第2章 信息的表示和处理
参考资料
信息的表示和处理
三种最重要的数字表示:
- 无符号(unsigned)编码基于传统的二进制表示法,表示大于或者等于零的数字;
- 补码(two’s-complement)编码是表示有符号整数的最常见的方式,有符号整数就是可以为正或者负的数字;
- 浮点数(floating-point)编码是表示实数的科学记数法的以2为基数的版本。
计算机的表示法是用有限数量的位来对一个数字编码,以至于结果太大会产生溢出。
整数运算和浮点数运算会有不同的数学属性——它们处理数字表示有限性的方式不同
- 整数的编码数值范围小,但是精确
- 浮点数编码数值范围大,但是只是近似。
信息存储
大多数计算机使用8位的块,或者字节,作为最小的可寻址的内存单位,而不是访问内存中的单独的位。
十六进制表示法
一个字节由8位组成。在二进制表示法中,它的值域是 00000000~11111111。如果用十进制表示则为0~255。但是对于位模式而言,两种表示方法都不合适,进而采用十六进制的方式表示位模式。

十六进制以 0x 开头。 A:10;C:12;F:15
字数据大小
每个计算机有对应的字长,虚拟地址用一个字来编码,所以字长决定了虚拟地址空间的大小。64 位机器的指针类型长度为 8 字节
32位机器的虚拟地址空间为 4GB,64 位字长的虚拟地址空间位 16 EB。(大多数64位机器也可以运行32位机器编译的程序,向后兼容。gcc -m32 proc.c gcc -m64 proc.c)
int32_t 和 int64_t 类型分别为 4 字节和 8 字节,不受机器影响。使用确定大小的整数类型很有用。
对 32 位和 64 位机器而言,char、short、int、long long 长度都是一样的,为 1,2,4,8。long 的长度不一样。float 和 double 的长度一样,分别为 4,8
程序对 char 有无符号一般不敏感。
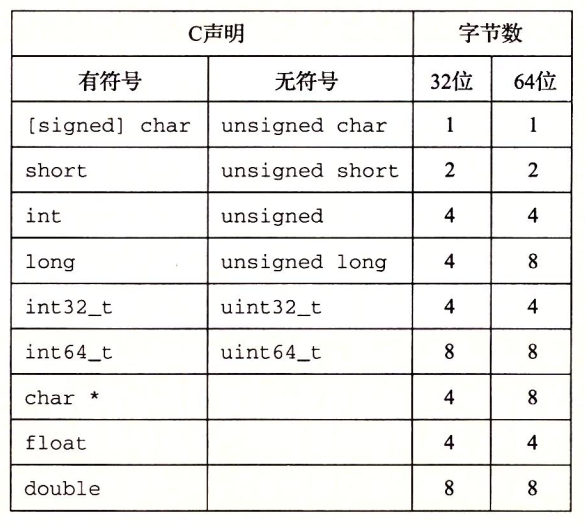
寻址和字节顺序
对于跨越多字节的对象,它的地址是它所用字节中的最小地址。
两种字节存储法:
- 小端法:数字的低位在前(前就是最小地址)
- 大端法:数字的高位在前
大多数 Intel 都是小端法,不是所有。
假设变量x的类型为int,位于地址0x100处,它的十六进制值为0x01234567。地址范围0x100~0x103的字节顺序依赖于机器的类型。
表示字符串
C 语言字符串是以 null 字符结尾的字符数组,即 '\0'
ASCII 字符适合编码英文文档。
Unicode(UTF-8)使用 4 字节表示字符,一些常用的字符只需要 1 或 2 个字节。所有 ASCII 字符在 UTF-8 中是一样的。
JAVA 使用 UTF-8 来编码字符串。
表示代码
二进制代码是不兼容的,一般无法在不同机器间移植。(不同的机器类型使用不同的且不兼容的指令和编码方式,即使是完全一样的进程,运行在不同的操作系统上也会有不同的编码规则) 从机器的角度看,程序就是一个字节序列,机器没有关于原始源程序的任何信息。
布尔代数
二进制值时计算机编码、存储和操作信息的核心,所以围绕着数值0和1的研究以及演化出了丰富的数学知识体系。
布尔代数是在 0 和 1 基础上的定义可以把字节看作是一个长为 8 的位向量。
位向量的一个应用是表示有限集合。如位向量 [0110 1001] 表示集合 A = {0,3,5,6}。
C 语言中的位级运算
位运算的常见应用是实现掩码。掩码表示从一个字中选出的位的集合,如掩码 0xFF 表示一个字的低 8 位。
表达式 ~0 可以生成一个全 1 的掩码,不管机器的字大小是多少。
C 语言中的逻辑运算
逻辑运算符 && 和 || 如果第一个参数就能确定结果,就不再计算第二个参数
C 语言中的移位运算
左移 k 位丢掉最高的 k 位,并在右端补 k 个 0。
右移分为逻辑右移和算术右移。逻辑右移左端补 0,算术右移左端补最高有效位的值。
一般都对有符号数使用算术右移,即补符号位的值。无符号数,只能是逻辑右移,即补 0
整数表示
无符号表示与补码表示:

