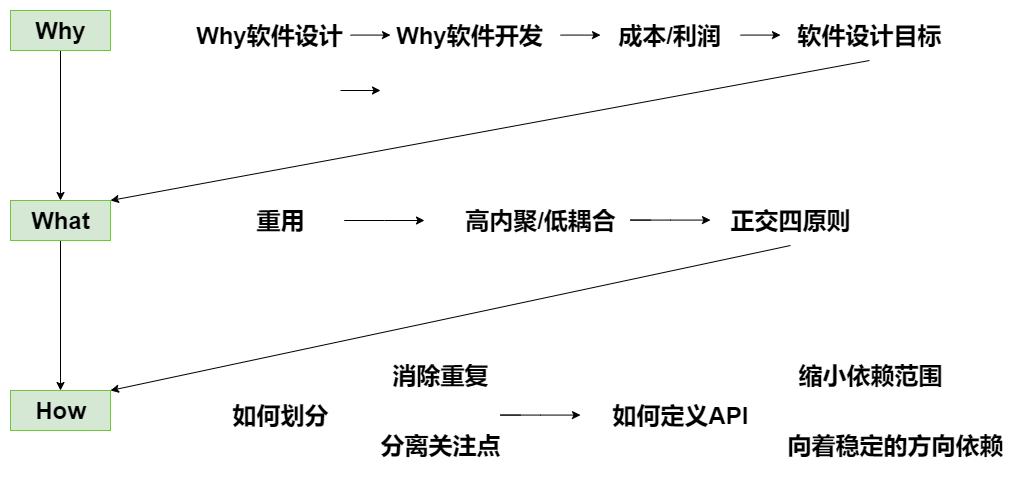
架构设计原则 - 高内聚、低耦合
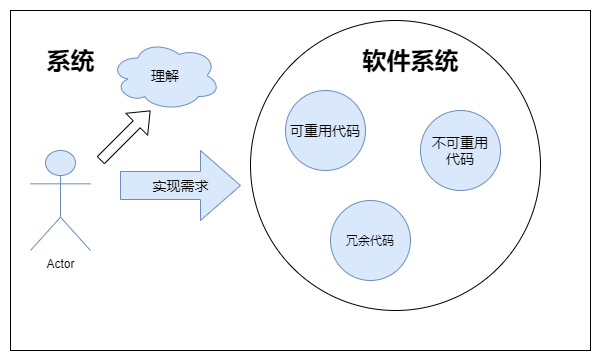
为什么要开发软件?
- 创造客户价值,满足客户需求
- 收益 - 成本 = 利润
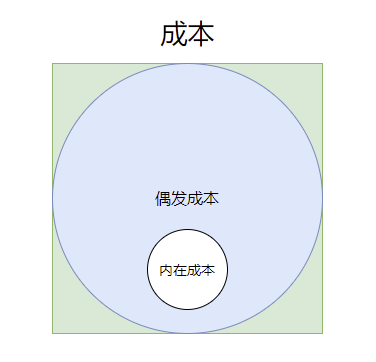
- 偶发成本
void say(char* p){
while(putchar(*(p+=*(p+1)-*p)))
}
- 内在成本
std::cout<<"Hello World"<<std::endl;
软件设计中的偶发成本
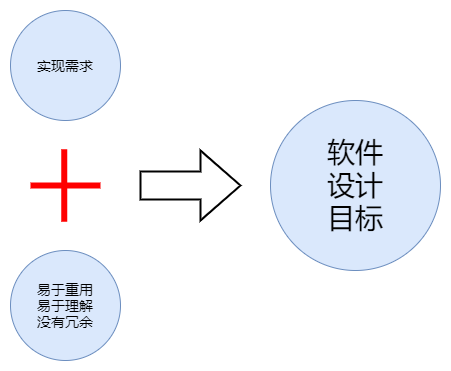
软件设计目标
重用
Don't reinvent the wheel, just realign it. -- Anthony J. D'Angelo
不要重新发明轮子,重新调整它。 -- Anthony J. D'Angelo
以 扫地机器人 为例
if(commond == "LEFT"){
execute_left()
}
else if(commond == "RIGHT"){
execute_right()
}
else if(commond == "FORWARD"){
execute_forward()
}
else if(commond == "BACKWARD"){
execute_backward()
}
else if(commond == "ROUND"){
execute_round()
}
else if(commond == "FORWARDN"){
execute_forwardn(n)
}
else if(commond == "BACKWARDN"){
execute_backwardn(n)
}
新需求:
SEQ:[LEFT,FORWARD,RIGHT,BACKWARD,ROUND,FORWARDN(2),RIGHT,BACKWARDN(1)]
REAPT:([FORWARD,RIGHT],4)
拷贝粘贴 ———— 容易引入重复轮子
例如:
- 学生按照身高从低到高排序
```cpp
struct Student
{
char name[MAX_NAME LEN];
unsigned int height;
};
void sort_students_by_height(Student students[], size_t num_of_students)
{
for (size_ty = 0; y < num_of_students - 1; y++)
{
for (size_tx = 1; x < num_of_students - y; x++)
{
if (students[x].height > students[x - 1].height)
swap(students[x], students[x - 1]);
}
}
}
* 老师按照年龄从小到大排序
```cpp
```cpp
struct Teacher
{
char name[MAX_NAME LEN];
unsigned int age;
};
void sort_teachers_by_age(Teacher teachers[] size tnum_of teachers)
{
for (size_ty = 0; y < num_of_teachers - 1; y++)
{
for (size_tx = 1; x < num_of_teachers - y; x++)
{
if (teachers[x].age > teachers[x - 1] age)
{
SWAP(teachers[x],teachers[x - 1]);
}
}
}
}
# 高内聚,低耦合
紧密关联的事物应该放在一起

* 只有紧密关联的事物才应该放在一起
* Do One Thing,Do it Well
高耦合性降低系统重用性

降低组件间的依赖关系

内聚和耦合的关系

# 正交四原则
## 消除重复
> 什么是重复代码
> 重复是不同的代码元素对同一知识进行了多次描述,无论描述方式是否一致。
### 重复代码示例
```cpp
