RocketMQ - 消息消费
概述
消息消费主要存在两种模式:推消息和拉消息。
推消息
推消息:Broker收到对应的消息,立马将消息推送给消费者。
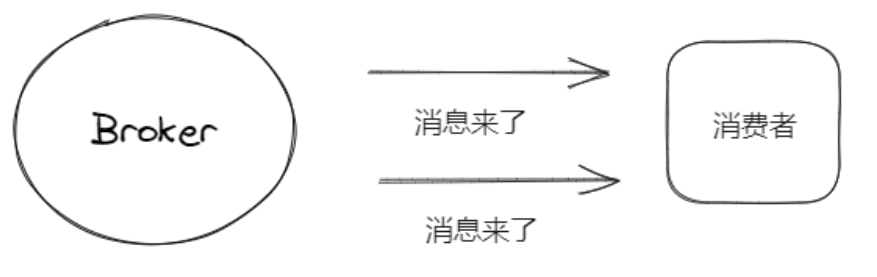
优点:消息的实时性非常高,并且对消费者而言实现比较简单,啥都不用干直接等着消息上门就行。
缺点:消费者在某个时段可能非常忙,没有时间来处理新的消息,而Broker还傻傻地使劲推消息过来,可能把消费者干爆了。违背了消息队列的一个初衷:削峰填谷。
适用场景:在消费者不多、消息量不大、及时性要求高的场景。
拉消息
拉消息:消费者主动去Broker拉取对应的消息。
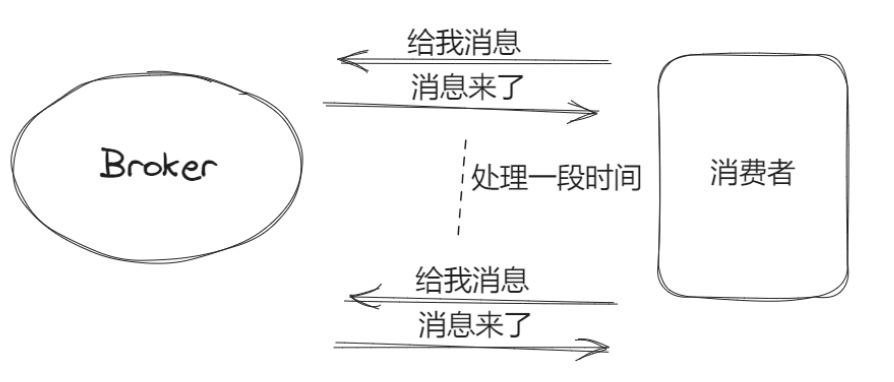
优点:Broker轻松了,生产者发送消息给Broker后,Broker仅需存储好消息就行了,接下来就等着消费者来拉消息,不需要维护其他关系。
主动权掌握在消费者手上,每个消费者可以根据自身当时的情况,选择合适的时机去Broker拉取消费。
缺点:消息的消费可能不及时。因为如果需要消费者主动去Broker拉取消息,那么在代码上的实现就是消费者定时去Broker拉取。假设定时1分钟去拉一次,发现没任何消费,而恰巧最新的一条消息刚好在消费者拉取请求后存储到Broker。那么即使现在的消费者是闲着,刚到的消息也必须等一分钟后的定时拉取才会被消费,这就是消费的不及时。
推和拉的抉择
RocketMQ和Kafka没有使用“朴素"的拉模式,而是采取了一种“变种”拉模式**:长轮询**。
