Dubbo - 框架学习
参考
概述
Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案,涵盖 Java、Golang 等多种语言 SDK 实现。
Dubbo3 定义为面向云原生的下一代 RPC 服务框架。3.0 基于 Dubbo 2.x 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全性等几大方向上进行了全面升级。
发展演变过程
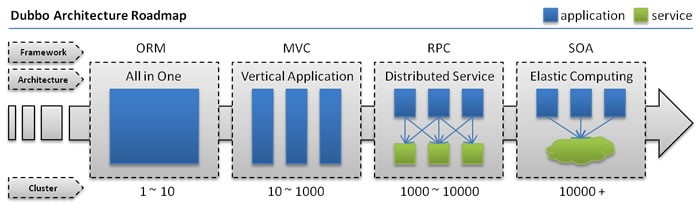
单一应用架构
- 当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
- 特点:适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
- 缺点:1、性能扩展比较难 ;2、协同开发问题;不利于升级维护
- 关键:简化增删改查工作量的数据访问框架(ORM)。
- 当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
垂直应用架构
- 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
- 特点:通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
- 缺点:公用模块无法重复利用,开发性的浪费
- 关键:加速前端页面开发的Web框架(MVC)。
- 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
分布式服务架构
- 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
- 关键:提高业务复用及整合的分布式服务框架(RPC)。
流动计算架构
- 当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
- 关键:提高机器利用率的资源调度和治理中心(SOA)。
总体架构
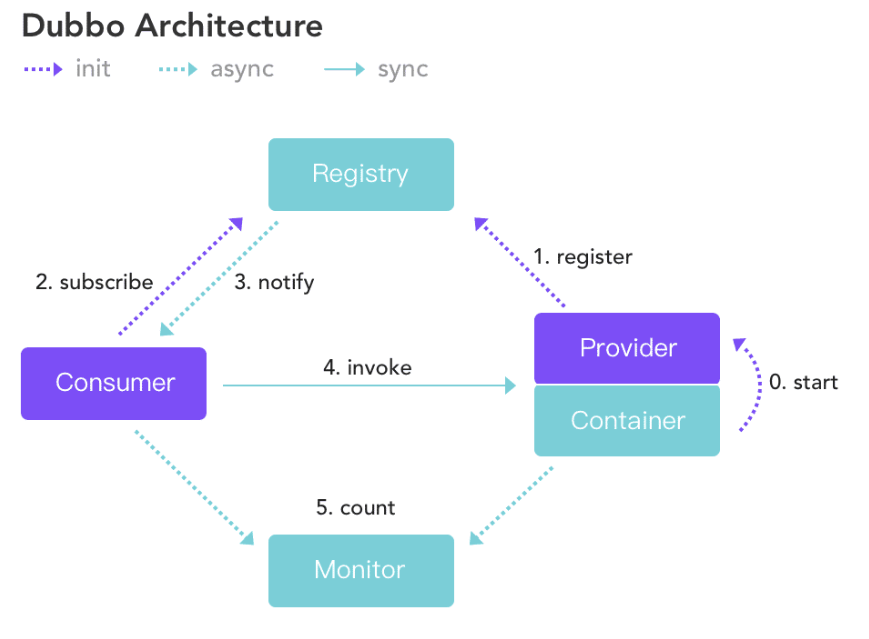
- 服务提供者(Provider):暴露服务的服务提供方。
- 服务消费者(Consumer): 调用远程服务的服务消费方。
- 注册中心(Registry):服务注册与发现的注册中心。
- 监控中心(Monitor):统计服务的调用次数和调用时间的监控中心。
- Container:服务运行容器
调用关系说明
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 架构具有以下几个特点,分别是连通性、健壮性、伸缩性、以及向未来架构的升级性。
连通性
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
- 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
健壮性
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
伸缩性
- 注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
- 服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
原理
RPC原理
RPC原理参见
netty通信原理
