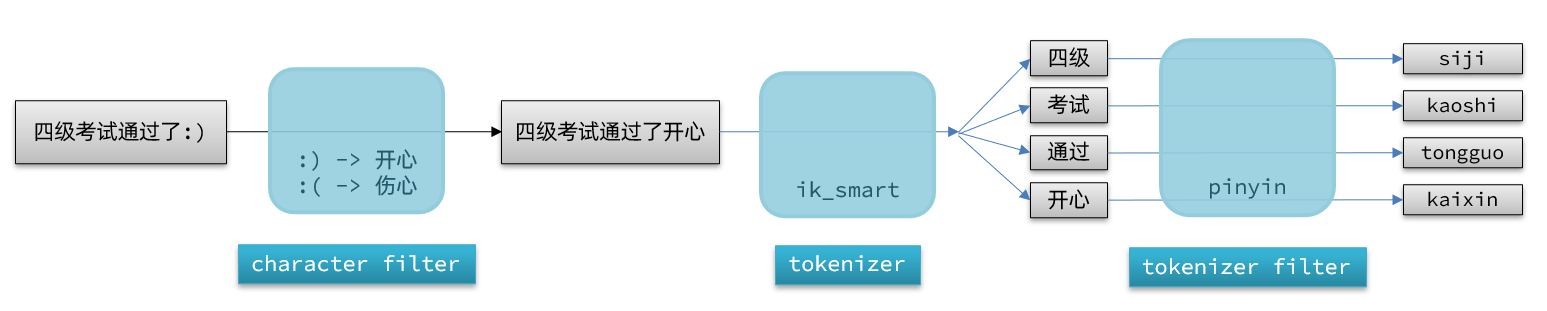
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
声明自定义分词器的语法如下:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
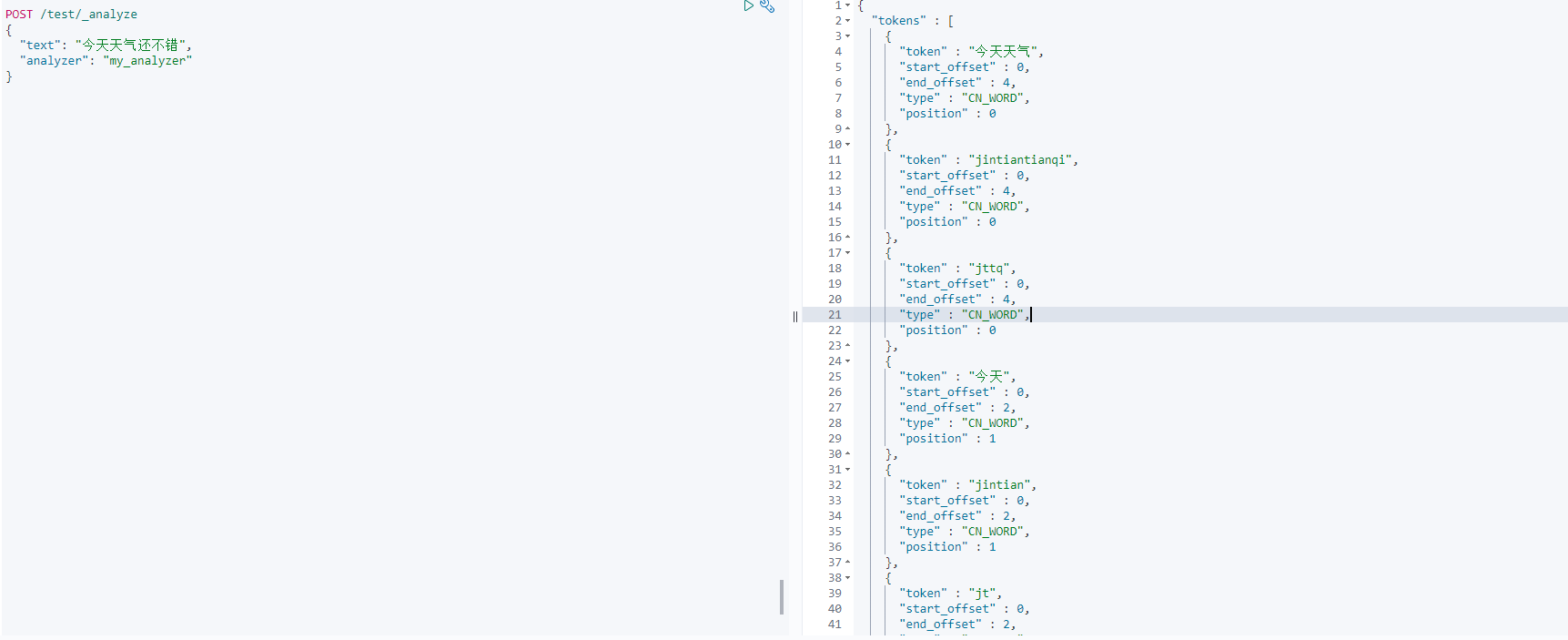
测试:
总结:
使用拼音分词器:
下载pinyin分词器
解压并放到elasticsearch的plugin目录
重启即可
自定义分词器:
创建索引库时,在settings中配置,可以包含三部分
character filter
tokenizer
filter
拼音分词器注意事项:
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
自动补全查询
