知识 - 看门狗和喂狗机制
Watchdog机制原理和喂狗机制。
参考资料
看门狗
守护脚本的功能是,当检测到某进程不存在是,立即重启该进程,对应着服务器检测到某个进程不喂狗时立即杀死该进程。
两者想结合完成对客户端及服务器端的保护。守护进程中用shell语言编写了protect函数,输入参数为$1,即进程名。启动守护脚本后,将分先后运行服务器和客户端可执行文件并运行在后台,再在主循环中轮询守护对应的进程。
DETAILS
./zhx_server &
./client1 &
./client2 &
function protect {
# PRO_NAME = $1
#用ps获取$PRO_NAME进程数量
NUM=`ps aux | grep -w $1 | grep -v grep |wc -l`
#echo $NUM
#少于1,重启进程
if [ "${NUM}" -lt "1" ];then
echo "[main.sh] $1 was killed"
./$1 &
#大于1,杀掉所有进程,重启
elif [ "${NUM}" -gt "1" ];then
echo "[main.sh] more than 1 $1,killall $1"
killall -9 $PRO_NAME
./$1 &
fi
#kill僵尸进程
NUM_STAT=`ps aux | grep -w $1 | grep T | grep -v grep | wc -l`
if [ "${NUM_STAT}" -gt "0" ];then
killall -9 $1
./$1 &
fi
# sleep 1s
}
# NAME="client1"
while true ; do
protect "zhx_server"
protect "client1"
protect "client2"
done
exit 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
安卓系统中WatchDog工作原理
Softwere Watchdog Timeout,顾名思义就是软件超时监控狗。
原理框架示意图:
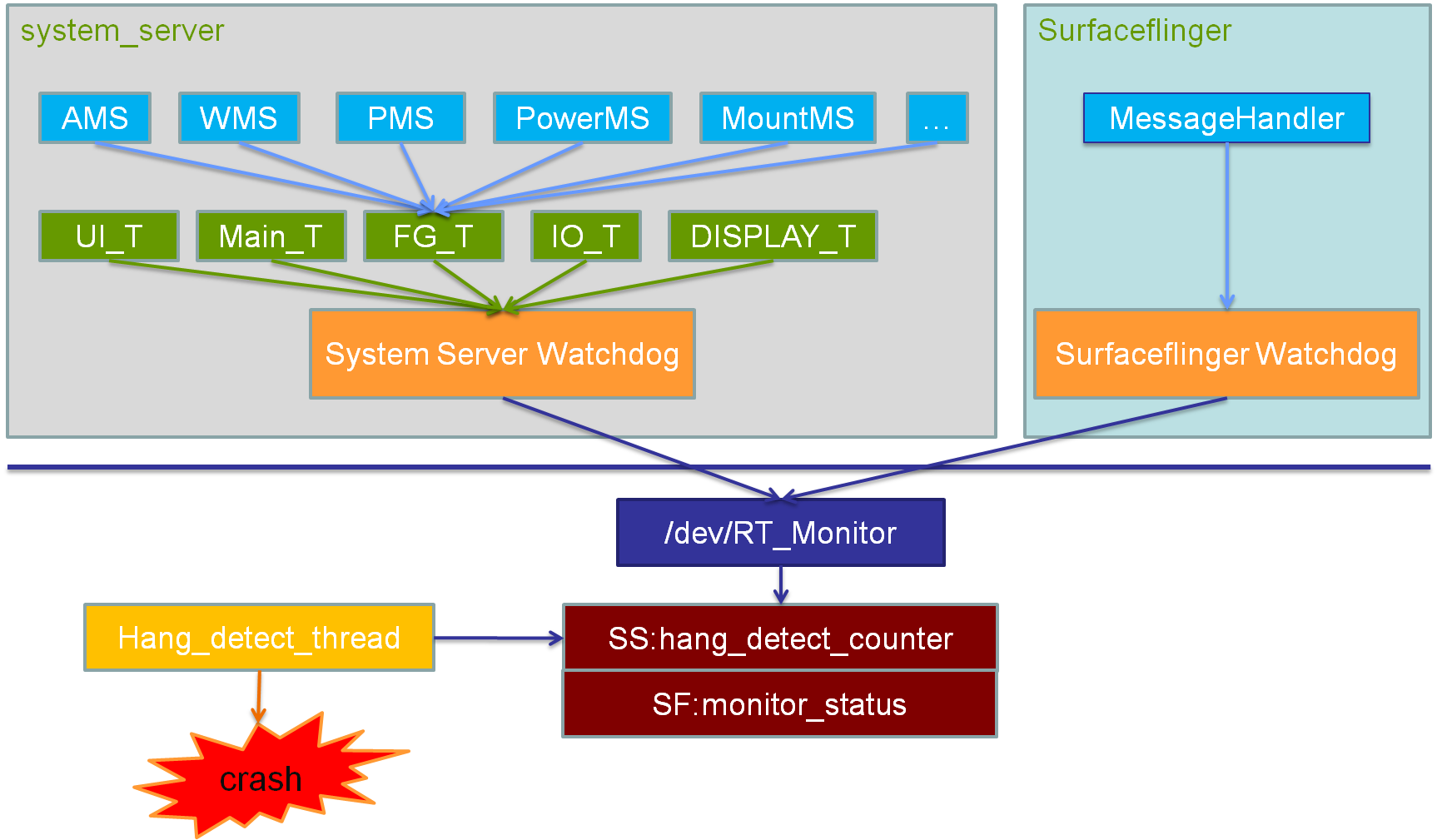
System Server 进程是Android的一个核心进程,里面为App运行提供了很多核心服务,如AMS、WMS、PKMS等等,如果这些核心的服务和重要的线程卡住,就会导致相应的功能异常。如果没有一种机制让这些服务复位的话,就会严重影响用户的体验,所以Google引入了System Server Watchdog 机制,用来监控这些核心服务和重要线程是否被卡住。
Watchdog的初始化
Watchdog的初始化是在SystemServer init的后期,如果SystemServer在init的过程中卡死了,那么就意味着Watchdog不会生效。