Netty是一个异步事件驱动的网络应用程序框架, 用于快速开发可维护的高性能协议服务器和客户端。它极大地简化并简化了TCP和UDP套接字服务器等网络编程。
核心是NIO (Non-Blocking IO)
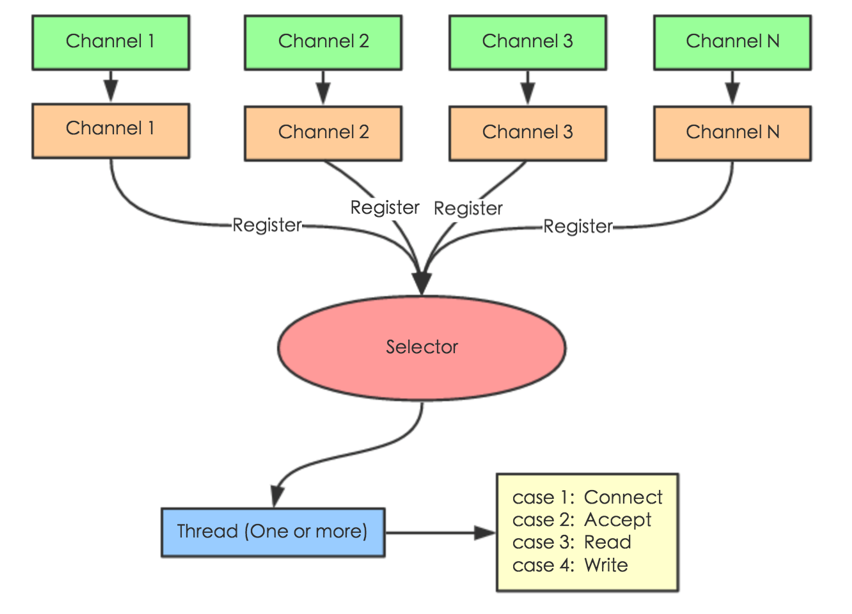
- Selector 一般称 为选择器 ,也可以翻译为 多路复用器,
- Connect(连接就绪)、Accept(接受就绪)、Read(读就绪)、Write(写就绪)
Netty基本原理:
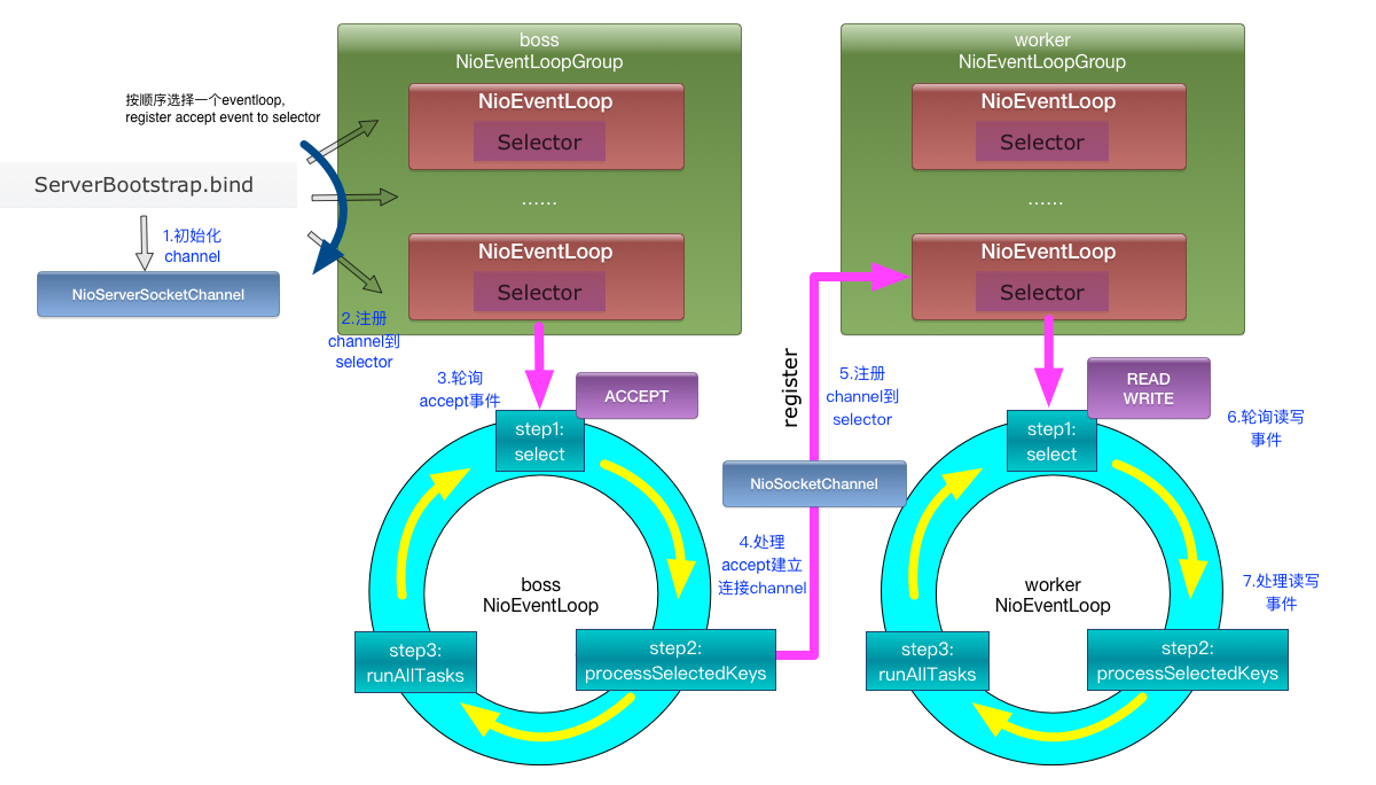
与C++的epoll
代码架构
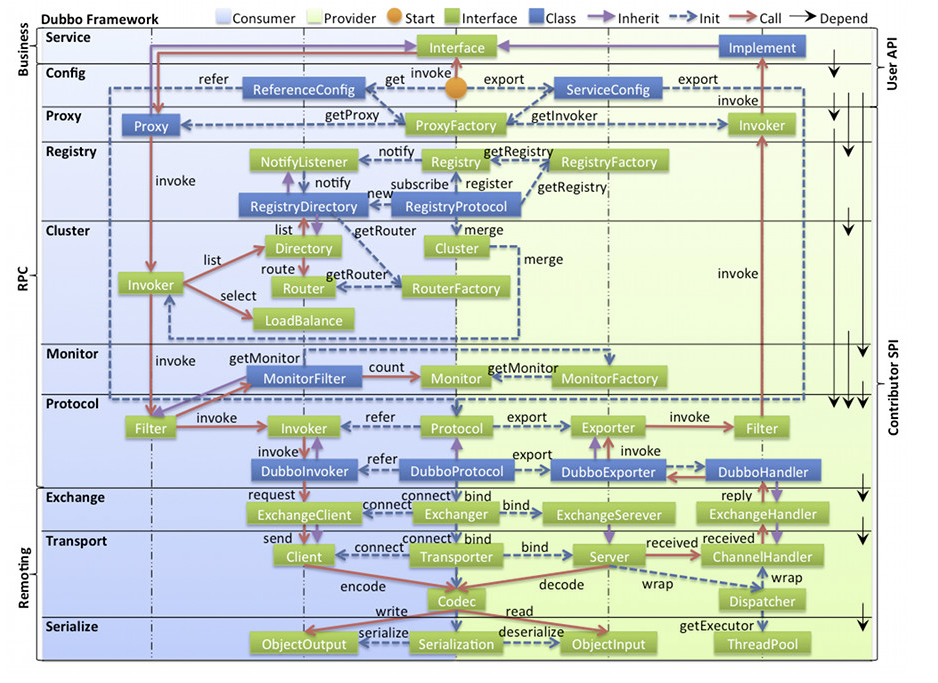
各层说明
- Config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
- Proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
- Registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
- Cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
- Monitor 监控层:RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
- Protocol 远程调用层:封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
- Exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
- Transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
- Serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
调用链
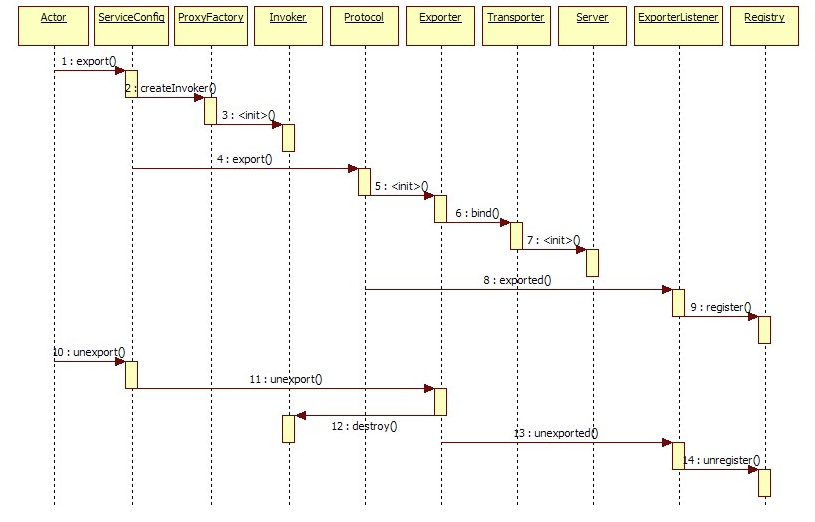
服务提供者暴露服务
展开总设计图右边服务提供方暴露服务的蓝色初始化链,时序图如下:
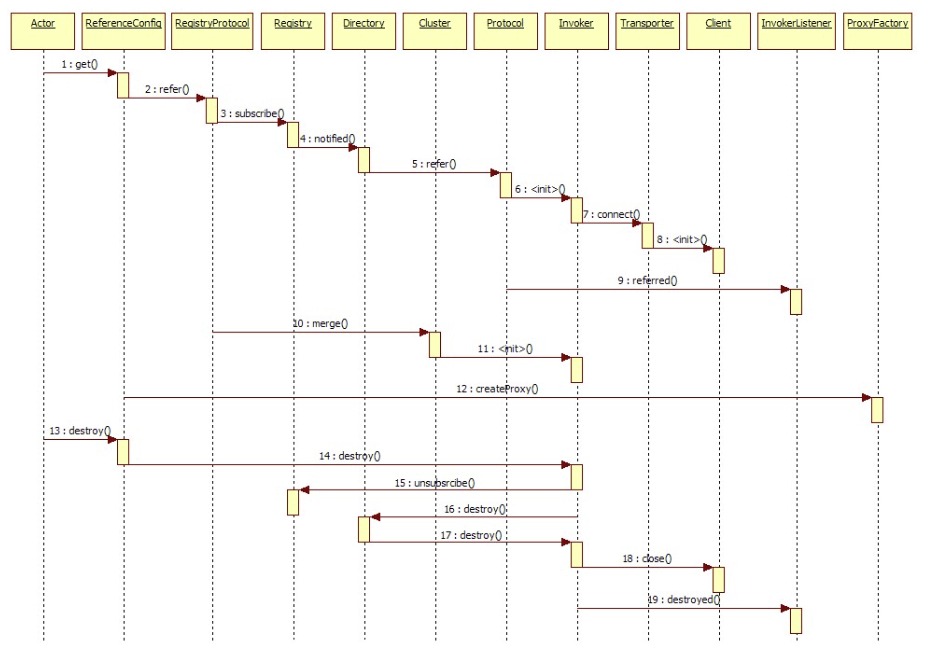
服务消费者引用服务
展开总设计图左边服务消费方引用服务的绿色初始化链,时序图如下:
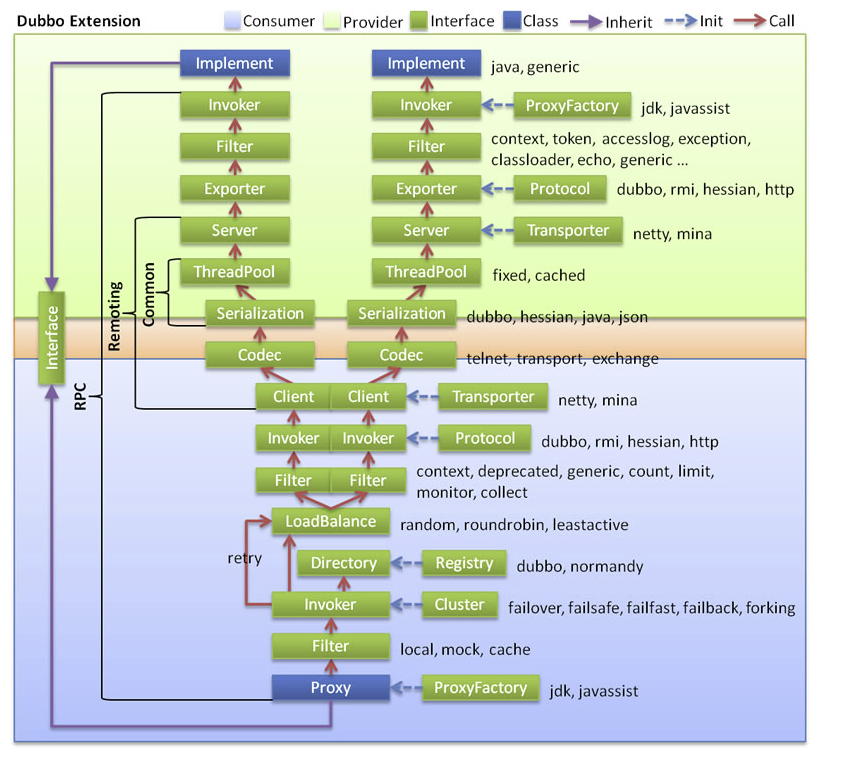
特性
启动时检查
在启动时检查依赖的服务是否可用(但是,实际上注册中心中断不会失败,消费者会有本地缓存对应的服务提供者地址信息)
dubbo.reference.com.foo.BarService.check=false
dubbo.consumer.check=false
dubbo.registry.check=false
2
3
重试次数
失败自动切换,当出现失败,重试其它服务器,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
超时时间
由于网络或服务端不可靠,会导致调用出现一种不确定的中间状态(超时)。为了避免超时导致客户端资源(线程)挂起耗尽,必须设置超时时间。
配置原则:
- 方法级配置别优于接口级别,即小Scope优先 。
- Consumer端配置 优于 Provider配置 优于 全局配置。
版本号
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
高可用
zookeeper宕机与dubbo直连
现象:zookeeper注册中心宕机,还可以消费dubbo暴露的服务。(服务提供者和服务消费者仍能通过本地缓存通讯)
高可用:通过设计,减少系统不能提供服务的时间。
负载均衡配置
- Random:随机,按权重设置随机概率。
- RoundRobin:轮循,按公约后的权重设置轮循比率。
- LeastActive:最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- ConsistentHash:一致性 Hash,相同参数的请求总是发到同一提供者。
- shortestresponse :分别记录每次调用服务提供者的响应时间,取响应时间最短的提供者。
整合hystrix,服务熔断与降级处理
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。
其中:
- mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。
- mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
集群容错:
- Failfast Cluster:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster:失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
- Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
实践
可以参考官网示例 dubbo-samples (opens new window)
运行 dubbo-samples/1-basic/dubbo-samples-spring-boot 里的例子即可。