elasticsearch提供了Completion Suggester (opens new window)查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。
比如,创建一个这样的索引库:
// 创建索引库
PUT /test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
然后插入下面的数据:
// 示例数据
POST test/_doc
{
"title": ["Sony", "XR-75X90J"]
}
POST test/_doc
{
"title": ["HUAWEI", "nova8"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
2
3
4
5
6
7
8
9
10
11
12
13
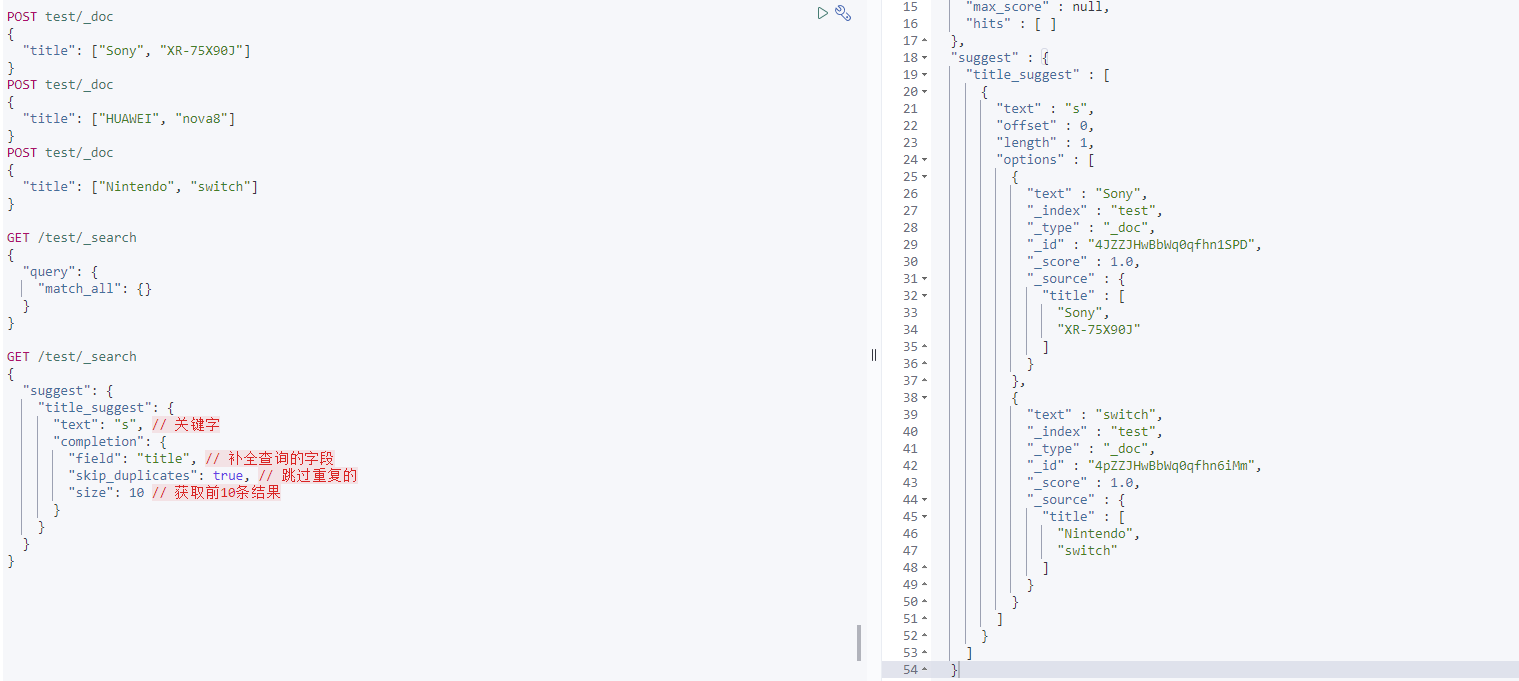
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
查询结果: