架构设计原则 - 正交四原则
参考资料
DANGER
待补充 正交四原则 的具体样例。
设计是什么
正如Kent Beck所说,软件设计是为了「长期」更加容易地适应未来的变化。正确的软件设计方法是为了长期地、更好更快、更容易地实现软件价值的交付。
Design is there to enable you to keep changing the software easily in the long term. -- Kent Beck.。
软件设计的目标
软件设计就是为了完成如下目标,其可验证性、重要程度依次减低。
* 实现功能(需求)
- 易于重用
- 易于理解
- 没有冗余
由 Kent Beck 大师提出简单设计四原则 一一 对应软件设计的目标,我们可以根据这些原则来指导开发,并及时验证开发的结果。
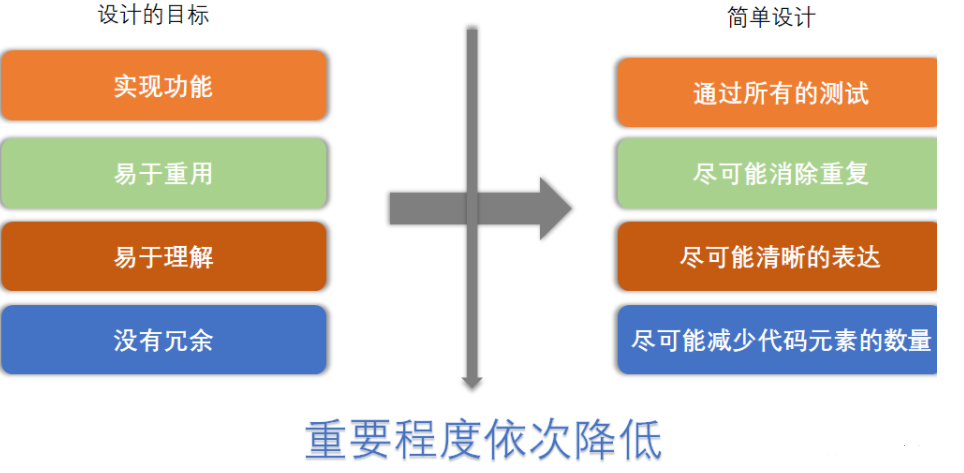
简单设计四原则
- 通过所有测试(Passes its tests)
- 尽可能消除重复 (Minimizes duplication)
- 尽可能清晰表达 (Maximizes clarity)
- 更少代码元素 (Has fewer elements)
以上四个原则的重要程度依次降低。
通过所有测试原则意味着我们开发的功能满足客户的需求,这是简单设计的底线原则。该原则同时隐含地告知与客户或领域专家(需求分析师)充分沟通的重要性。
尽可能消除重复原则是对代码质量提出的要求,并通过测试驱动开发的重构环节来完成。注意此原则提到的是Minimizes(尽可能消除),而非No duplication(无重复),因为追求极致的重用存在设计与编码的代价。
尽可能清晰表达原则要求代码要简洁而清晰地传递领域知识,在领域驱动设计的语境下,就是要遵循统一语言,提高代码的可读性,满足业务人员与开发人员的交流目的。针对核心领域,甚至可以考虑引入领域特定语言(Domain Specific Language,DSL)来表现领域逻辑。
在满足这三个原则的基础上,更少代码元素原则告诫我们遏制过度设计的贪心,做到设计的恰如其分,即在满足客户需求的基础上,只要代码已经做到了最少重复与清晰表达,就不要再进一步拆分或提取类、方法和变量。
这四个原则是依次递进的,功能正确,减少重复,代码可读是简单设计的根本要求。一旦满足这些要求,就不能创建更多的代码元素去迎合未来可能并不存在的变化,避免过度设计。
实现功能
实现功能的目标压倒一切,也是软件设计的首要标准。
如何判定系统功能的完备性呢?
- 通过所有测试用例!
从 TDD 的角度看,测试用例就是对需求的阐述,是一个闭环的反馈系统,保证其系统的正确性;及其保证设计的合理性,恰如其分,不多不少;当然也是理解系统行为最重要的依据。
易于重用
易于重用的软件结构的特点:
- 应对变化更具弹性
- 容易被修改
- 具有更加适应变化的能力
最理想的情况下,所有的软件修改都具有局部性。但现实并非如此,软件设计往往需要花费很大的精力用于依赖的管理,让组件之间的关系变得清晰、一致、漂亮。
那么软件设计的最高准则是什么呢?