Watchdog是一个单例线程,在SystemServer启动时就会获取它并初始化和启动(init/start).
private void startOtherServices() {
...
traceBeginAndSlog("InitWatchdog");
final Watchdog watchdog = Watchdog.getInstance();
watchdog.init(context, mActivityManagerService);
traceEnd();
...
traceBeginAndSlog("StartWatchdog");
Watchdog.getInstance().start();
traceEnd();
...
}
2
3
4
5
6
7
8
9
10
11
12
Watchdog继承于Thread,创建的线程名为”watchdog”。mHandlerCheckers队列包括、 主线程,fg, ui, io, display线程的HandlerChecker对象。
private Watchdog() {
super("watchdog");
mMonitorChecker = new HandlerChecker(FgThread.getHandler(),
"foreground thread", DEFAULT_TIMEOUT);
mHandlerCheckers.add(mMonitorChecker);
// Add checker for main thread. We only do a quick check since there
// can be UI running on the thread.
mHandlerCheckers.add(new HandlerChecker(new Handler(Looper.getMainLooper()),
"main thread", DEFAULT_TIMEOUT));
// Add checker for shared UI thread.
mHandlerCheckers.add(new HandlerChecker(UiThread.getHandler(),"ui thread", DEFAULT_TIMEOUT));
// And also check IO thread.
mHandlerCheckers.add(new HandlerChecker(IoThread.getHandler(),"i/o thread", DEFAULT_TIMEOUT));
// And the display thread.
mHandlerCheckers.add(new HandlerChecker(DisplayThread.getHandler(),
"display thread", DEFAULT_TIMEOUT));
// And the animation thread.
