RocketMQ - Broker集群
概述
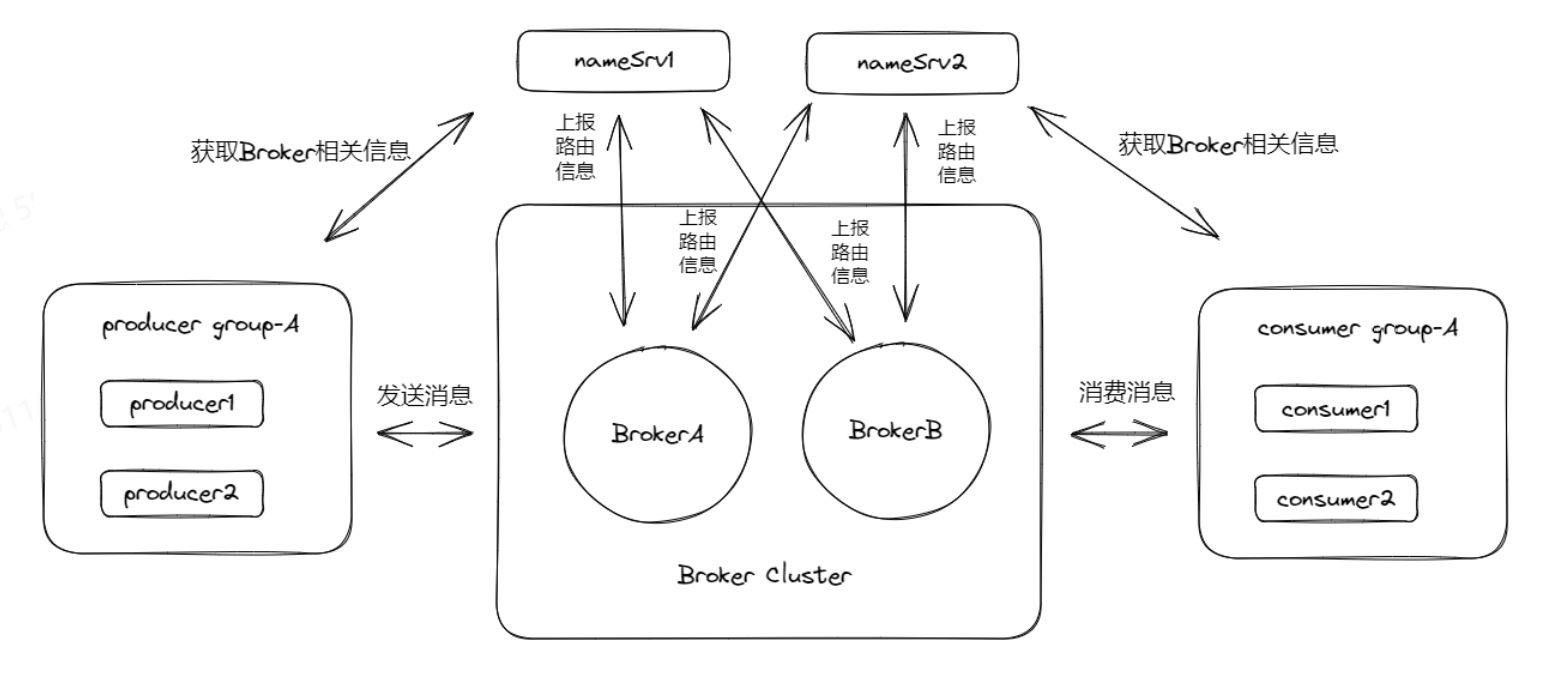
实际上Broker cluster可以分为五类:
- 单master
- 多master
- 多master多slave异步复制
- 多master多slave同步复制
- Dledger
单master
如果仅部署了一个Broker实例,那么就是单master模式。
假设这个master宕机了,那么生产者发送消息会失败、消费者拉取消息也会失败。
多master
如果仅部署一个实例风险太大,那么部署两个就能避免Broker单点的风险。
此时两个Broker会互相瓜分对应的Topic下的队列,比如TopicA一共分了8个队列,那么Broker-1承担具中的4个,Broker-2承担另外四个。
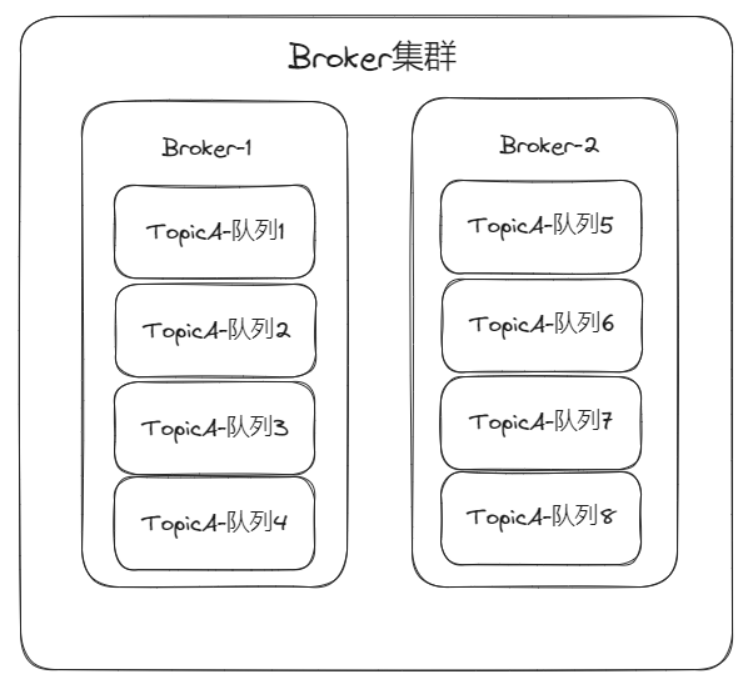
这样一来,生产者给不同队列发送消息,写入消息的压力已经均匀的分配到两个Broker身上了,提升了写消息的性能。
如果此时Broker-1宕机了,咋办呢?