消费者发送拉取请求到Broker时,如果此时有消息,那么Broker直接响应返回消息,如果没消息就hold住这个请求,比如等15s,在15s内如果有消息过来就立马响应这个请求返回消息。如果没有消息过来就返回无消息。
这样一来即避免了忙请求的情况,也进一步的提升了消息的及时性。
实际上RocketMQ本质上只实现了拉模式,pullConsumer就是去拉消息很好理解,至于还有个pushConsumer实际上是伪推模式,底层的实现还是基于长链接的长轮询去拉取消息。
消息消费的细节
消费者启动
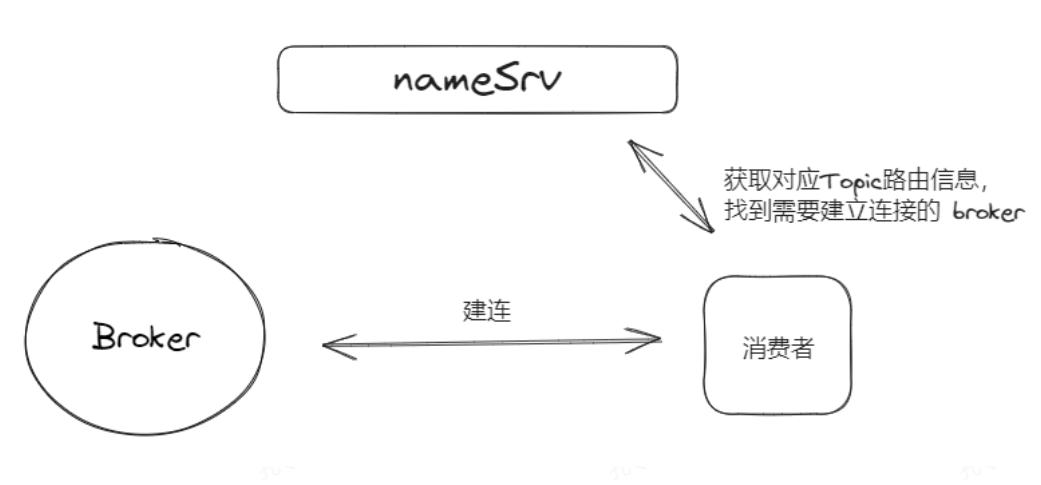
消费者启动时,需要去找看板(namersrv),因为它还不知道它订阅的Topic的消息要从哪获取。
于是启动时需要指定namersrv的地址,紧接着它根据自己的订阅情况从namersrv获取对应Topic的路由信息,即知晓自己想要的Topic在哪个Broker,以及Broker对应的地址。这样消费者就跟Broker搭上线了,连上了Broker后,Broker也知晓了这个消费者的存在。
Topic还有队列概念,对于消费者需要进行合理的“分赃”:
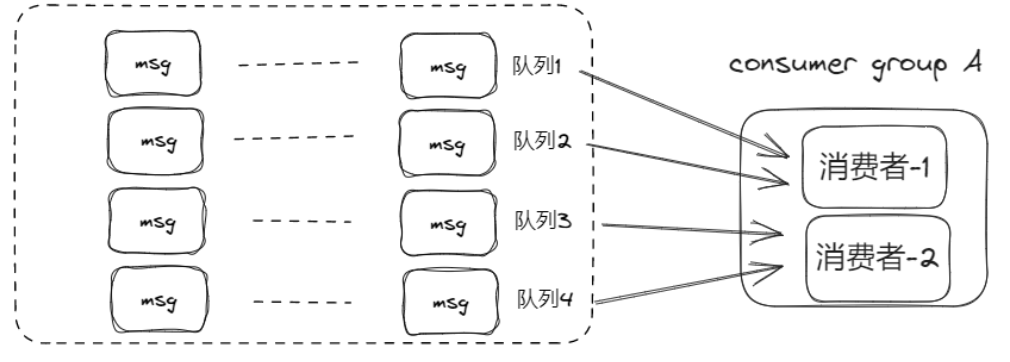
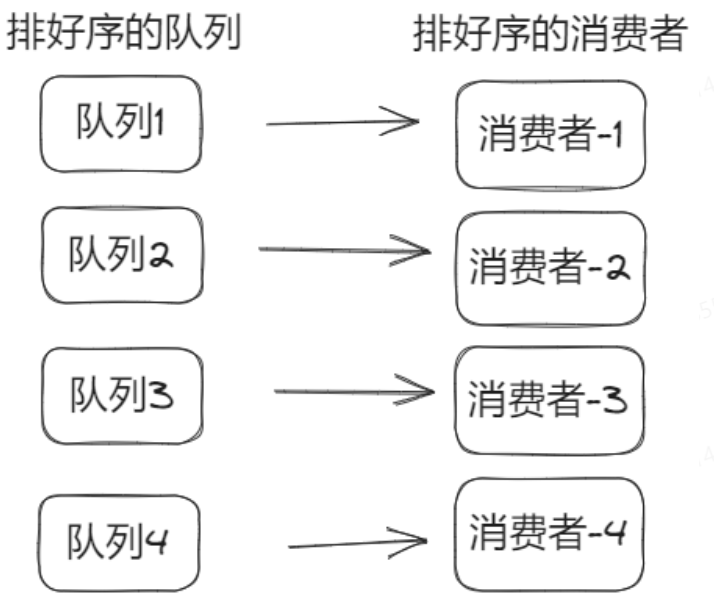
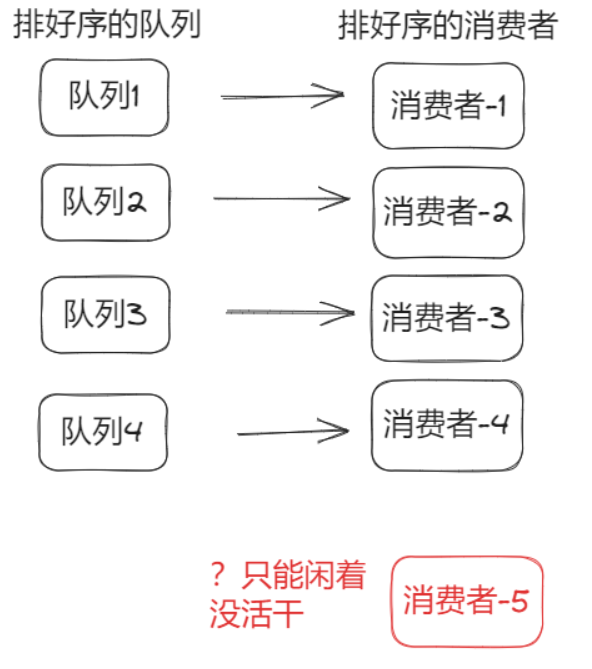
分赃的专业名称叫做:重平衡,即客户端负载均衡。一般采取均分的策略,随着消费者的增多,会到达一个极限,即继续增加消费者不一定能加快消息的消费速度。
