第五章:关联式容器 hashtable
hashtable概述
hashtable在插入,删除,搜寻等操作上具有"常数平均时间"的表现,而且这种表现以统计为基础,不依赖输入元素的随机性。(二叉搜索树具有对数平均时间的表现,是建立在输入数据有足够随机性的基础上。)
hash table 可提供对任何有名项的存取操作和删除操作。由于操作对象是有名项,所以hashtable可被视为一种字典结构(dictionary)。举个例子,如果所有元素时16-bits且不带有正负号的整数,范围为0-65535,则可以通过配置一个array拥有65536个元素,对应位置记录元素出现个数,添加A[i]++,删除A[i]--,查找A[i]==0判断。但是进一步,如果所有元素是32-bits,那大小必须是2^32=4GB,那直接分配这么大的空间就不太实际。再进一步,如果元素时字符串,每个字符用7-bits数值(ASCII)表示,这种方法就更不可取了。
为了解决上述问题,引入了hash funtion的概念。hashfuntion可以将某一元素映射为一个“大小可接受之索引”,即大数映射成小数。hashtable通过hashfunction将元素映射到不同的位置,但当不同的元素通过hash function映射到相同位置时,便产生了"碰撞"问题.解决碰撞问题的方法主要有线性探测,二次探测,开链法等.
- 线性探测:当hash function计算出某个元素的插入位置,而该位置的空间已不可用时,循序往下寻找下一个可用位置(到达尾端时绕到头部继续寻找),会产生primary clustering(一次聚集)问题。
- 二次探测:当hash function计算出某个元素的插入位置为H,而该位置的空间已经被占用,就尝试用H+1²、H+2²…,会产生secondary clustering(二次聚集)问题。
- 开链:在每一个表格元素中维护一个list:hash function为我们分配某个list,在那个list上进行元素的插入,删除,搜寻等操作.SGI STL解决碰撞问题的方法就是此方法。
下面以开链法完成hash table的图形表述,hash table 表格内的元素为桶子(bucket),每个bucket都维护一个链表,来解决哈希碰撞,如下所示:
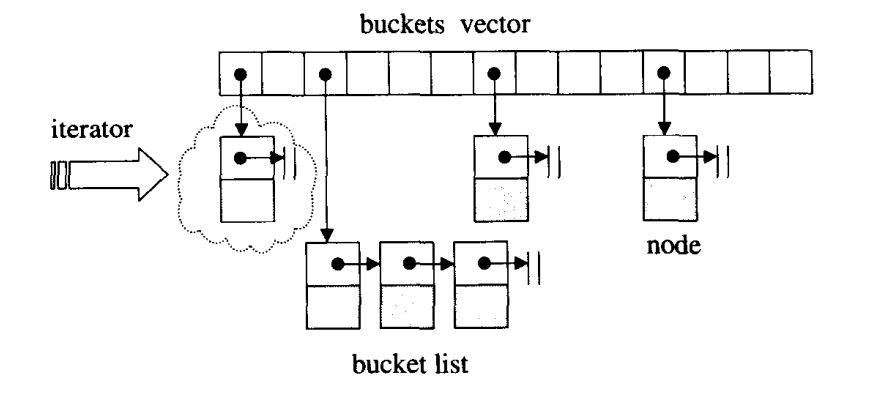
下面看一下 hashtable 的定义:
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>
class hashtable {
...
private:
hasher hash; //哈希函数
key_equal equals; //判断key值是否相等
ExtractKey get_key; //从value中获取key
typedef __hashtable_node<Value> node;
vector<node*,Alloc> buckets; //桶
size_type num_elements; //元素个数
...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
首先是三个仿函数,这些仿函数都是从模板参数指定的,然后在构造函数中赋值:
- hash:用于获取 key 对应的哈希值,以确定要放到哪一个 bucket 中
- equals:用于判断 key 是否相等
- get_key:用于从 value 中取得 key,前面说过 value = key + data
接下来是 buckets 和 num_elements:
- buckets:维护哈希表的 bucket,是一直指针数组,每个元素都是 node* 类型
- num_elements:元素的个数
下面再来看哈希表中每个节点的定义:
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};
2
3
4
5
6
- next:指向下一个节点的指针
- val:该节点对应的value(key+data)
hashtable的迭代器
hashtable 的迭代器定义如下:
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
/* STL迭代器的设计规范 */
typedef forward_iterator_tag iterator_category;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef Value& reference;
typedef Value* pointer;
node* cur; //迭代器目前所指之节点
hashtable* ht; //保持容器的连结关系
...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
hashtable迭代器没有后退操作(operator--),只有前进操作(operator++),处理逻辑:首先跳转到下一个节点,如果该节点不为空,那么就返回。如果为空,表示该bucket链表到达底部,那么就跳转到下一个不为空的bucket,首先获取当前 bucket 的位置,然后往后移动,直到 bucket 不为空。
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
cur = cur->next; //跳到下一个节点
if (!cur) { //如果这个 bucket 链表到达尾部,那么跳到下一个 bucket
size_type bucket = ht->bkt_num(old->val); //当前在哪个bucket中
/* 跳转到下一个不为空的bucket */
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket];
}
return *this;
}
//版本1:接受实值(value)和buckets个数
size_type bkt_num(const value_type& obj, size_t n) const
{
return bkt_num_key(get_key(obj), n);
}
//版本2:只接受实值
size_type bkt_num(const value_type& obj) const
{
return bkt_num_key(get_key(obj));
}
//版本3:只接受键值
size_type bkt_num_key(const key_type& key) const
{
return bkt_num_key(key,buckets.size());
}
//版本3:接受键值和buckets个数
size_type bkt_num_key(const key_type& key, size_t n) const
{
return hash(key) % n;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
hashtable的操作
构造函数
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql)
: hash(hf), equals(eql), get_key(ExtractKey()), num_elements(0)
{
initialize_buckets(n);
}
2
3
4
5
6
7
首先初始化三个仿函数,然后调用 initialize_buckets 来初始化hashtable。initialize_buckets 函数定义如下:
void initialize_buckets(size_type n)
{
const size_type n_buckets = next_size(n);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, (node*) 0);
num_elements = 0;
}
2
3
4
5
6
7
首先确定 bucket 的数量,然后通过 reserve 初始化,然后再通过 insert 将所有的 bucket 初始化为 NULL。最后将元素个数填为0(其中的 buckets 是一个 vector)。
析构函数
~hashtable() { clear(); }
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear()
{
for (size_type i = 0; i < buckets.size(); ++i) { //遍历所有的bucket
node* cur = buckets[i];
/* 遍历每个bucket链表 */
while (cur != 0) {
/* 删除该链表上所有的节点 */
node* next = cur->next;
delete_node(cur);