生产者发送给Broker-1的消息会失败,生产者会默认重试的机制,尝试重新发送消息,而且会自动避开上次发送失败的Broker-1,会选择投递到Broker-2,所以Broker-1宕机不影响消息的发送。
但对于消费者而言,如果想消费队列-1到队列-4的消息,只能从Broker-1拉取,此时拉取肯定是失败的,因此会影响宕机前已经发送存储至Broker-1。但还未被消费的消息,这些消息的实时性无法保证,只能等Broker-1恢复。
不会影响新消息的消费,因为新的消息只会被发往Broker-2。
这时候,只要Broker-1重启,那么消费者就能顺利地拉取之前在Broker-1的消息了(如果消息已经被刷盘了的话)。
一般为了性能,消息写入到Broker后,还在页缓存中,不会同步刷到磁盘内,也就是消息写到页缓存就返回消息写入成功,此时如果断电了,那么在页缓存内的数据就没了,消息也就丢了。
异步刷盘:
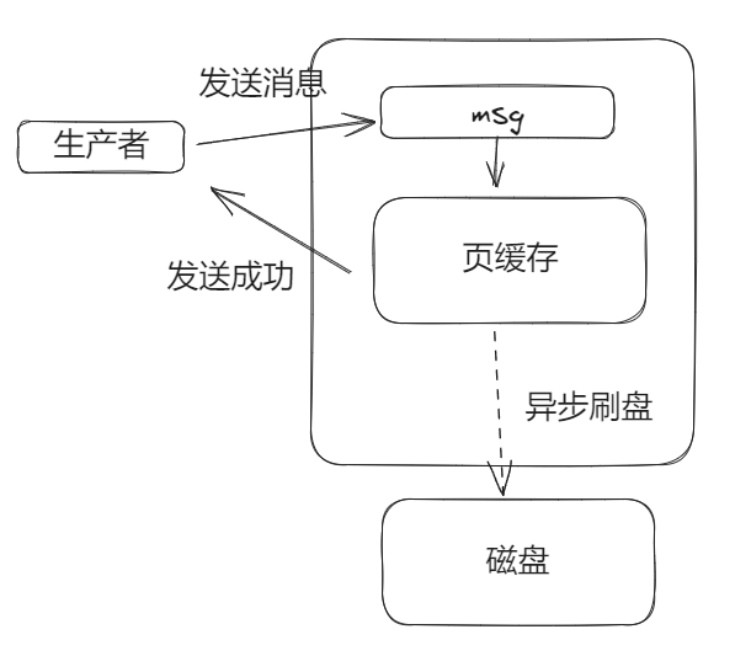
如果想消息一定不丢,只能是同步刷盘,也就是每次消息写入都直接刷盘,这样消息是不会丢的,但是这样性能不好,这就看场景进行取舍了。
同步刷盘:
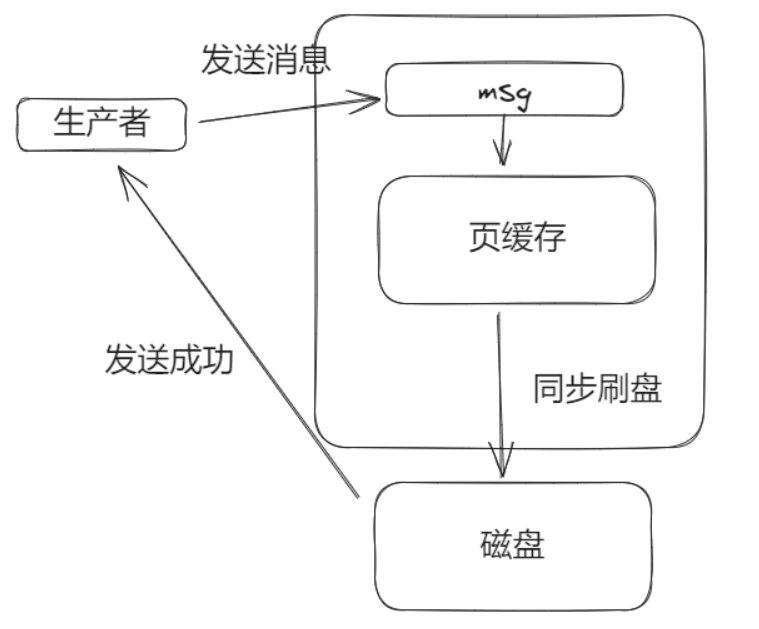
