RocketMQ - 零拷贝和文件预热
虚拟内存
为了防止进程间相互修改对方的内存,操作系统有一套内存管理机制,通过虚拟内存,让每个进程以为自己独占完整的物理内存。
当进程实际上去访问虚拟内存的某个地址时,CPU会根据页表将这个虚拟地址转到真正的物理地址上去访问。

页表:一个映射表,记录某个虚拟地址映射到物理地址,由操作系统来维护,每个进程都会有自己的页表。
具体映射到哪个物理地址,以及实际物理内存的访问都由操作系统来把控,每个进程自己无法控制。这样进程间才能互不干扰地运行。
内核态和用户态
操作系统将虚拟内存划分成:内存空间和用户空间两个部分,内核模块运行在内核空间,用户模块运行在用户空间。
运行在内核空间的进程处于内核态,运行在用户空间的进程处于用户态。
正常运行时,进程处于用户态,当要进行系统调用(例如访问文件内容),处于用户态的进程需要切换成内核态,才能进行系统调用。
用户进程无法直接访问内核空间,只有内核态的系统调用才能访问所有的内存空间、I/O设备等。
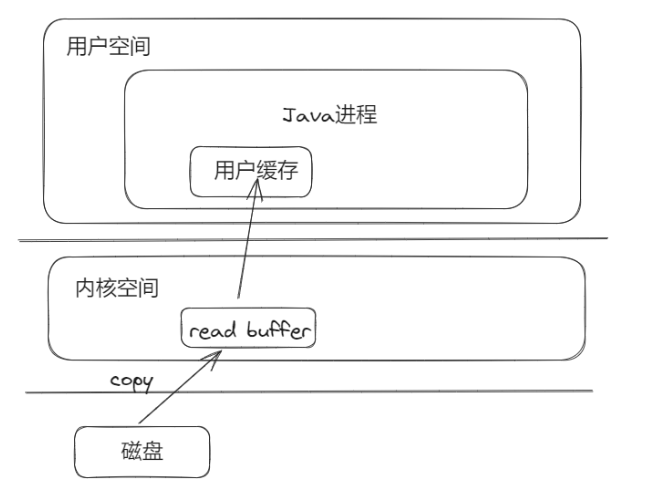
例如 JAVA 读取文件内容需要经过以下几个步骤:
1.程序通过read系统调用,进入内核态,读取磁盘上某个文件的某块数据 2. 从磁盘加载数据到内核空间的读缓存中(如已存在则不需要拷贝) 3.从读缓存拷贝到用户空间 4.切涣回用户态 5.应用程序获取这块数据
例如 JAVA 发送文件到网络需要经过以下几个步骤:
1.程序通过write系统调用,进入内核态 2.将用户空间中的数据内容拷贝至内核中的socket buffer(网络缓冲区)中 3.从socket buffer再拷贝至网卡中发送 4.切换回用户态,发送完毕
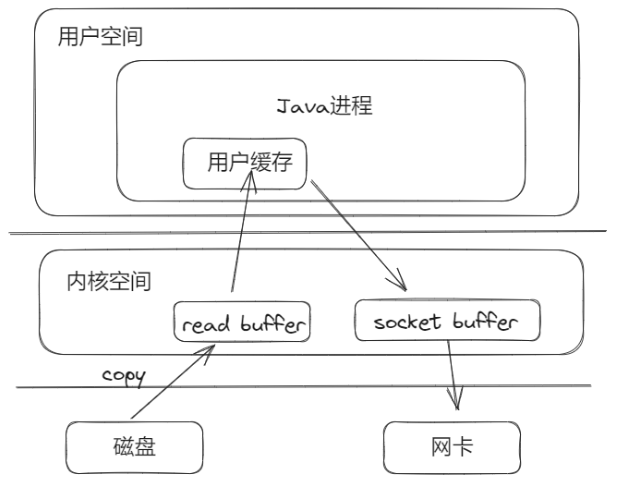
从上图来看整体流程,有很多地方的拷贝很多余,但是这是内核的实现,文件系统的实现就是用了缓存I/O,就是在内核缓存了一道,目的是为了其他进程读的时候,发现磁盘数据已经存在内核缓存中了,那可以直接缓存返回,不需要读磁盘。
且写的时候,写到内核缓存中,可以延迟批量将脏页(内存缓存中对应磁盘内容已经被修改的数据页叫脏页)刷盘,对性能更好。
零拷贝不是说完全不需要拷贝,像从磁盘拷贝到内存这种肯定是需要拷贝的,只是减少拷贝次数。比如,如果程序仅仅是读取磁盘文件,然后不需要修改直接发送至网络,那么完全不需要拷贝到用户空间来。
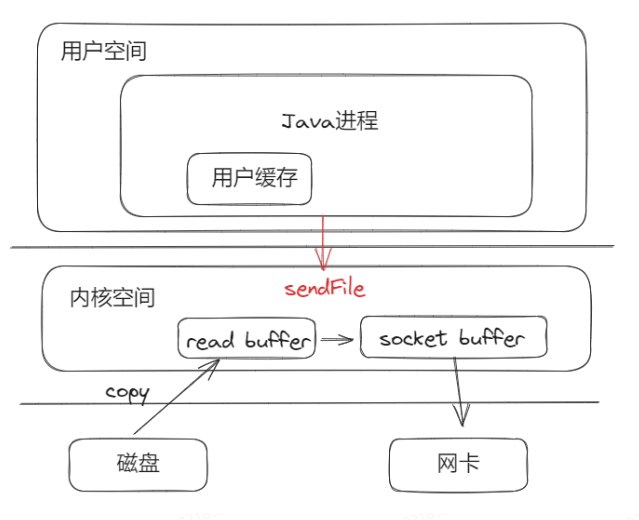
