muduo - Buffer类的设计
muduo的Buffer设计
Buffer类的设计,即输入输出缓冲区的设计,其中buffer 指一般的应用层缓冲区、缓冲技术。
muduo的IO模型
Unix/Linux 上的五种 IO 模型:阻塞(blocking)、非阻塞(non-blocking)、IO 复用(IO multiplexing)、信号驱动(signal-driven)、异步(asynchronous)。这些都是单线程下的 IO 模型。
在这个多核时代,线程是不可避免的。那么服务端网络编程该如何选择线程模型呢?——> one loop per thread is usually a good model。如果采用 one loop per thread 的模型,多线程服务端编程的问题就简化为如何设计一个高效且易于使用的 event loop,然后每个线程 run 一个 event loop 就行了。
event loop 是 non-blocking 网络编程的核心,在现实生活中,non-blocking 几乎总是和 IO-multiplexing 一起使用,原因有两点:
- 没有人真的会用轮询 (busy-pooling) 来检查某个 non-blocking IO 操作是否完成,这样太浪费 CPU cycles。
- IO-multiplex 一般不能和 blocking IO 用在一起,因为 blocking IO 中 read()/write()/accept()/connect() 都有可能阻塞当前线程,这样线程就没办法处理其他 socket 上的 IO 事件了。
## 为什么 non-blocking 网络编程中应用层 buffer 是必须的?
Non-blocking IO 的核心思想是避免阻塞在 read() 或 write() 或其他 IO 系统调用上,这样可以最大限度地复用 thread-of-control,让一个线程能服务于多个 socket 连接。IO 线程只能阻塞在 IO-multiplexing 函数上,如 select()/poll()/epoll_wait()。这样一来,应用层的缓冲是必须的,每个 TCP socket 都要有 stateful 的 input buffer 和 output buffer。
output buffer 用于存储待发送的数据,应用程序只管通过write操作往output buffer 里写数据,网络库负责send这些数据;网络库在处理“socket 可读”事件的时候,必须一次性把 socket 里的数据读完,放入input buffer。那么网络库必然要应对“数据不完整”的情况,收到的数据先放到 input buffer 里,等构成一条完整的消息再通知程序的业务逻辑。这通常是 codec 的职责。
## Buffer的功能需求
Muduo Buffer 的设计要点:
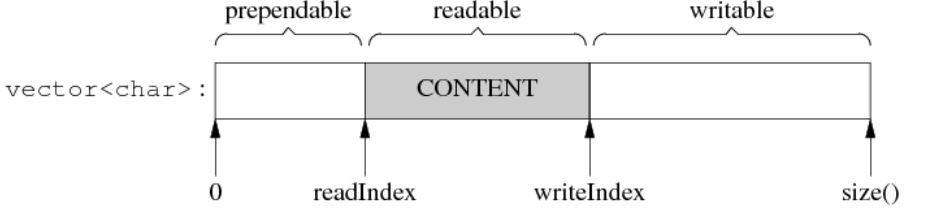
- 对外表现为一块连续的内存(char* p, int len),以方便客户代码的编写。
- 其 size() 可以自动增长,以适应不同大小的消息。它不是一个 fixed size array (即 char buf[8192])。
- 内部以 std::vector
来保存数据,并提供相应的访问函数。
Buffer 其实像是一个 queue,从末尾写入数据,从头部读出数据。
谁会用 Buffer?谁写谁读?根据前文分析,TcpConnection 会有两个 Buffer 成员,input buffer 与 output buffer。
- input buffer,TcpConnection 会从 socket 读取数据,然后写入 input buffer(其实这一步是用 Buffer::readFd() 完成的);客户代码从 input buffer 读取数据。
- output buffer,客户代码会把数据写入 output buffer(其实这一步是用 TcpConnection::send() 完成的);TcpConnection 从 output buffer 读取数据并写入 socket。
其实,input 和 output 是针对客户代码而言,客户代码从 input 读,往 output 写。TcpConnection 的读写正好相反。
Buffer 的数据结构
muduo的buffer的定义如下,其内部是 一个 std::vector
class Buffer : public muduo::copyable
{
public:
static const size_t kCheapPrepend = 8;
static const size_t kInitialSize = 1024;
explicit Buffer(size_t initialSize = kInitialSize)
: buffer_(kCheapPrepend + initialSize),