有符号数到无符号数的转换会产生漏洞,避免错误的方法之一是绝不使用无符号数。
除了 C 以外很少有语言支持无符号整数,Java 就只支持有符号数。
整数数据类型
C语言支持多种整型数据类型——表示有限范围的整数。
32位机器数据类型范围:

64位机器数据类型范围:
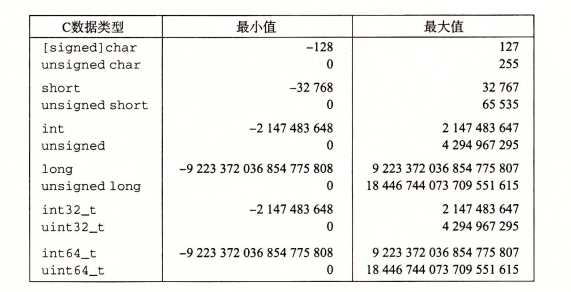
可以从上图看出,取值范围不对称——负数的范围比整数范围大1。
无符号数的编码
无符号表示、补码表示与数据的映射都是双射,即一一对应。
定义:

无符号数向量与整数的映射:
无符号数编码的唯一性:
B2Uw(Binary to Unsigned)是一个双射,即存在与之对应的U2Bw(Unsigned to Binary )函数,使得整数映射为对应的位模式向量。
补码编码
补码的定义实际就是将字的最高有效位解释为负权。
定义:
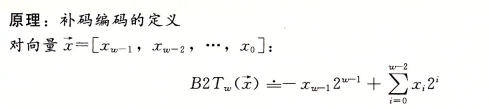
补码向量与整数的映射: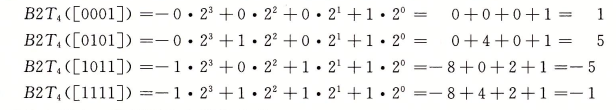
无符号数编码的唯一性:
B2Tw(Binary to two's complement)是一个双射,即存在与之对应的T2Bw(two's complement to Binary )函数,使得整数映射为对应的位模式向量。

关注点:
- 补码的范围是不对称的:|TMin| = | TMax | + 1
- 最大的无符号数值比补码的最大值的两倍大1 :Umaxw = 2 TMaxw + 1
C语言标准并没有要求要用补码形式来表示有符号整数,但是几乎所有的机器都是这么来处理的,这样才可以保证程序在机器和编译器上的可移植性。
有符号数和无符号数之间的转换
在有符号数与无符号数之间进行强制类型转换的结果是保持位值不变,只改变解释位的方式。
例如:
short int v = -12345;
unsigned short uv = (unsigned short) v;
printf("v= %d", uv = %u\n", v, uv);
2
3
在一台采用补码的机器上,上述代码会产生如下输出:
v = -12345, uv = 53191
-12345的16位补码表示 和 53191 的16位无符号表示完全一致:
1100 1111 1100 0111
2
3
4
补码转无符号数:
 无符号数转补码:
无符号数转补码:
C 语言中的有符号数和无符号数
C 语言中有符号数和无符号数相加减,有符号被转换成无符号。
扩展一个数字的位表示
扩展无符号数使用零扩展,即在最高位前加 0
扩展有符号数使用符号扩展,即在最高位前加最高有效位的值
截断数字
对一个 w 位的数字截断为一个 k 位数字,将丢弃高 w-k 位。
对于无符号数而言,截断后的数字实际上等于 w mod 2^k,即取余。
整数运算
无符号加法
考虑溢出,C 语言不会将溢出作为错误发出信号:
 对任意的 x+y,s = (x+y) % 2^w
对任意的 x+y,s = (x+y) % 2^w
- 溢出的结果:和小于两个加数
- 检验溢出的方式:如果 s<x,说明溢出
无符号数求反:
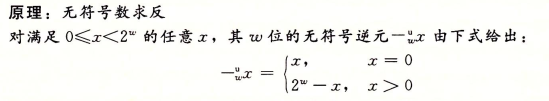
补码加法
 正溢出的结果是负数,负溢出的结果是正数。
正溢出的结果是负数,负溢出的结果是正数。
检验溢出的方式:当 x,y>0 而 s<=0 是正溢出;当 x,y<0 而 s>=0 是负溢出
补码的非
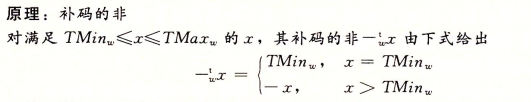
补码非的位级表示:对每一位求补,结果再加 1
计算补码非的第二种方法:假设 k 是最右边的 1 的位置,对 k 左边的所有位取反
无符号乘法

