第4章 数据编码与演化
概述
应用程序不断随时间而变化,更改或添加新功能往往伴随着存储数据的变化,包括新增字段或修改原先字段范围等。一个大型的应用系统,代码迭代需要保证双向的兼容性。
向后兼容和向前兼容
- 向后兼容
- 较新的代码可以读取旧代码编写的数据。
- 向前兼容
- 较旧的代码可以读取新代码编写的数据。
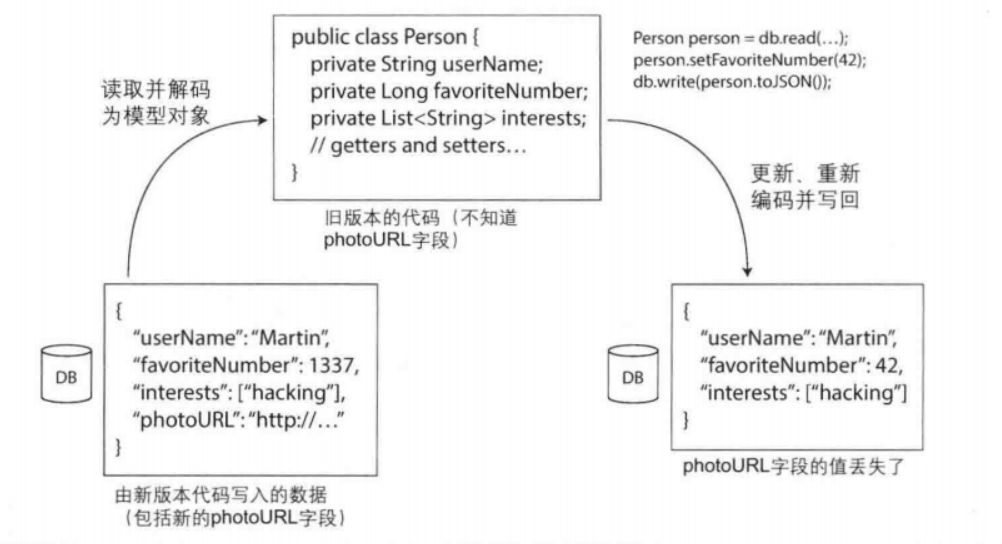
向后兼容通常不难实现:作为新代码的作者,清楚旧代码所编写的数据格式,因此可以比较明确地处理这些旧数据(如果需要,只需保留旧的代码来读取旧的数据)。向前兼容可能会比较棘手,它需要旧代码忽略新版本的代码所做的添加。
数据编码格式
程序通常使用(至少)两种不同的数据表示形式:
- 在内存中,数据保存在对象、结构体、列表、数组、哈希表和树等结构中。这些数据结构针对CPU的高效访问和操作进行了优化(通常使用指针)。
- 将数据写人文件或通过网络发送时,必须将其编码为某种自包含的字节序列(例如JSON文档)。
因此,在这两种表示之间需要进行类型的转化。从内存中的表示到字节序列的转化称为编码(或序列化),相反的过程称为解码(或反序列化)。
语言特定的格式
许多编程语言都内置支持将内存中的对象编码为字节序列。例如,Java有java.io.Serializable, Ruby有Marshal, Python有pickle等。
这也引入的一个问题,编码与特定语言绑定时,使用另外一种语言访问数据就变得困难。
JSON、XML和CSV都是文本格式,有着不错的可读性。字编码有很多模糊之处。在XML和CSV中,无法区分数字和碰巧由数字组成的字符串(除了引用外部模式)。JSON区分字符串和数字,但不区分整数和浮点数,并且不指定精度。
二进制编码
原始的JSON文档(81字节)

MessagePack(一种JSON的二进制编码),字节序列66字节
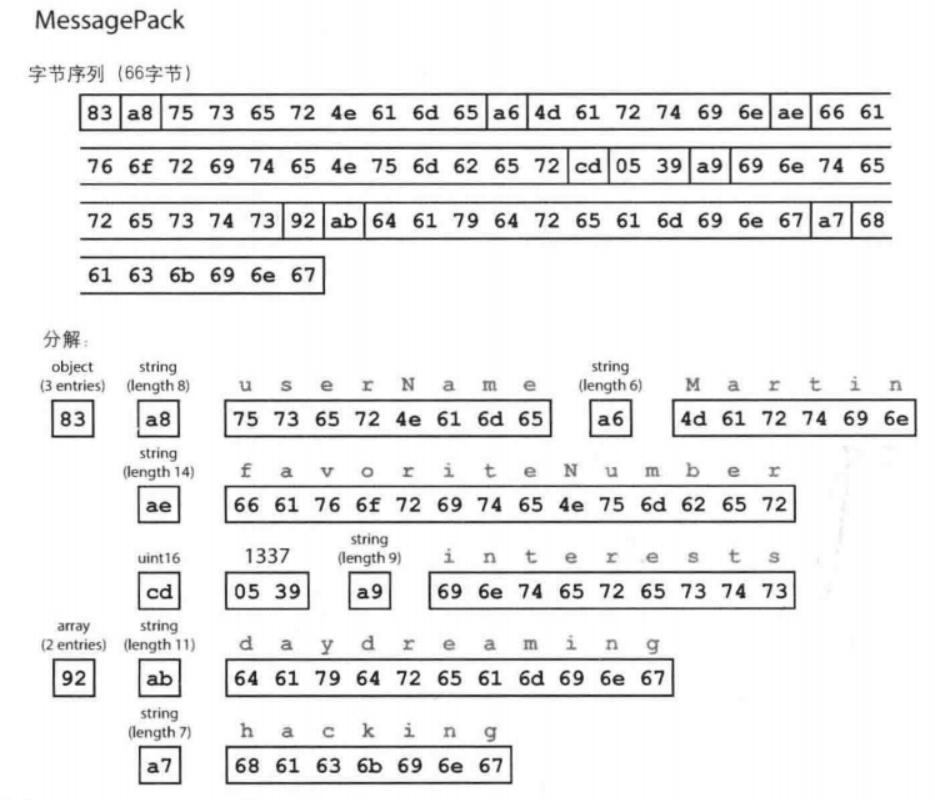