readerIndex_(kCheapPrepend),
writerIndex_(kCheapPrepend)
{
assert(readableBytes() == 0);
assert(writableBytes() == initialSize);
assert(prependableBytes() == kCheapPrepend);
}
void swap(Buffer& rhs)
{
buffer_.swap(rhs.buffer_);
std::swap(readerIndex_, rhs.readerIndex_);
std::swap(writerIndex_, rhs.writerIndex_);
}
size_t readableBytes() const { return writerIndex_ - readerIndex_; }
size_t writableBytes() const { return buffer_.size() - writerIndex_; }
size_t prependableBytes() const { return readerIndex_; }
void retrieve(size_t len)
{
assert(len <= readableBytes());
if (len < readableBytes())
{
readerIndex_ += len;
}
else
{
retrieveAll();
}
}
void retrieveAll()
{
readerIndex_ = kCheapPrepend;
writerIndex_ = kCheapPrepend;
}
ssize_t readFd(int fd, int* savedErrno);
private:
std::vector<char> buffer_;
size_t readerIndex_;
size_t writerIndex_;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
结构示意图如下:
Buffer的操作特点:
自动增长:Muduo Buffer 的 size() 是自适应的,它一开始的初始值是 1k,如果程序里边经常收发 10k 的数据,那么用几次之后它的 size() 会自动增长到 10k,然后就保持不变。这样一方面避免浪费内存(有的程序可能只需要 4k 的缓冲),另一方面避免反复分配内存。当然,客户代码可以手动 shrink() buffer size()。使用 vector 的另一个好处是它的 capcity() 机制减少了内存分配的次数。
内部腾挪:有时候,经过若干次读写,readIndex 移到了比较靠后的位置,留下了巨大的 prependable 空间。muduo Buffer 在这种情况下不会重新分配内存,而是先把已有的数据移到前面去,腾出 writable 空间。
前方添加(prepend):提供 prependable 空间,让程序能以很低的代价在数据前面添加几个字节。例如,程序以固定的4个字节表示消息的长度,我要序列化一个消息,但是不知道它有多长,那么我可以一直 append() 直到序列化完成,然后再在序列化数据的前面添加消息的长度。
Buffer::readFd()的特殊设计:
问题:在非阻塞网络编程中,如何设计并使用缓冲区?一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。另一方面,我们系统减少内存占用。如果有 10k 个连接,每个连接一建立就分配 64k 的读缓冲的话,将占用 640M 内存,而大多数时候这些缓冲区的使用率很低。muduo 用 readv 结合栈上空间巧妙地解决了这个问题。
具体做法是,在栈上准备一个 65536 字节的 extrabuf,然后利用 readv() 来读取数据,iovec 有两块,第一块指向 muduo Buffer 中的 writable 字节,另一块指向栈上的 extrabuf。这样如果读入的数据不多,那么全部都读到 Buffer 中去了;如果长度超过 Buffer 的 writable 字节数,就会读到栈上的 extrabuf里,然后程序再把 extrabuf里的数据 append 到 Buffer 中。
ssize_t Buffer::readFd(int fd, int* savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin()+writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
// when there is enough space in this buffer, don't read into extrabuf.
// when extrabuf is used, we read 128k-1 bytes at most.