//系统用户的最大连接数
const int max_num_of_user_connections = 1000;
#define MAX_USER_CONNECTIONS ((int)1000)
int get_max_num_of_user_connections(){
return 1000;
}
消除重复的例子
缓冲区拷贝算法
strcpy(buf,packet->src_address);
buf += strlen(packet->src_address) + 1;
strcpy(buf,packet->dest_address);
buf+=strlen(packet->dest_address)+1;
memcpy(buf,&packet->user_type,sizeof(packet->user_type))
buf+=sizeof(packet->user_type);
```cpp
size_t size;
void *p;
p = (void *)packet->src_address;
size = strlen(packet->src_address) + 1;
memcpy(buf, p, size);
buf += size;
p = (void *)packet->dest_address;
size = strlen(packet->dest_address) + 1;
memcpy(buf, p, size);
buf += size;
p = (void *)&packet->user_type;
size = sizeof(packet->usertype)
memcpy(buf, p, size);
buf += size;
定义宏消除
#define APPEND_TO_BUF(content,size) do{\
memcpy(buf(void*)content,size);\
buf+=size; \
} while(0)
APPEND_TO_BUF(packet->src_address,strlen(packet->src address)+1)
APPEND_TO_BUF(packet->src_address,strlen(packet->src_address)+1);
APPEND_TO_BUF(packet->user_type,sizeof(packet->user_type));
进一步消除
#define APPEND_STR_TO_BUF(str) APPEND_TO_BUF((str),strlen(str)+1)
#define APPEND_DATA_TO_BUF(data) APPEND_TO_BUF((data),sizeof(data))
///// /////////////
APPEND_STR_TO_BUF(packet->src_address);
APPEND_STR_TO_BUF(packet->src_address);
APPEND_DATA_TO_BUF(packet->user_type);

### 完全重复
//当函数F1和F2提供完全相同功能时 函数F1 → 功能S ← 函数F2 ↓ 函数F1 → 功能S
### 部分重复: 参数型重复
```cpp
void *fun1(void* buf,const Packet* packet)
{
strcpy(buf,packet->src_address);
buf += strlen(packet->src_address) + 1;
}
void *fun2(void* buf,const Packet* packet)
{
strcpy(buf,packet->dest_address);
buf += strlen(packet->dest_address) + 1;
}
解决方案: * 把差异的数据参数化
void *appendStrToBuf(void* buf,const char* str)
{
strcpy(buf,str);
return (void*)((char*)buf + strlen(str) + 1);
}
void *fun1(void* buf,const Packet* packet)
{
