RocketMQ - 消息存储
概述
思考:Broker关于消息的存储时如何实现的?
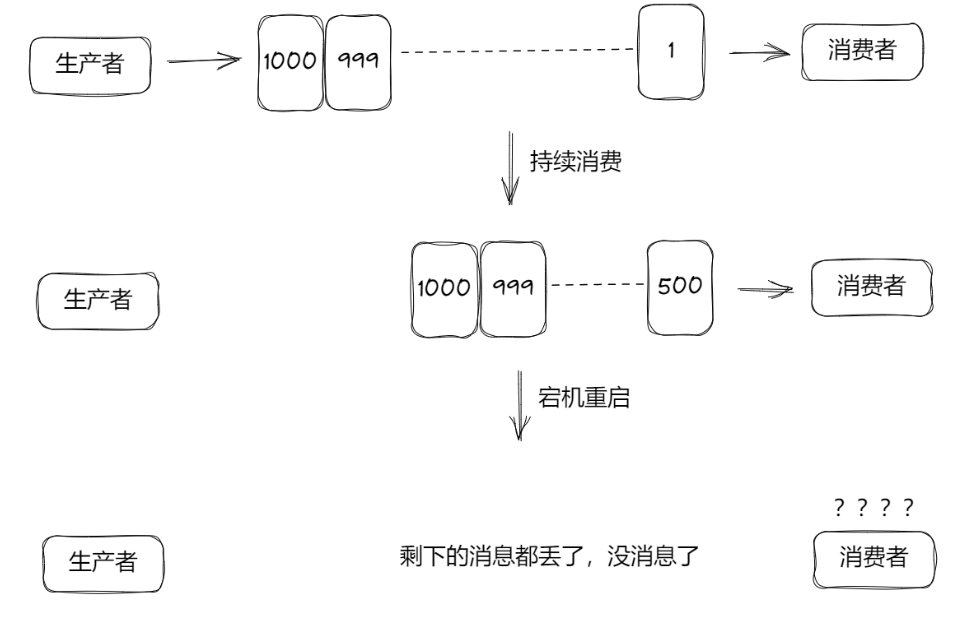
消息队列很关键的功能就是削峰填谷,当业务处于大流量压力下时,能够让给系统平缓、均匀地获取消息队列里的消息进行业务处理。这就需要保证排队的消息存储的可靠性。
极端情况下,即使消息队列突然重启,也应该确保消息不丢失。
消息存储在哪?
如果将消息存储到数据库里,每次写库的时间可能都和处理业务时间差不多,那就别谈削峰了,自己就是那座峰。

进一步思考,不存入MySQL这种关系型数据库,可以考虑存入Redis这种性能较好的非关系型数据库,但是这样一来,可靠性得不到保证。
而且,不论是依赖MySQL还是Redis或其他三方存储组件,都会增加消息队列这个中间件本身的复杂度和运维难度。
任何一件东西,只要依赖的东西变多,它就会变复杂,而复杂意味着容易出错,在工程上容易出错就容易造成线上事故。
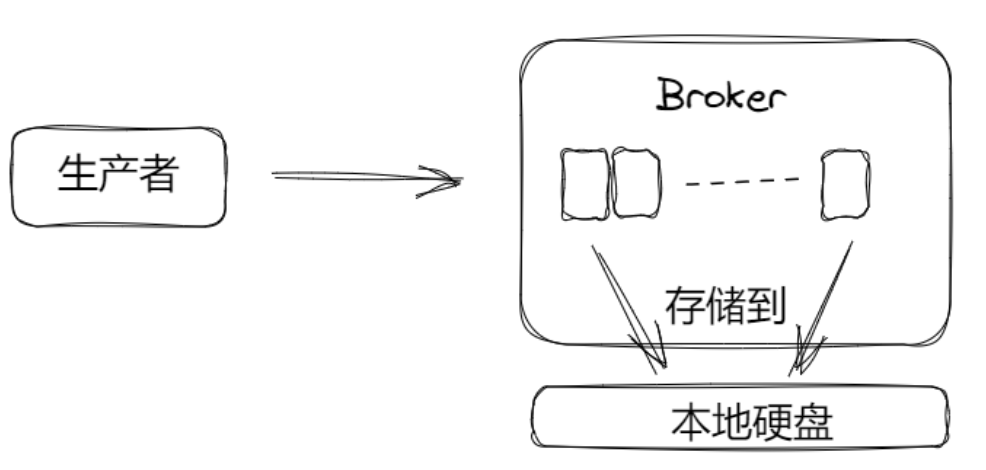
MySQL数据实际存储的地方是本地硬盘,Redis持久化的数据也是存到本地硬盘上。因此应该绕过它们直接将消息写入的本地硬盘的文件上。硬盘是RAID(磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,具有较强的冗余能力),不用考虑硬盘的不可靠性,要不然就真没办法了。
commitlog
形如在记事本中写入内容,RocketMQ类似这样存储消息的,这个文件叫做commitlog