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0)
{
*savedErrno = errno;
}
else if (implicit_cast<size_t>(n) <= writable)
{
writerIndex_ += n;
}
else
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
return n;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
补充:
#include <sys/uio.h>
struct iovec {
ptr_t iov_base; /* Starting address */
size_t iov_len; /* Length in bytes */
};
2
3
4
5
6
struct iovec定义了一个向量元素。通常,这个结构用作一个多元素的数组。对于每一个传输的元素,指针成员iov_base指向一个缓冲区,这个缓冲区是存放的是readv所接收的数据或是writev将要发送的数据。成员iov_len在各种情况下分别确定了接收的最大长度以及实际写入的长度。
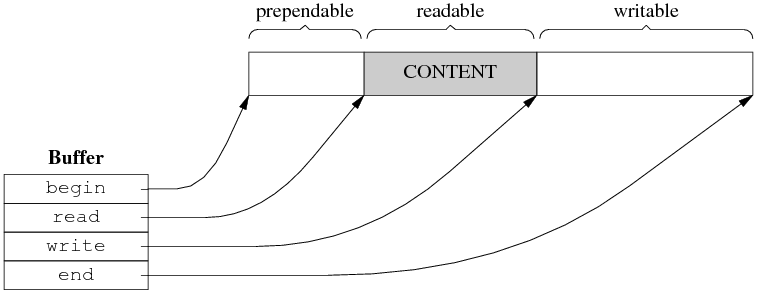
其他Buffer的设计方案
类似STL做法的指针设计方案,以 4 个指针为 buffer 的成员:
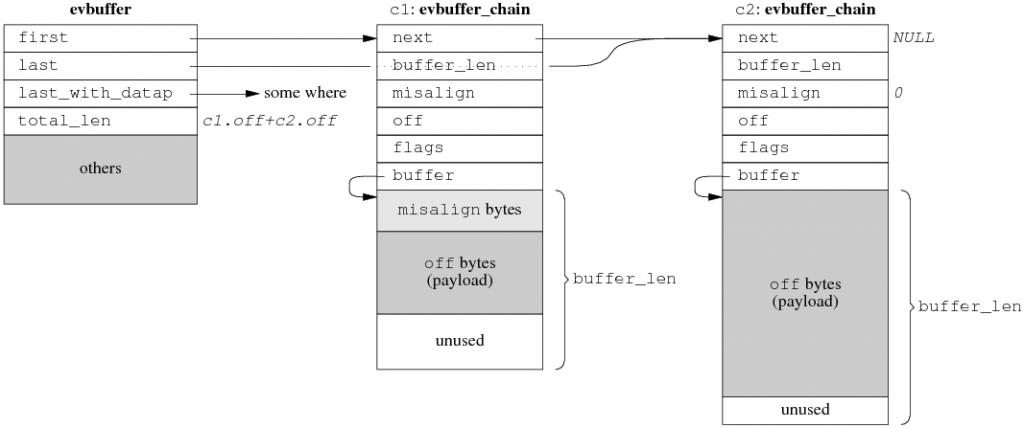
Zero copy 设计方案:如果对性能有极高的要求,受不了 copy() 与 resize(),那么可以考虑实现分段连续的 zero copy buffer 再配合 gather scatter IO,这是 libevent 2.0.x 的设计方案。TCPv2介绍的 BSD TCP/IP 实现中的 mbuf 也是类似的方案,Linux 的 sk_buff 估计也差不多。细节有出入,但基本思路都是不要求数据在内存中连续,而是用链表把数据块链接到一起。
利用Buffer读写数据
在TcpConnection中添加inputBuffer_成员变量,在TcpConnection::handleRead中,使用Buffer来读取数据:
void TcpConnection::handleRead(Timestamp receiveTime)
{
loop_->assertInLoopThread();
int savedErrno = 0;
ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno);
......
}
2
3
4
5
6
7
发送数据比接收数据更难,因为发送数据是主动的,接收数据时被动的。muduo采用level trigger,当socket可写时,会不停的触发socket可写的事件。因此,我们只在需要时才关注writeable事件,否则就会造成busy loop。所以在Channel中需要添加:
void enableWriting() { events_ |= kWriteEvent; update(); } //添加writeable事件
void disableWriting() { events_ &= ~kWriteEvent; update(); } //移除writeable事件
bool isWriting() const { return events_ & kWriteEvent; } //判断是否写状态
2
3
通过上述三个函数打开和关闭写通道,并且获取当前状态,可以很好的控制防止busy loop。另外,需要注意的就是打开关闭通道的时机了。
举个例子来说明TcpConnection发送数据的过程。
void onConnection(const muduo::TcpConnectionPtr& conn)
{
if (conn->connected())
{
printf("onConnection(): new connection [%s] from %s\n",
conn->name().c_str(),
conn->peerAddress().toHostPort().c_str());
//发送数据
conn->send(message1);
conn->send(message2);
conn->shutdown();
}
else
{
printf("onConnection(): connection [%s] is down\n",
conn->name().c_str());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在onConnection回调中,服务器向socket写入两次数据,客户端将收到数据,下面是TcpConnection::send的实现:
void TcpConnection::send(const StringPiece& message)
{
if (state_ == kConnected)
{
if (loop_->isInLoopThread())
{
sendInLoop(message);//本线程直接调用
}
else
{
//用runInLoop进行跨线程调用
void (TcpConnection::*fp)(const StringPiece& message) = &TcpConnection::sendInLoop;
loop_->runInLoop(
std::bind(fp,
this, // FIXME
message.as_string()));
//std::forward<string>(message)));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