上述对生产者发送消息没影响指的是晋通消息,如果是顺序消息则会有影响。
多master多slave异步复制
上述多master的模式,如果发生一个实例宕机会影响部分消息的实时性,因此就弄了个slave来作为master的backup。
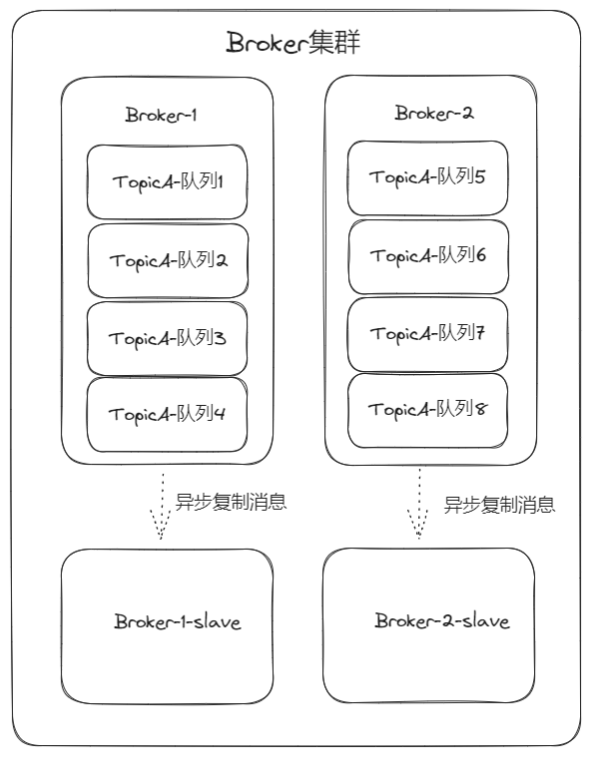
每个master对应一个slave,正常情况下slave只会默默地同步master的消息,不支持消息直接写入,正常也不会对对外提供消费。
只有当master繁忙(例如当拉取的消息太久远了或因为消息堆积严重,消息不在master内存中,就会返回繁忙,此时消费者就会去slave拉取消息,前提是slaveReadEnable参数要设置为true),或者master挂了才会被消费者消费。
总而言之,当master处理能力不太行的时候,消费者可以选择从对应的slave拉取消息,这样就避免了master不行后消息的实时性问题。
那何为异步复制呢?
生产者将消息写入到master后就返回成功了,然后slave会去master同步消息,也因此salve上的消息相对于master会有一定的滞后性,所以当master宕机,消费者从salve拉取消息的时候,可能会存在个别消息丢失的情况。
看到这可能有同学会有疑惑:为啥slave不能被生产者主动写入消息呢?