补码乘法

可以认为补码乘法和无符号乘法的位级表示是一样的 C语言在运算时将 x,y 视为无符号数进行乘法运算,结果取余后将其按补码方式解释 补码乘法的积 m = (x*y) % 2^w
乘以常数
大多数机器上,整数乘法需要 10 个或更多的时钟周期,而加法、减法、位级运算和移位只需要 1 个时钟周期。
编译器对整数乘法进行优化的方式:用移位和加法或减法运算的组合来代替常数因子的乘法。
左移 k 位等于乘以 2^k:
如 x * 14 = (x<<3)+(x<<2)+(x<<1) = (x<<4)-(x<<2) 判断如何移动的方式很简单:14 的位级表示为 1110,所以分别左移 3,2,1
除以 2 的幂
大多数机器上,整数除法更慢,需要 30 个或更多的始终周期。
(只有)除以 2 的幂可以用移位运算来代替,无符号采用逻辑右移,补码采用算术右移 对于有符号数而言,算术右移的结果相当于进行除法运算后向下舍入。
使用 (x+(1<<k)-1)>>k 的结果相当于进行除法运算然后向零舍入
代码实现
(x<0 ? x+(1<<k)-1 : x) >> k;
关于整数运算的最后思考
补码使用了与无符号算术运算相同的位级实现,包括加法、减法、乘法甚至除法。都有完全一样或非常类似的位级行为。
浮点数
浮点数对于非常大,非常接近零,近似值计算都很有用
二进制小数
小数的二进制表示法只能表示那些能够写为 x * 2^w 的数,其他的数都是近似表示。
x 必须可以由形如 2^i + 2^j + ... + 2^n 的多项式表示。
浮点运算的不精确性可能产生严重后果。
IEEE 浮点表示
IEEE 浮点标准的表示形式为:

在对浮点数的位编码时:
一个单独的符号位编码直接编码 S
- k 位的阶码字段 e 编码 E;float 中 k=8,double 中 k=11
- n 位的小数字段 f 编码 M;float 中 n=23,double 中 n=52
E 和 M 的编码方式分为三种情况:
- 规格化的值:阶码字段即不全为 0 也不全为 1 时属于规格化值(0001~1110)
- 阶码字段解释方式:E = e - (2^(k-1)-1);如 k=4 时,E 的范围是 -6~7;单精度为 -126~127
- 小数字段解释方式:M = 1 + f
- 非规格化的值:阶码字段全为 0 时属于非规格化形式
- 阶码字段解释方式:E = 1 - (2^(k-1)-1);与规格化值中 e = 1 时的 E 相同
- 小数字段解释方式:M = f
- 特殊值:阶码字段全为 1 时,分两种情况:
- 小数字段全为 0:表示无穷
- 小数字段非零:表示 NaN。比如 ∞-∞ 的结果就返回 NaN
数字示例
0 有 +0.0 和 -0.0 两种表示方式
最大非规格化数到最小规格化数的过渡是平滑的。 浮点数能够使用正数排序函数来排序,即浮点数的位级表示当用整数方式来解释时是顺序的(正数升序负数降序)。
浮点数可表示的数的分布是不均匀的,越接近零时越稠密 几个特殊的值的位级表示:
+0.0 全为 0
最小的正非规格化值:最低有效位为 1,其他为 0 最大的非规格化值:小数字段全为 1,其他为 0 最小的正规格化值:阶码字段最低位为 1,其他为 0 最大的规格化值:阶码字段最低位为 0,符号位为 0,其他为 1
舍入
因为范围和精度有限,浮点运算只能近似表示实数运算。
在浮点数的近似匹配上,IEEE 浮点格式定义了四种舍入方式(默认第一种):
- 向偶数舍入(向最接近的值舍入):非中间值 (0.5) 四舍五入,中间值向偶数舍入。
- 向零舍入
- 向下舍入
- 向上舍入
- 向偶数舍入可以计算一组数的平均数时避免统计偏差。
实际上这种舍入是发生在二进制小数上的。
浮点运算
IEEE 标准定义 1/-0 = -∞,1/+0 = +∞
浮点运算是可交换不可结合也不可分配的。
例如:
(3.14 + 1e10) - 1e10 —— > 0.0 因为舍入
3.14 + (1e10 - 1e10) —— > 3.14
即不满足结合律
2
3
浮点加法满足加法和乘法上的单调性。如果 a>=b,则 x+a >= x+b
缺乏结合性和分配性会使一些简单问题变得很复杂
C 语言中的浮点数
在 int、float、double 间进行强制类型转换时的几种情况:
- int 到 float:不会溢出,可能舍入
- int 或 float 到 double:不会溢出也不会舍入
- double 到 float:可能溢出和舍入
- float 或 double 到 int:向零舍入,很大时可能溢出,很接近零时也可能溢出。当从浮点转换到整数时如果溢出,转变结果都为 [1000],因此一个正浮点可能得到一个负整数
把大的浮点数转换为整数是一种常见的错误。要小心地使用浮点运算。
总结
- 计算机将信息编码为位(比特),通常组织成字节序列。有不同的编码方式(无符号、补码、浮点)来表示整数、实数和字符串。
- 64位字长的机器普及,突破了32位程序4GB虚拟地址空间的限制。(虚拟地址用一个字来编码,所以字长决定了虚拟地址空间的大小)
- 大多数机器对整数使用补码编码,而对浮点数使用IEEE标准编码,在位级上理解这些编码,并且理解算术运算的数学特性,十分重要。
- 无符号数和补码的运算都满足整数运算的许多其他属性,包括结合律、交换律和分配律的属性。