再来看TcpConnection::sendInLoop的具体实现,sendInLoop会尝试直接发送数据,如果一次发送完毕就会直接调用writeCompleteCallback_;如果只是发送了部分数据,则把剩余的数据写入outputBuffer_,并且打开写通道enableWriting(),开始关注writeable事件,以后在handleWrite中发送剩余的数据。如果当前outputBuffer_已经有待发送的数据,就不尝试直接发送数据了,先处理outbuffer不然会造成数据乱序。
void TcpConnection::sendInLoop(const void* data, size_t len)
{
loop_->assertInLoopThread();
ssize_t nwrote = 0;
size_t remaining = len;
bool faultError = false;
if (state_ == kDisconnected)
{
LOG_WARN << "disconnected, give up writing";
return;
}
// if no thing in output queue, try writing directly
if (!channel_->isWriting() && outputBuffer_.readableBytes() == 0)
{
nwrote = sockets::write(channel_->fd(), data, len);
if (nwrote >= 0)
{
remaining = len - nwrote;
if (remaining == 0 && writeCompleteCallback_)
{
loop_->queueInLoop(std::bind(writeCompleteCallback_, shared_from_this()));
}
}
else // nwrote < 0
{
nwrote = 0;
if (errno != EWOULDBLOCK)
{
LOG_SYSERR << "TcpConnection::sendInLoop";
if (errno == EPIPE || errno == ECONNRESET) // FIXME: any others?
{
faultError = true;
}
}
}
}
assert(remaining <= len);
if (!faultError && remaining > 0)
{
size_t oldLen = outputBuffer_.readableBytes();
if (oldLen + remaining >= highWaterMark_
&& oldLen < highWaterMark_
&& highWaterMarkCallback_)
{
loop_->queueInLoop(std::bind(highWaterMarkCallback_, shared_from_this(), oldLen + remaining));
}
outputBuffer_.append(static_cast<const char*>(data)+nwrote, remaining);
if (!channel_->isWriting())
{
channel_->enableWriting();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
上述代码中可以看到有关于writeCompleteCallback和highWaterMarkCallback两个回调函数的使用,这里来介绍一下这两个函数。
现在考虑一个代理服务器有C和S两个链接,S向C发送数据,经由代理服务器转发,现在S的数据发送的很快,但是C的接受速率却较慢,如果本代理服务器不加以限制,那S到来的数据迟早会撑爆这C连接的发送缓冲区,解决的办法就是当C的发送缓冲中堆积数据达到了某个标志的时候,调用highWaterMarkCallback去让S的连接停止接受数据,等到C发送缓冲的数据被发送完了,调用writeCompleteCallback再开始接受S连接的数据。这样就确保了数据不会丢失,缓冲不会被撑爆。
再看TcpConnection::handleWrite的函数实现:
void TcpConnection::handleWrite()
{
loop_->assertInLoopThread();
if (channel_->isWriting())
{
ssize_t n = sockets::write(channel_->fd(),
outputBuffer_.peek(),
outputBuffer_.readableBytes());
if (n > 0)
{
outputBuffer_.retrieve(n);
if (outputBuffer_.readableBytes() == 0)
{
channel_->disableWriting();
if (writeCompleteCallback_)
{
loop_->queueInLoop(std::bind(writeCompleteCallback_, shared_from_this()));
}
if (state_ == kDisconnecting)
{
shutdownInLoop();
}
}
}
else
{
LOG_SYSERR << "TcpConnection::handleWrite";
}
}
else
{
LOG_TRACE << "Connection fd = " << channel_->fd()
<< " is down, no more writing";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
一个改进的措施:TcpConnection的输出缓冲区不必是连续的,handleWrite可以用writev来发送多块数据,这样或许能减少内存拷贝的次数,略微提高性能。
← 第八章:配接器 muduo - 设计与实现 →