多master多slave同步复制
如果想要保证slave的消息不丢失,那么可以采取同步复制的情况。
同步复制:生产者只有在消息存储到master以及对应的salve中后,才会得到消息写入成功结果,这样就保证salve不会落后于master。
在同步复制的情况下,当master挂了,消费者从salve拉取到的是完整的消息。
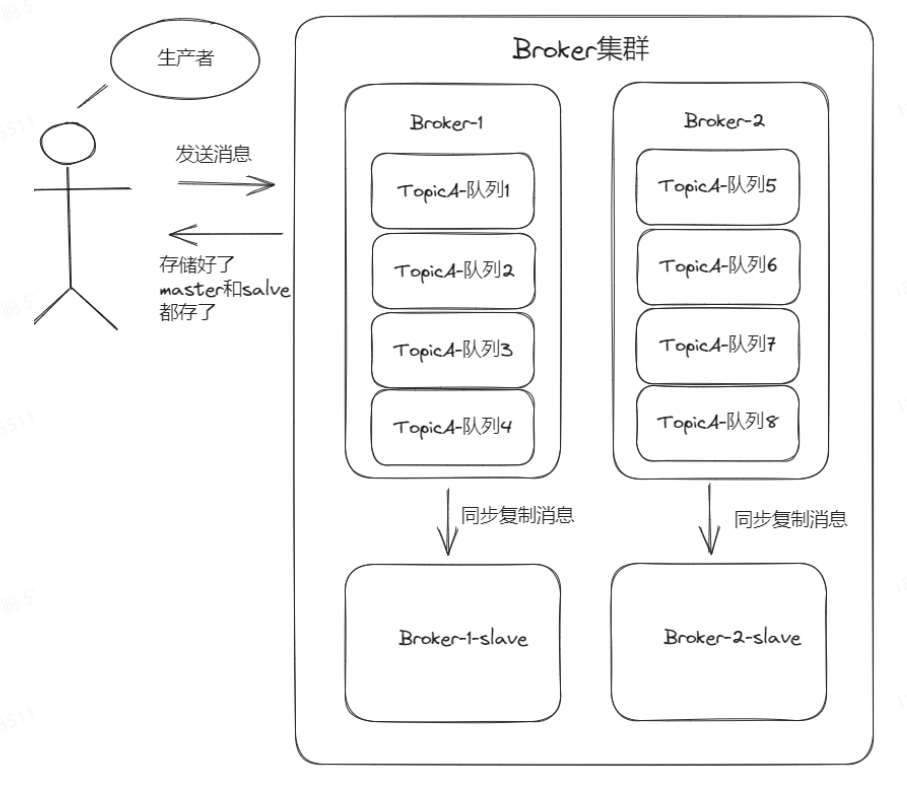
这就是同步双写,虽然保证了消息的可靠性,但是对性能会有一定的损耗。
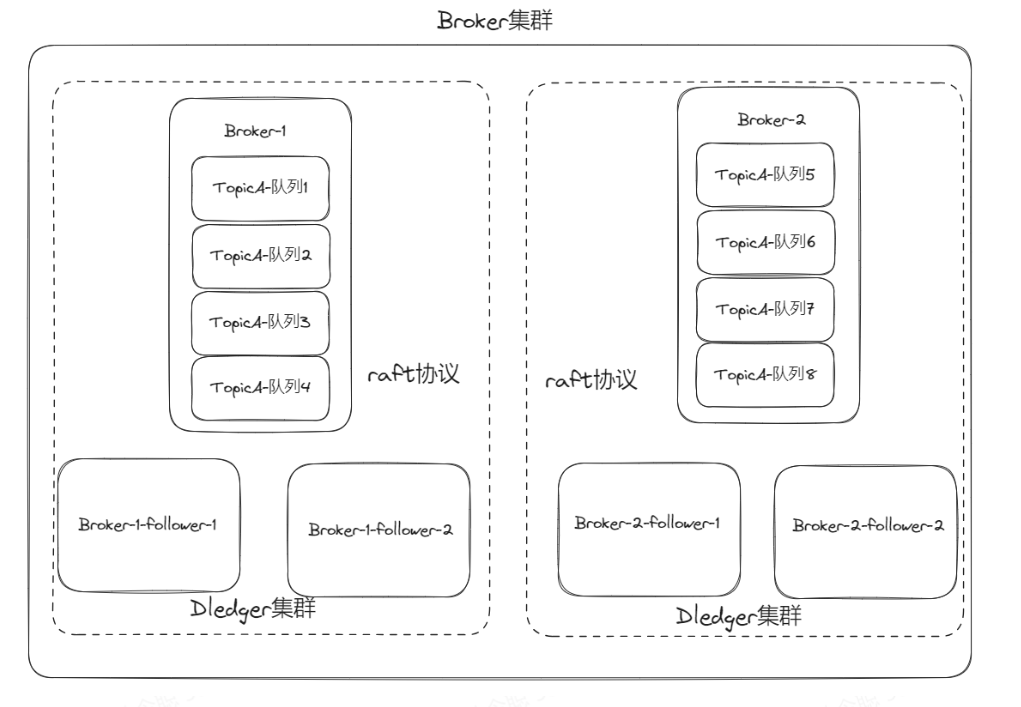
Dledger
Dledger集群算是RocketMQ集群的终极版本了。
Dledger集群指的是一组具有相同名称的Broker,至少有3个节点,它们组成RocketMQ-on-DLedger Group,这个集群基于raft协议(一致性协议),实现自动的主从切换。
当主节点挂了,那么集群内会自动选举出新的主节点。
按照raft协议的术语,主节点就是leader,想要组成这个集群,至少需要三台机子,也就是至少还得有2个follower,这样根据投票的规则,当leader挂了,才能自动从follower中选出新的leader,此时就自动完成了主从切换,使得消息能正常的写入。
之前的集群模式,当master挂了之后,slave还是slave,无法自动被提升为master,而Dledger则可以自动完成主从切换,非常顺滑。