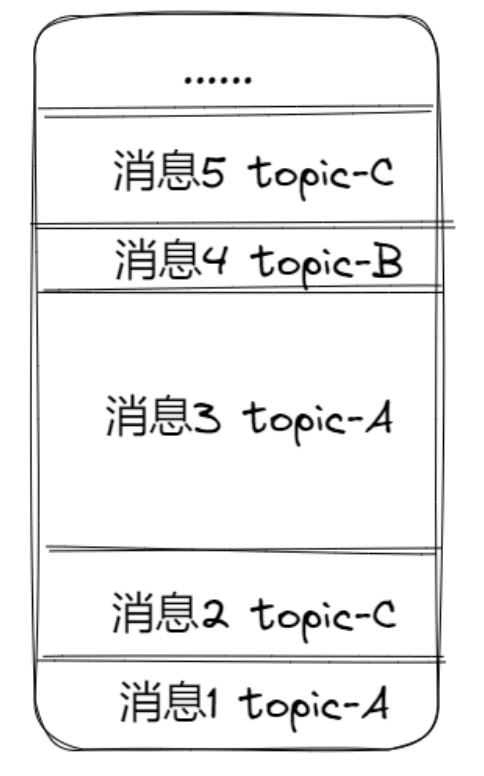
为什么将所有消息都存储在一个文件里?
在物理上,如果存储在硬盘上的数据在同一个磁道且相邻的扇区,那么根据硬盘的机械运行轨迹,读/写的顺序就非常快(省略寻道时间,顺应旋转的方向),甚至可以媲美内存的读写速度!这就是常常被提到的顺序读和顺序写。
所有消息不论是哪个topic都写入同一个文件,并且都是顺序追加写入,那么对应到硬盘上就是顺序写!这样就大大提高了消息队列写消息的性能。如果将不同的topic存入不同的文件,无法保证这些文件在物理上的位置是连续的。且如果topic很多,那么对应的文件就会很多,那每次写入不同的文件,可能都需要寻不同的道,写不同的扇区,这样速度就很慢,这就是随机写。
为了保证写入时候的性能,RocketMQ 设计所有topic的消息都写到一个文件里,以提高写入的性能,关键就是顺序写。(MySQL的redo log 也是顺序写)
消费者如何快速找到commitlog里的消息?
在 RocketMQ 里有一个ConsumeQueue(消费队列)的概念。消息写入commitlog后,就代表生产者成功发送了这条消息,并且消息也落入到硬盘中被持久化了。这时候可以启动一个定时任务,将新写入commitlog的消息转发给ConsumeQueue,这样就实现了多队列的需求。
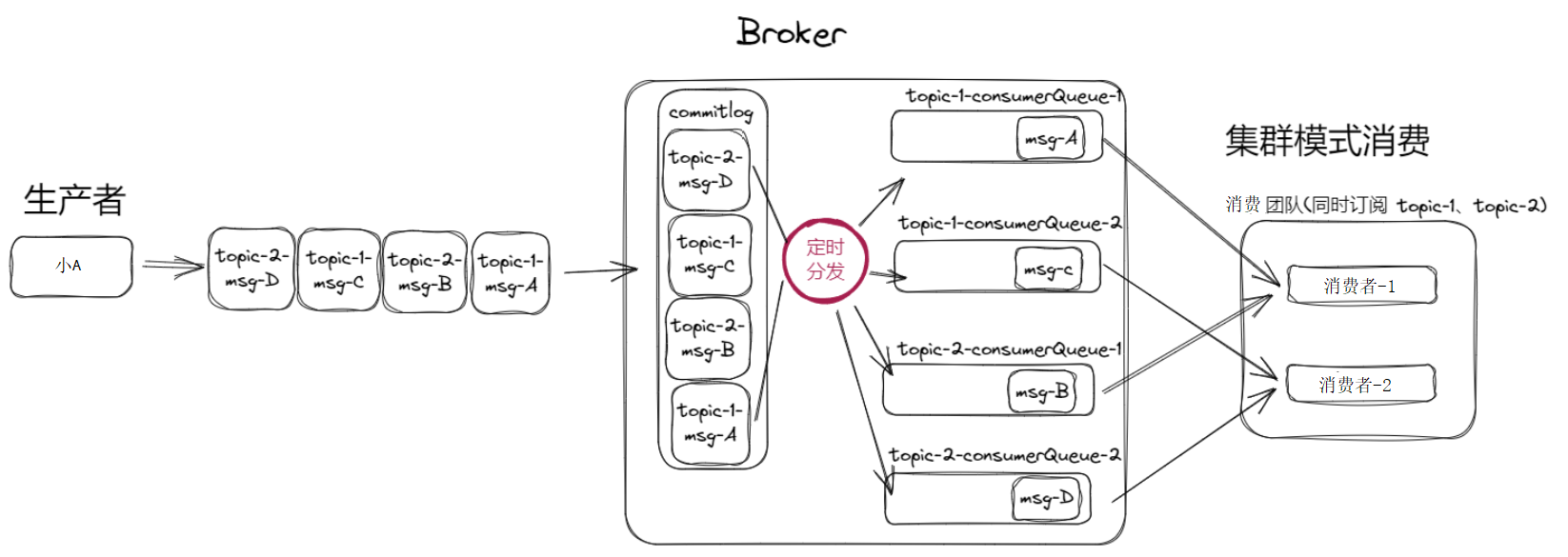
ConsumeQueue有必要存储全量消息吗?