mHandlerCheckers.add(new HandlerChecker(AnimationThread.getHandler(),
"animation thread", DEFAULT_TIMEOUT));
// And the surface animation thread.
mHandlerCheckers.add(new HandlerChecker(SurfaceAnimationThread.getHandler(),
"surface animation thread", DEFAULT_TIMEOUT));
......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
HandlerChecker分类
大致可以分为两类
Looper Checker: 用于检查线程的消息队列是否长时间处于非空闲状态,Watchdog自身的消息队列,Ui, Io, Display这些全局的消息队列都是被检查的对象。 如果被监测的消息队列一直闲不下来,则说明可能已经阻塞等待了很长时间。
Monitor Checker: 用于检查Monitor对象是否发生死锁,AMP、PKMS、WMS等核心系统服务都是Monitor对象。通过调用实现类的monitor方法,例如AMS.monitor()方法, 获取当前类的对象锁,如果当前对象锁已经被持有,则monitor()会一直处于wait状态,直到超时,这种情况下,很可能是线程发生了死锁。
Watchdog的运作
@Override
public void run() {
boolean waitedHalf = false; //标识第一个30s超时
boolean mSFHang = false; //标识surfaceflinger是否hang
while (true) {
...
synchronized (this) {
...
// 1. 调度所有的HandlerChecker
for (int i=0; i<mHandlerCheckers.size(); i++) {
HandlerChecker hc = mHandlerCheckers.get(i);
//shceduleCheckLocked()所做的事情可以想象成给所有的目标thread发放任务。
hc.scheduleCheckLocked();
}
...
// 2. 开始定期检查
long start = SystemClock.uptimeMillis();
while (timeout > 0) {
...
try {
wait(timeout);
} catch (InterruptedException e) {
Log.wtf(TAG, e);
}
...
timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start);
}
// 3. 检查HandlerChecker的完成状态
final int waitState = evaluateCheckerCompletionLocked();
if (waitState == COMPLETED) {
...
continue;
} else if (waitState == WAITING) {
...
continue;
} else if (waitState == WAITED_HALF) {
...
continue;
}
// 4. 存在超时的HandlerChecker
blockedCheckers = getBlockedCheckersLocked();
//超了60秒,此时便出问题了,收集超时的HandlerChecker
subject = describeCheckersLocked(blockedCheckers);
allowRestart = mAllowRestart;
}
...
// 5. 保存日志,判断是否需要杀掉系统进程
Slog.w(TAG, "*** GOODBYE!");
Process.killProcess(Process.myPid());
System.exit(10);
} // end of while (true)
......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
以上代码片段主要的运行逻辑如下:
- Watchdog运行后,便开始无限循环,依次调用每一个HandlerChecker的scheduleCheckLocked()方法
- 调度完HandlerChecker之后,便开始定期检查是否超时,每一次检查的间隔时间由CHECK_INTERVAL常量设定,为30秒
- 每一次检查都会调用evaluateCheckerCompletionLocked()方法来评估一下HandlerChecker的完成状态:
- COMPLETED表示已经完成
- WAITING和WAITED_HALF表示还在等待,但未超时
- OVERDUE表示已经超时。默认情况下,timeout是1分钟,但监测对象可以通过传参自行设定,譬如PKMS的Handler Checker的超时是10分钟
- 如果超时时间到了,还有HandlerChecker处于未完成的状态(OVERDUE),则通过getBlockedCheckersLocked()方法,获取阻塞的HandlerChecker,生成一些描述信息。
- 保存日志,包括一些运行时的堆栈信息,这些日志是我们解决Watchdog问题的重要依据。如果判断需要杀掉system_server进程,则给当前进程(system_server)发送signal 9。
只要Watchdog没有发现超时任务,HandlerChecker就会被不停的调度。
HandlerChecker的运作
public final class HandlerChecker implements Runnable {
public void scheduleCheckLocked() {
// Looper Checker中是不包含monitor对象的,判断消息队列是否处于空闲
if (mMonitors.size() == 0 && mHandler.getLooper().isIdling()) {
mCompleted = true;
return;
}
...