- 「高内聚、低耦合」原则是提高可重用性的最高原则。
易于理解
好的设计不只是指导计算机执行指令,更重要的是能让其他人也能容易地理解,包括系统的行为,业务的规则。
那么,什么样的设计才算得上易于理解的呢?
Clean Code(代码整洁)
- 包含变量命名,函数使用等。
Implement Patterns(实现模式)
- 采用通用的实现模式,使用MVC架构、采用设计模式等。
Idioms
- 遵循一些设计原则,如简单设计原则、正交设计原则、面向对象设计原则、高内聚低耦合、小类大对象等等原则。
没有冗余
没有冗余的系统是最简单的系统,恰如其分的系统,不做任何过度设计的系统。
Dead Code —— 从未被执行的代码,应当删除
YAGNI: You Ain’t Gonna Need It —— 不要做过度设计,只需要先实现好现在需要的功能点。
KISS: Keep it Simple, Stupid —— 尽量保持简单
正交设计
「正交」是一个数学概念:所谓正交,就是指两个向量的内积为零。简单的说,就是这两个向量是垂直的。在一个正交系统里,沿着一个方向的变化,其另外一个方向不会发生变化。为此,Bob大叔将「职责」定义为「变化的原因」。
「正交性」,意味着更高的内聚,更低的耦合。为此,正交性可以用于衡量系统的可重用性。
如何保证设计的正交性呢?
- 袁英杰提出了「正交设计的四个基本原则」,简明扼要,道破了软件设计的精髓所在。
正交设计原则:
- 消除重复
- 分离关注点
- 例如,身高排序,年龄排序,冒泡排序算法
- 排序对象:身高,年龄
- 排序对象比较规则:<=,>=
- 分离排序对象和排序规则
- 缩小依赖范围
- 向稳定的方向依赖

实例
需求1: 存在一个学生的列表,查找一个年龄等于18岁的学生
Student* findByAge(vector<Student> students)
{
for (int i=0; i<students.size(); i++) {
if (students[i].getAge() == 18) {
return &students[i];
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
上述实现存在很多设计的「坏味道」:
- 缺乏弹性参数类型:只支持数组类型,List, Set都被拒之门外;
- 容易出错:操作数组下标,往往引入不经意的错误;
- 幻数:硬编码,将算法与配置高度耦合;
- 返回null:再次给用户打开了犯错的大门;
使用auto 按照「最小依赖原则」,先隐藏数组下标的实现细节,使用for-each降低错误发生的可能性。
Student* findByAge(vector<Student> students)
{
for (auto s : students) {
if (s.getAge() == 18) {
return &s;
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
需求2: 查找一个名字为Jason的学生
重复设计:Copy-Paste是最快的实现方法,但会产生「重复设计」。
Student* findByName(vector<Student> students)
{
for (auto s : students) {
if (s.getName() == "Jason") {
return &s;
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
为了消除重复,**可以将「查找算法」与「比较准则」**这两个「变化方向」进行分离。
抽象准则
首先将比较的准则进行抽象化,让其独立变化。
class StudentJudgeCriteria
{
public:
virtual bool testCriter(Student s)=0;
}
class AgeJudgeCriteria :public StudentJudgeCriteria
{
public:
AgeJudgeCriteria(int name):_age(age) {}
public:
bool testCriter(Student s) override{
return s.getAge() == _age;
};
private:
int _age;
}
class NameJudgeCriteria :public StudentJudgeCriteria
{
public:
NameJudgeCriteria(std::string name):_name(name) {}
public:
bool testCriter(Student s) override{
return s.getName() == _name;
};
private:
std::string _name;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
将各个「变化原因」对象化,为此建立了两个简单的算子。
此刻,查找算法的方法名也应该被「重命名」,使其保持在同一个「抽象层次」上。
Student* find(vector<Student> students,StudentJudgeCriteria judge)
{
for (auto s : students) {
if (judge.testCriter(s)) {
return &s;
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
客户端的调用根据场景,提供算法的配置。
AgeJudgeCriteria ageJudge(18);
NameJudgeCriteria nameJudge("jason");
assert(find(students, ageJudge), nullptr);
assert(find(students, nameJudge), nullptr);
2
3
4
结构性重复
AgeJudgeCriteria和NameJudgeCriteria存在「结构型重复」,需要进一步消除重复。经分析两个类的存在无非是为了实现「闭包」的能力,可以使用lambda表达式,「Code As Data」,简明扼要。