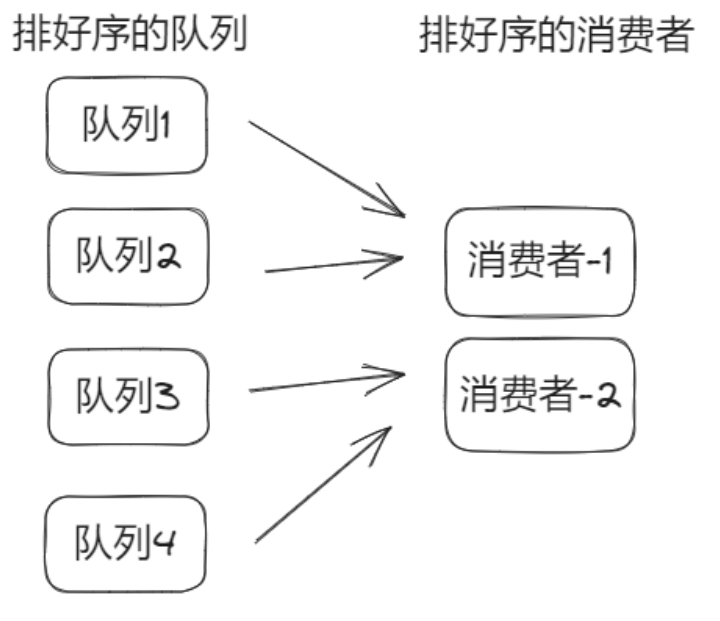
消息堆积,增加消费者能否起到环节作用。
如果这个消费组的消费者数量比Topic的队列数量小,此时增加消费者可以缓解消息堆积。如果消费者数量比队列数还多,则没用。
不仅是在消费者启动时会触发重平衡,每个消费者也会有个定时任务,每20s主动重平衡下,也就是负载均衡了,防止消费任务不均衡。并且,如果有消费者下线了,由于消费者和Broker建立了连接,下线后Broker可以知晓这个情况,此时Broker也会通知所有消费者进行重平衡。
消息如何拉取
RocketMQ只用了一个线程(叫PullMessageService)来执行拉消息的操作,所有的拉取消息的动作都会被封装成pullRequest,扔到pullRequestQueue这个阻塞队列里面。
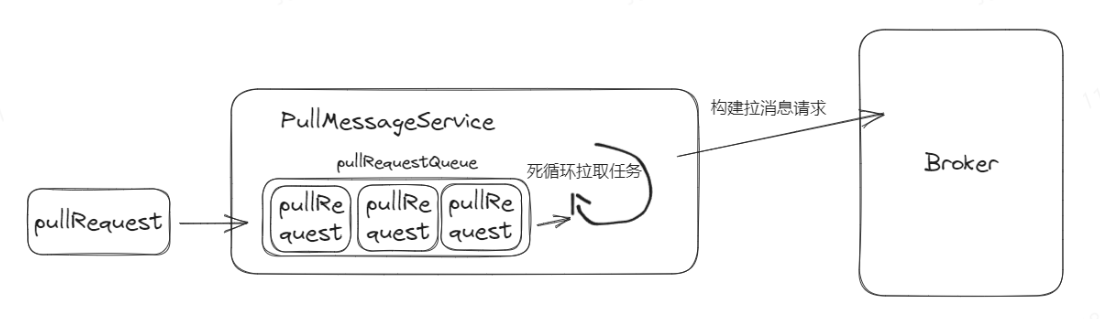
然后PullMessageService会不断的从pullRequestQueue拉取pullRequest,根据pullRequest里面的内容构建请求去对应的Broker拉取消息。
pullRequest里面包含了消费组的信息、消费点位、Topic、队列id等。
当上一个pullRequest拉取得到结果后,会里面根据响应构建新的pullRequest塞入到pullRequestQueue里面,以此来达到消息的不间断拉取。
这里引入一个叫ProcessQueue的概念,根据pullRequest获取到的结果会先缓存到ProcessQueue里面,并且再构建一个消费任务 (consumerRequest)给ConsumeMessageService这个线程池来消费消息。