// 将Monitor Checker的对象置于消息队列之前,优先运行
mHandler.postAtFrontOfQueue(this);
}
@Override
public void run() {
// 依次调用Monitor对象的monitor()方法
for (int i = 0 ; i < size ; i++) {
synchronized (Watchdog.this) {
mCurrentMonitor = mMonitors.get(i);
}
mCurrentMonitor.monitor();
}
...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
总结
总体流程:
Watchdog是一个运行在system_server进程的名为”watchdog”的线程::
Watchdog运作过程,当阻塞时间超过1分钟则触发一次watchdog,会杀死system_server,触发上层重启;
mHandlerCheckers记录所有的HandlerChecker对象的列表,包括foreground, main, ui, i/o, display线程的handler;
mHandlerChecker.mMonitors记录所有Watchdog目前正在监控Monitor,所有的这些monitors都运行在foreground线程。
有两种方式加入Watchdog的监控:
- addThread():用于监测Handler对象,默认超时时长为60s.这种超时往往是所对应的handler线程消息处理得慢;
- addMonitor(): 用于监控实现了Watchdog.Monitor接口的服务.这种超时可能是”android.fg”线程消息处理得慢,也可能是monitor迟迟拿不到锁;
以下情况,即使触发了Watchdog,也不会杀掉system_server进程: * monkey: 设置IActivityController,拦截systemNotResponding事件, 比如monkey. * hang: 执行am hang命令,不重启; * debugger: 连接debugger的情况, 不重启;
输出信息
watchdog在check过程中出现阻塞1分钟的情况,则会输出:
AMS.dumpStackTraces:输出system_server和3个native进程的traces
- 该方法会输出两次,第一次在超时30s的地方;第二次在超时1min;
WD.dumpKernelStackTraces,输出system_server进程中所有线程的kernel stack;
- 节点/proc/%d/task获取进程内所有的线程列表
- 节点/proc/%d/stack获取kernel的栈
doSysRq, 触发kernel来dump所有阻塞线程,输出所有CPU的backtrace到kernel log;
- 节点/proc/sysrq-trigger
dropBox,输出文件到/data/system/dropbox,内容是trace + blocked信息
杀掉system_server,进而触发zygote进程自杀,从而重启上层framework。
Handler方式
Watchdog监控的线程有:默认地DEFAULT_TIMEOUT=60s,调试时才为10s方便找出潜在的ANR问题。
atchdog监控的线程有:默认地DEFAULT_TIMEOUT=60s,调试时才为10s方便找出潜在的ANR问题。
| 线程名 | 对应handler | 说明 |
|---|---|---|
| system_server | new Handler(Looper.getMainLooper()) | 当前主线程 |
| android.fg | FgThread.getHandler | 前台线程 |
| android.ui | UiThread.getHandler | UI线程 |
| android.io | IoThread.getHandler | I/O线程 |
| android.display | DisplayThread.getHandler | display线程 |
| ActivityManager | AMS.MainHandler | AMS构造函数中使用 |
| PowerManagerService | PMS.PowerManagerHandler | PMS.onStart()中使用 |
目前watchdog会监控system_server进程中的以上7个线程,必须保证这些线程的Looper消息处理时间不得超过1分钟。
Monitor方式
能够被Watchdog监控的系统服务都实现了Watchdog.Monitor接口,并实现其中的monitor()方法。运行在android.fg线程, 系统中实现该接口类主要有:
- ActivityManagerService
- WindowManagerService
- InputManagerService
- PowerManagerService
- NetworkManagementService
- MountService
- NativeDaemonConnector
- BinderThreadMonitor
- MediaProjectionManagerService
- MediaRouterService
- MediaSessionService
- BinderThreadMonitor