Apache Thrift 和Protocol Buffers(protobuf) 是基于相同原理的两种二进制编码库。Protocol Buffers最初是在Google开发的,Thrift最初是在Facebook开发的,并且都是在2007、2008年开源的。
Thrift和Protocol Buffers都需要模式来编码任意的数据。
Thrift接口定义语言(IDL)来描述模式,如下所示:
struct Person{
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
2
3
4
5
Protocol Buffers定义:
message Person{
required string user_name =1;
optional int64 favorite_number =2;
repeated string interests =3;
}
2
3
4
5
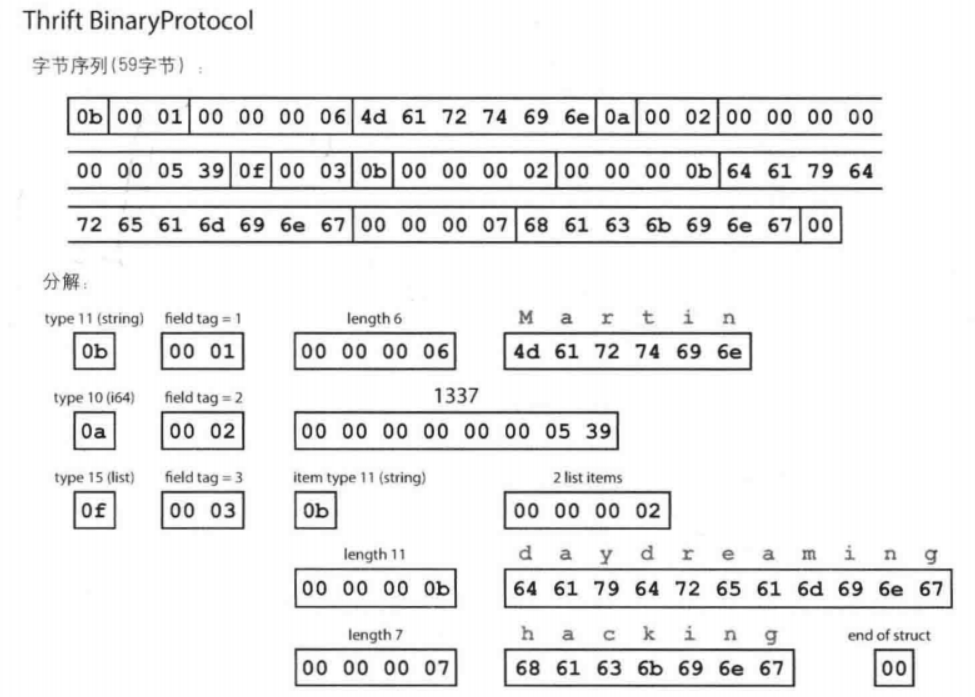
Thrift有两种不同的二进制编码格式,分别称为BinaryProtocol和CompactProtocol(通过将字段类型和标签号打包到单字节中,并使用可变长整数实现):
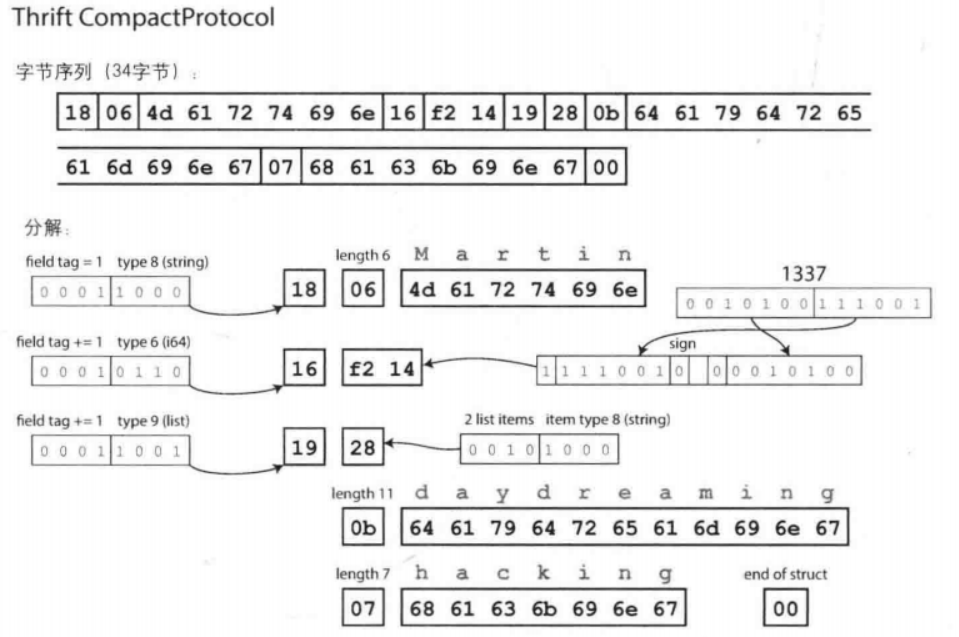
Protocol Buffers实现

字段标签和模式演化
- 添加字段到模式,则新增一个标签,如果旧代码读到不能识别的标签新数据则忽略,从而实现向前兼容。
- 将新增字段设置为可选,新代码读取旧数据可以通过,从而实现向后兼容。
数据类型和模式演化
数据类型变更,例如32位整数变成64位整数,向前兼容会出现数据截断。
数据流模式
基于数据库的数据流
将数据重写为新模式: 添加具体默认值为空的新列,而不重写现有数据。
基于服务的数据流: REST 和 RPC