如果ConsumeQueue存储全量消息,方便消费者直接通过ConsumeQueue获取消息,十分便捷。但是存储上有弊端,相当于复制了一份commitlog的内容到ConsumeQueue。最好的解决方法是consumerQueue存储消息在commitlog文件中的起始偏移量和本条消息的长度,通过索引的方式找到原始消息内容。
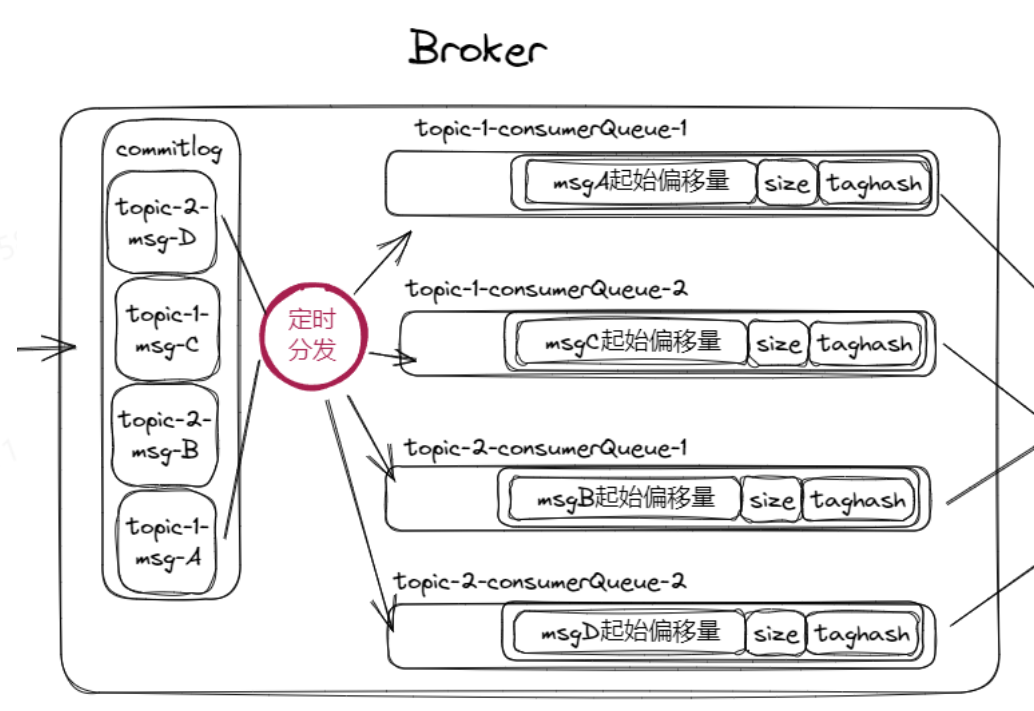
consumerQueue通过多一次查询commitlog,来减少空间上的开销。
consumerOffset
- consumerOffset:消息逻辑位置,即消费者对于某个队列消费到的位置,如一共有5条消息,此时消费者消费到第3条,那么consumerOffset就是3(从0算起那就是2)。
- commitlogOffset:消息所在commitlog文件中的偏移位置,通过这个offset找到消息的起始位置,然后根据size往后读多少位来获取一条消息完整的内容。
消费者消费一条消息的流程:通过consumerOffset找到consumerQueue里面的内容,即消息所在commitlog中的偏移量和size,然后再通过这两个数据去commitlog获取完整的消息内容。
除了commitlog、consumerQueue两个文件外,RocketMQ 中还有IndexFile,用来存储消息的索引,其格式如下:

indexFile分为了三大块:header、hash槽、index items。
head存放的就是一些元信息,方便后续的操作:
- 当前文件中消息最小的存储时间