assert(find(students, s -> s.getAge() == 18), nullptr);
assert(find(students, s -> s.getName().equals("Jason")), nullptr);
2
引入Iterable
按照「向稳定的方向依赖」的原则,为了适应诸如List, Set等多种数据结构,甚至包括原生的数组类型,可以将入参重构为重构为更加抽象的Iterable类型。
但是C++暂不支持,使用Iterable
Student* find(vector<Student> students,StudentJudgeCriteria judge)
{
for (auto iter=students.begin(); iter!=students.end() ;iter++) {
if (judge.testCriter(*iter)) {
return iter;
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
需求3: 存在一个老师列表,查找第一个女老师
类型重复
按照既有的代码结构,可以通过Copy Paste快速地实现这个功能。
Teacher* find(vector<Teacher> teachers,TeacherJudgeCriteria judge)
{
for (auto iter=teachers.begin(); iter!=teachers.end() ;iter++) {
if (judge.testCriter(*iter)) {
return iter;
}
}
return nullptr;
}
2
3
4
5
6
7
8
9
10
类型参数化
分析StudentMacher/TeacherPredicate, find(Iterable
首先消除StudentJudgeCriteria和TeacherJudgeCriteria的重复设计。
public interface Predicate<E> { boolean test(E e); }
再对find进行类型参数化设计。
public static <E> E find(Iterable<E> c, Predicate<E> p) { for (E e : c) if (p.test(e)) return e; return null; }
型变
但find的类型参数缺乏「型变」的能力,为此引入「型变」能力的支持,接口更加具有可复用性。
public static <E> E find(Iterable<? extends E> c, Predicate<? super E> p) { for (E e : c) if (p.test(e)) return e; return null; }
复用lambda
Parameterize all the things.
观察如下两个测试用例,如果做到极致,可认为两个lambda表达式也是重复的。从「分离变化的方向」的角度分析,此lambda表达式承载的「比较算法」与「参数配置」两个职责,应该对其进行分离。
assertThat(find(students, s -> s.getName().equals("Horance")), notNullValue());
assertThat(find(students, s -> s.getName().equals("Tomas")), notNullValue());
2
可以通过「Static Factory Method」生产lambda表达式,将比较算法封装起来;而配置参数通过引入「参数化」设计,将「逻辑」与「配置」分离,从而达到最大化的代码复用。
public final class StudentPredicates { private StudentPredicates() { } public static Predicate<Student> age(int age) { return s -> s.getAge() == age; } public static Predicate<Student> name(String name) { return s -> s.getName().equals(name); } }
import static StudentPredicates.*;
assertThat(find(students, name("horance")), notNullValue());
assertThat(find(students, age(10)), notNullValue());
2
3
4
5
组合查询
但是,上述将lambda表达式封装在Factory的设计是及其脆弱的。例如,增加如下的需求:
需求4: 查找年龄不等于18岁的女生
最简单的方法就是往StudentPredicates不停地增加「Static Factory Method」,但这样的设计严重违反了「OCP」(开放封闭)原则。
public final class StudentPredicates { ...... public static Predicate<Student> ageEq(int age) { return s -> s.getAge() == age; } public static Predicate<Student> ageNe(int age) { return s -> s.getAge() != age; } }
从需求看,比较准则增加了众多的语义,再次运用「分离变化方向」的原则,可发现存在两类运算的规则:
- 比较运算:==, !=
- 逻辑运算:&&, ||
比较语义
先处理比较运算的变化方向,为此建立一个Matcher的抽象:
public interface Matcher<T> { boolean matches(T actual); static <T> Matcher<T> eq(T expected) { return actual -> expected.equals(actual); } static <T> Matcher<T> ne(T expected) { return actual -> !expected.equals(actual); } }
Composition everywhere.