如上图所示,直接从磁盘到内核空间,再到socket buffer,再到网卡,这样就少了到用户空间的拷贝,这个系统调用是linux提供的sendfile的功能,这就是零拷贝。
后续又引入了DMA的gather操作,也就是文件的数据不需要再拷贝到scoket buffer,仅需将文件描述符(fd),以及数据长度拷贝到socket buffer中,实际数据通过网卡DMA收集功能直接从read buffer拷贝,这又减少了一次拷贝。
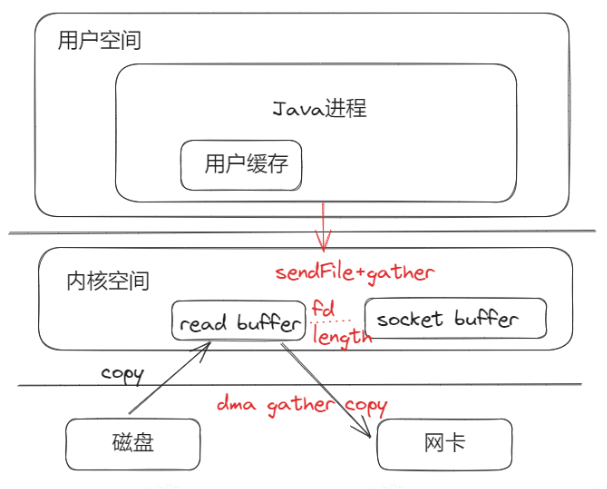
以上的零拷贝适合不需要对磁盘文件内容做解折等作的汤景,因为都不拷贝到用户空间,无法解析其内容。
使用mmap,可以让用户空间读取到内核缓存区的内容,通过将磁盘文件对应的内核缓冲区和用户的缓存映射成一个地址,后续就可以通过指针访问和操作这块物理内存的数据。

RocketMQ mmap + write
RocketMQ对应的commitlog、consumeQueue等文件都用到了mmap。
commitlog采用的是mmap,消息的写入是直接写到了操作系统的page cache即页缓存中,这时并没有将消息写入到磁盘上,默认是等操作系统异步统一将脏页刷到磁盘中才是落盘了,因此称为异步刷盘,此时如果断电,那么内存中的消息就丢了。
RocketMQ也支持同步刷盘,即写入到page cache立刻行刷盘,但相比异步刷盘而言性能会低一些(每次都要刷盘),不过能保证消息不丢失。
文件预热
mmap只是在虚拟内存上做了映射关系,物理内存中实际并没有分配资源,只有当进程访问到,发现内存中没数据才会进行缺页中断,分配资源,而这个缺页中断是系统调用,涉及上下文切涣,比较耗费时间,对RocketMQ消息的写入动作来说,会产生性能波动。
因此,RocketMQ采用了文件预热,即预先将当前映射的文件,每一页遍历过去,写入一个0字 节,然后再调用mlock和madvise。
遍历写0字节,是为了触发缺页中断的系统调用,预发分配好内存。
mlock:将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交焕到swap空间(内存资源不够会将数据暂时存储到磁盘上)
madvise:给操作系统建议,表明文件在不久的将来要访问的。
RocketMQ write
当消费者来Broker拉取消息的时候,Broker并没有采用sendfile等方式而是直接利用write返回消息。
由于mmap的关系,消息的发送不需要用户buffer和read buffer的拷贝,只需要拷贝到socket buffer中即可。