- 当前文件中消息最大的存储时间
- 当前文件中消息在commitlog最小偏移量
- 当前文件中消息在commitlog最大偏移量
- 已用hash槽个数
- 已用index个数
IndexFile原理:
head存放元信息,500W槽:每个槽的大小是固定的,4个字节,通过计算hash(topic#aaa)得到一个hash值,再通过keyHash%500W,就能得到第几个槽。每个index item 固定为20字节,一共有2000W个index item,它就存储了消息在commitlog中的物理偏移量。
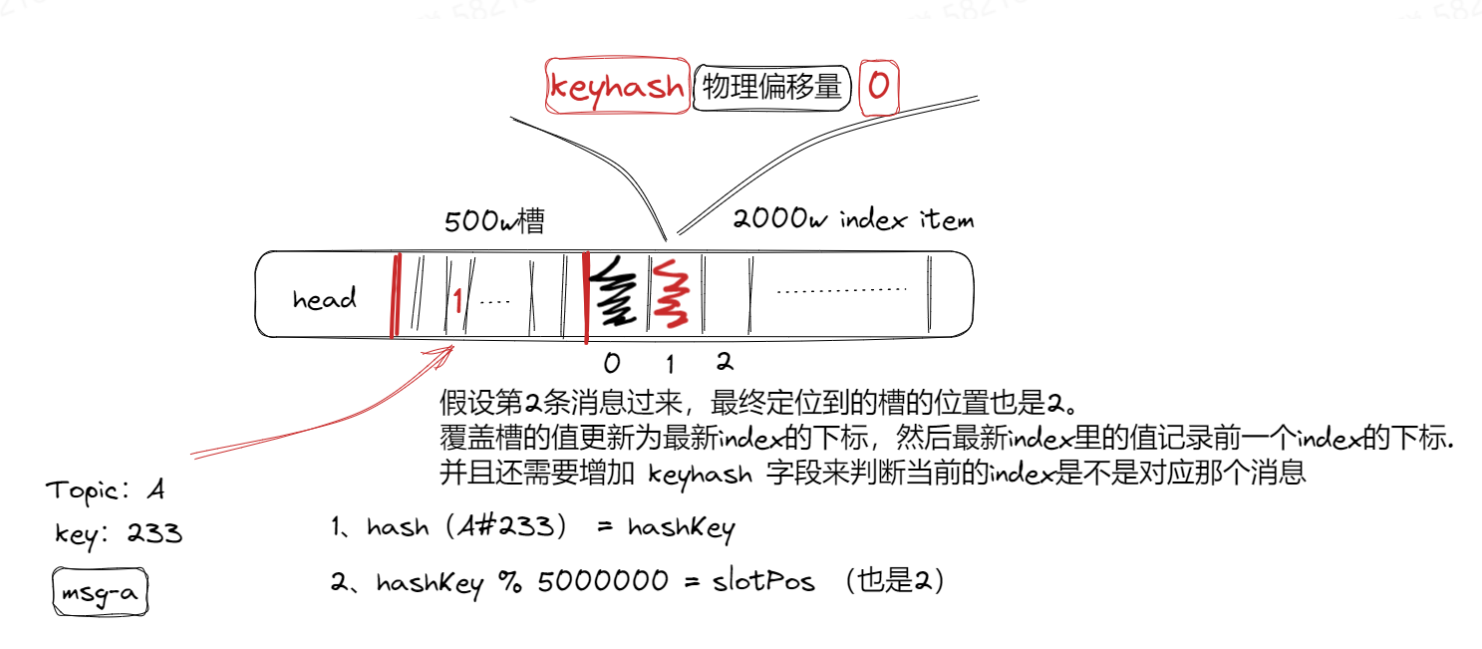
- hash(topic#aaa)=hashKey
- hashKey%5000000=2 3,indexStartOffset + 0*20 就能找到消息索引存储的值(aaa是第一条消息,槽存的是0)
hash冲突解决:
如果另外一条消息233最终的hashKey%5000000也是2,则更新槽的值为最新的index item的下标,并且在最新插入的index item里记录前一个index item的下标,即prevlndex=0。而且index item内还需要存储hashKey值,用来判断跟当前计算的hash是否一致。一致说明找到了,不一致说明是冲突的,还需要通过prevlndex值得到的上一个item的下标去查找。
index item里面还存储了个消息的时间,这个时间还是个差值:即这条消息在commitLog写入时间-IndexFiIe第一条消息的写入时间。