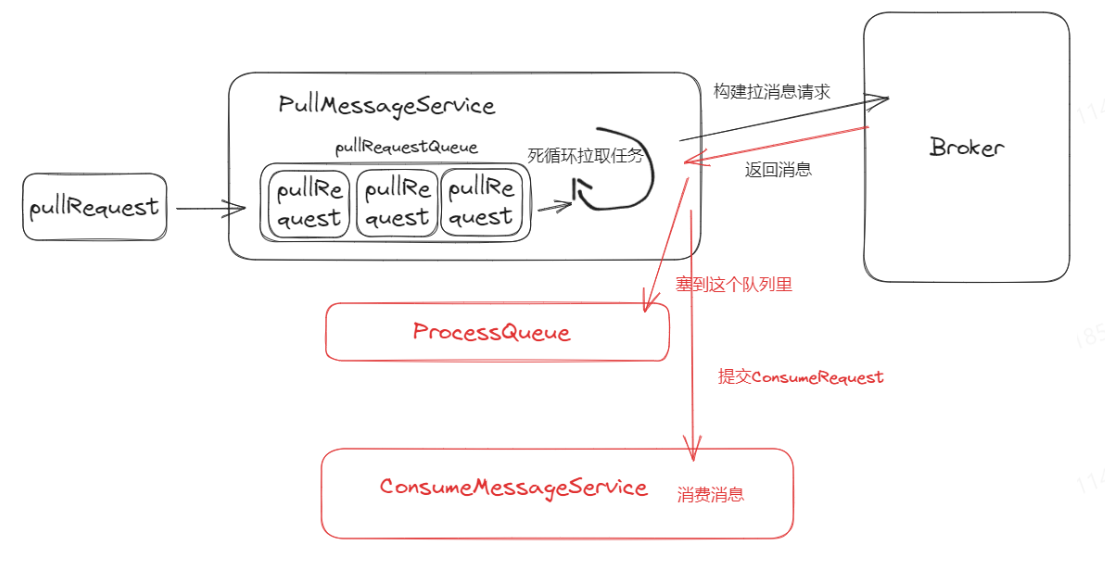
ProcessQueue起到了暂缓消息的作用,即从Broker拉到了消息,但是还未被消费者消费,这个数据可以用来流控。
如果暂缓的消息很多,那说明消息处理的慢,消息在消费者这里有堆积的情况,这时候就需要限制一下拉取的速度。也就是说不能一直构建pullRequest了,要等等,这就起到了流控的作用。即可通过控制pullRequest的生成达到流控的目的。
消息点位(offset)
在不同模式下,保存的方式不同。
广播模式
在广播模式下,消费点位将存储在消费者本地磁盘上,因为广播模式是将消息广播给每个消费者,它不需要有个统一的地方来管理这个位置,每个消费者自己维护就行。
集群模式
集群模式就不能本地维护了。因为集群模式下,同个消费组内的消费者是互帮互助的关系,如果某个消费者下线了,需要另一个消费者顶上了,这时候另一个消费者需要知晓之前消费者的消费进度,不然总不能从第一条消息开始消费吧。所以集群模式下,消费点位是存储在Broker的,这样顶上的消费者可以从Broker获取消费点位。
拉取消息时消费者会顺带把此时的消费点点位提交给Broker,这样Broker就能得知最新的消息进度。
拉消息的时候才去提交,那假设消费完了,还没来得及去拉取消息,消费者就挂了,那么此时的存在Broker里的消费点位不就不准了吗?
是的,确实不准,此时如果发生了重平衡,队列更换了新的消费者,那么就会导致消息的重复消费!