Web的工作方式是:客户端(Web浏览器)向Web服务器发出请求,发出GET请求来下载HTML、css、JavaScript、图像等,发出POST请求提交数据到服务器。API包含一组标准的协议和数据格式(HTTP、URL、SSL/TLS、HTML等)。因为web浏览器、Web服务器和网站作者大多同意这些标准,所以可以使用任何浏览器访问任何网站。
客户端和服务端是相对的概念,对于Web应用服务器而言,是Web浏览器的服务端,但是Web应用服务器本身是数据库的客户端。
RPC方案的向前和向后兼容性处理:取决于具体编码技术。
如果不得不进行一些破坏兼容性的更改,则服务提供者往往会同时维护多个版本的服务API。
API版本管理如何工作? ———— 对于RESTful API,常用的方法是在URL或HTTP Accept头中使用版本号。对于使用API密钥来标识特定客户端的服务,另一种选择是将客户端请求的API版本存储在服务器上,并允许通过单独的管理接口更新该版本选项。
基于消息传递的数据流
- REST和RPC:其中一个进程通过网络向另一个进程发送请求,并期望尽快得到响应
- 数据库:其中一个进程写人编码数据,另一个进程在将来某个时刻再次读取该数据
与直接RPC相比,使用消息代理有以下几个优点:
- 如果接收方不可用或过载,它可以充当缓冲区,从而提高系统的可靠性。
- 它可以自动将消息重新发送到崩溃的进程,从而防正消息丢失。
- 它避免了发送方需要知道接收方的IP地址和端口号
- 它支持将一条消息发送给多个接收方。
- 它在逻辑上将发送方与接收方分离(发送方只是发布消息,并不关心谁使用它们)
然而,与RPC的差异在于,消息传递通信通常是单向的:发送方通常不期望收到对其消息的回复。
消息代理的使用方式:一个进程向指定的队列或主题发送消息,并且代理确保消息被传递给队列或主题的一个或多个消费者或订阅者。在同一主题上可以有许多生产者和许多消费者。
← 第3章 数据存储与检索 第5章 数据复制 →