return appendStrToBuf(buf,packet->src_address);
}
void *fun2(void* buf,const Packet* packet)
{
return appendStrToBuf(buf,packet->dest_address);
}
调用型重复
如果两个函数的重复部分完全相同,可以将重复部分提取成函数F,然后原函数各自对F进行直接调用
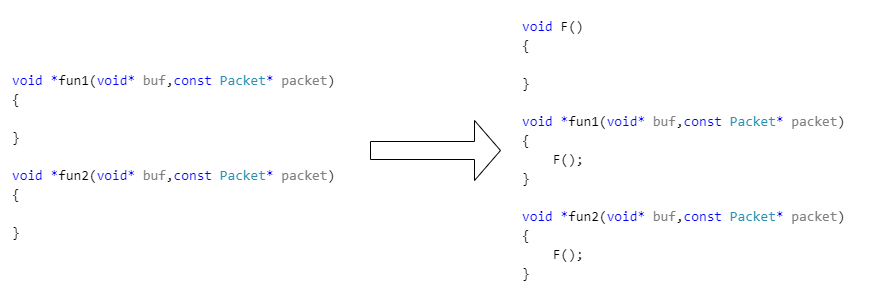
回调型重复
如果两个函数的重复部分完全相同,可以将重复部分提取成函数F,将差异的部分形成原型相同的两个函数S1和S2,然后通过F分别对S1和S2调用

重复产生的常见原因
- 低成本(代码拷贝粘贴)
- 对于变化的恐惧(另起炉灶)
- 不易识别(代码混乱)
- 价值导向(不重视内部质量)
- 认知差异(不具备敏锐的洞察力)
重复和重用
- 消除重复的过程就是提高一个系统可重用性的过程
- 提高系统的可重用性,也就降低了未来产生重复的可能性
- DRY(Don't Repeat Yourself)
- OAOO(Once And Only Once)
- SRP(Singular Responsilbility Principle)
分离关注点
所谓关注点,从行为角度来看,是一个个功能,即在某个层面,你可以清晰地描述它在做一件什么具体的事情。
关注点的例子
- 学生按照身高从低到高排序
- 利用冒泡排序实现
```cpp
struct Student
{
char name[MAX_NAME LEN];
unsigned int height;
};
void sort_students_by_height(Student students[], size_t num_of_students)
{
for (size_ty = 0; y < num_of_students - 1; y++)
{
for (size_tx = 1; x < num_of_students - y; x++)
{
if (students[x].height > students[x - 1].height)
swap(students[x], students[x - 1]);
}
}
}
* 老师按照年龄从小到大排序
* 差异
* 排序的对象为老师
* 排序的依据为年龄
```cpp
```cpp
struct Teacher
{
char name[MAX_NAME LEN];
unsigned int age;
};
void sort_teachers_by_age(Teacher teachers[] size tnum_of teachers)
{
for (size_ty = 0; y < num_of_teachers - 1; y++)
{
for (size_tx = 1; x < num_of_teachers - y; x++)
{
if (teachers[x].age > teachers[x - 1] age)
{
SWAP(teachers[x],teachers[x - 1]);
}
}
}
}
从上述例子,可以看出关注点有三个:
* 冒泡排序算法(重复部分)
* 排序的对象(差异部分)
* 排序对象的对比规则(if的判断语句)
分离关注点


## 缩小依赖范围
### 如何缩小依赖范围
依赖点应该包含尽可能少的知识。

依赖点也应该高内聚,而不应该强迫依赖方依赖它不需要的东西
尽量减少依赖点的数量
```cpp
Color color = city.streets["Nanjing Avenue"].houses[109].color;
可以通过CityMapFacade去封装City,Street,Houses
Color color = colorOfHouseInStreet("Nanjing Avenue",109);
向着稳定的方向依赖
依赖点越稳定,依赖点受依赖点变化影响的概率越低
如何使得依赖更趋于稳定
站在需求的角度,而不是实现的角度定义依赖点(API),会让API更加稳定
需求是不断变化,必须对需求进行抽象和建模,找出其中本质的东西,才能使API更加稳定
- DDD和领域特定语言
总结