因此,这个设计无法保证消息只会被消费一次,因此我们能做的就是做好消费者端的幂等使得消费多次消息跟消息一次消息达到的效果是一样的。目前没有更好的解决方式。
如何消费消息
拉取到消息后会构建ConsumeRequest提交到线程池ConsumeMessageService。
这个线程池有两个实现,一个是并发消费,一个是顺序消费,一般情况下我们都是使用并发消费。
对于消费失败的消息需要进行重试,如果多次重试还是失败,则将该消息打入死信消息中,通过人工干预解决。RocketMQ默认16重试失败后,打入死信队列。
总结 - 消息队列生产和消费
namesrv启动后,待命。
Broker启动,将自身的信息包括IP、端口、Topic等信息上传给namesrv,等待producer发送消息,等待consumer消费消息。
Producer启动,连上namesrv,从它身上获取Broker信息,跟对应的Broker建立连接,建连后发送消息给Broker。
Broker将消息存储到commitlog文件中,并分发到consumerQueue,等待consumer来消费拉取消息。
Consumer启动,连上namesrv,从它身上获取Broker信息,跟对应的Broker建立连接,建连后发送拉取请求给Broker。
Broker根据对应的Topic、队列ID和消息点位,找到consumerQueue的消息,再解析找到对应commitlog得到消息内容,然后返回给consumer。
Consumer消费消息,在拉取消息时上报自己的消费进度给Broker。