2
此刻,age的设计运用了「函数式」的思维,其行为表现为「高阶函数」的特性,通过函数的「组合式设计」完成功能的自由拼装组合,简单、直接、漂亮。
public final class StudentPredicates { ...... public static Predicate<Student> age(Matcher<Integer> m) { return s -> m.matches(s.getAge()); } }
查找年龄不等于18岁的学生,可以如此描述。
assertThat(find(students, age(ne(18))), notNullValue());
逻辑语义
为了使得逻辑「谓词」变得更加人性化,可以引入「流式接口」的「DSL」设计,增强表达力。
public interface Predicate<E> { boolean test(E e); default Predicate<E> and(Predicate<? super E> other) { return e -> test(e) && other.test(e); } }
查找年龄不等于18岁的女生,可以表述为:
assertThat(find(students, age(ne(18)).and(Student::female)), notNullValue());
重复再现
仔细的读者可能已经发现了,Student和Teacher两个类也存在「结构型重复」的问题。
public class Student { public Student(String name, int age, boolean male) { this.name = name; this.age = age; this.male = male; } ...... private String name; private int age; private boolean male; }
public class Teacher { public Teacher(String name, int age, boolean male) { this.name = name; this.age = age; this.male = male; } ...... private String name; private int age; private boolean male; }
2
级联反应
Student与Teacher的结构性重复,导致StudentPredicates与TeacherPredicates也存在「结构性重复」。
public final class StudentPredicates { ...... public static Predicate<Student> age(Matcher<Integer> m) { return s -> m.matches(s.getAge()); } }
public final class TeacherPredicates { ...... public static Predicate<Teacher> age(Matcher<Integer> m) { return t -> m.matches(t.getAge()); } }
2
为此需要进一步消除重复。
提取基类
第一个直觉,通过「提取基类」的重构方法,消除Student和Teacher的重复设计。
class Human {
protected Human(String name, int age, boolean male) { this.name = name; this.age = age; this.male = male; } ... private String name; private int age; private boolean male; }
2
从而实现了进一步消除了Student和Teacher之间的重复设计。
public class Student extends Human { public Student(String name, int age, boolean male) { super(name, age, male); } } public class Teacher extends Human { public Teacher(String name, int age, boolean male) { super(name, age, male); } }
类型界定
此时,可以通过引入「类型界定」的泛型设计,使得StudentPredicates与TeacherPredicates合二为一,进一步消除重复设计。
public final class HumanPredicates { ...... public static <E extends Human> Predicate<E> age(Matcher<Integer> m) { return s -> m.matches(s.getAge()); } }
消灭继承关系
Student和Teacher依然存在「结构型重复」的问题,可以通过Static Factory Method的设计方法,并让Human的构造函数「私有化」,删除Student和Teacher两个子类,彻底消除两者之间的「重复设计」。
public class Human { private Human(String name, int age, boolean male) { this.name = name; this.age = age; this.male = male; } public static Human student(String name, int age, boolean male) { return new Human(name, age, male); } public static Human teacher(String name, int age, boolean male) { return new Human(name, age, male); } ...... }
消灭类型界定
Human的重构,使得HumanPredicates的「类型界定」变得多余,从而进一步简化了设计。
public final class HumanPredicates { ...... public static Predicate<Human> age(Matcher<Integer> m) { return s -> m.matches(s.getAge()); } }
绝不返回null
Billion-Dollar Mistake
在最开始,我们遗留了一个问题:find返回了null。用户调用返回null的接口时,常常忘记null的检查,导致在运行时发生NullPointerException异常。
按照「向稳定的方向依赖」的原则,find的返回值应该设计为Optional
显式地表达了不存在的语义;
编译时保证错误的发生;
import java.util.Optional;
public <E> Optional<E> find(Iterable<? extends E> c, Predicate<? super E> p) { for (E e : c) { if (p.test(e)) { return Optional.of(e); } } return Optional.empty(); }
2
3
回顾 通过4个需求的迭代和演进,通过运用「正交设计」和「组合式设计」的基本思想,加深对「正交设计基本原则」的理解。