cur = next;
}
buckets[i] = 0;
}
num_elements = 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
首先遍历所有的 bucket,然后遍历对应 bucket 链表的所有元素,调用 delete_node 将每个节点释放。delete_node 的定义如下:
//首先析构对象,然后再释放内存
void delete_node(node* n)
{
destroy(&n->val);
node_allocator::deallocate(n);
}
2
3
4
5
6
插入元素
hashtable 只支持 insert 方法,有两个 insert,一个是 insert_unique,不允许键值重复,一个是 insert_equal ,允许键值重复。
insert_unique
插入元素,不允许键值重复:
pair<iterator, bool> insert_unique(const value_type& obj)
{
resize(num_elements + 1); //确保 bucket 的数目大于元素个数
return insert_unique_noresize(obj);
}
2
3
4
5
首先调用 reseize,确保 bucket 的数目大于元素的个数。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint)
{
const size_type old_n = buckets.size(); //获取旧的bucket个数
if (num_elements_hint > old_n) { //如果元素个数大于bucket个数,扩展bucket
const size_type n = next_size(num_elements_hint); //获取下一个扩展的bucket个数
if (n > old_n) {
vector<node*, A> tmp(n, (node*) 0); //定义一个临时的vector
/* 将旧的bucket搬到新的bucket中 */
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket];
while (first) { //遍历对应的bucket,将所有元素插入到新的bucket中
size_type new_bucket = bkt_num(first->val, n); //新的bucket位置
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
}
/* 交换两个容器的内容 */
buckets.swap(tmp);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
如果元素个数大于bucket个数,那么就需要进行扩容,首先通过 next_size 获取下一个应该扩容的bucket个数。next_size 定义如下:
//表格大小必须为质数,从下述28个质数中取最接近的
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473ul, 4294967291ul
};
/* 获取桶的数量 */
inline unsigned long __stl_next_prime(unsigned long n)
{
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n); //>=
return pos == last ? *(last - 1) : *pos;
}
size_type next_size(size_type n) const { return __stl_next_prime(n); }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
从定义好的数组中,找到第一个大于等于指定值得数。bucket 个数得所有取值定义在 __stl_prime_list 数组中,接下俩回到 resize 函数。在获取扩容的bucket个数后,定义一个临时的buckets,然后遍历旧的bucket,获取每个元素新的哈希值,然后插入到新的buckets对应的位置中,最后交换两个buckets。分析完 resize 函数,我们继续回到 insert_unique 函数。insert_unique 调用 resize 后,会调用 insert_unique_noresize 来插入元素,其定义如下:
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::iterator, bool>
hashtable<V, K, HF, Ex, Eq, A>::insert_unique_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); //计算得到该对象应该存放在哪个bucket
node* first = buckets[n]; //得到指定的bucket
/* 遍历bucket链表,如果找到相同的key,则插入失败 */
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj))) //如果找到相等的键值,那么就退出
return pair<iterator, bool>(iterator(cur, this), false);
/* 否则生成新节点,插入到指定的bucket中 */
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return pair<iterator, bool>(iterator(tmp, this), true);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
insert_equal
插入元素,运行键值重复:
iterator insert_equal(const value_type& obj)
{
resize(num_elements + 1); //确保 bucket 的数目大于元素个数
return insert_equal_noresize(obj);
}
2
3
4
5
首先调用 resize 函数,确保桶的数量大于元素个数,然后调用 insert_equal_noresize 插入元素。insert_equal_noresize 的定义如下:
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::iterator
hashtable<V, K, HF, Ex, Eq, A>::insert_equal_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); //找到指定的bucket
node* first = buckets[n];
/* 遍历对应的bucket链表,如果找到key相等的节点,那么就在此处插入 */
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj))) {
node* tmp = new_node(obj);
tmp->next = cur->next;
cur->next = tmp;
++num_elements;
return iterator(tmp, this);
}
/* 如果没有找到相等的节点,就在bucket链表头插入 */
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return iterator(tmp, this);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
首先确定要在哪一个bucket插入,然后遍历bucket链表,如果找到相等的节点,那么就在该节点处插入。否则,在bucket链表头插入。
删除元素
首先找到指定的bucket,然后从第二个元素开始遍历,如果节点的 key 等于指定的 key,将将其删除。最后再检查第一个元素的 key,如果等于指定的 key,那么就将其删除。
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::size_type
hashtable<V, K, HF, Ex, Eq, A>::erase(const key_type& key)
{
const size_type n = bkt_num_key(key);
node* first = buckets[n];
size_type erased = 0;
if (first) {
node* cur = first;
node* next = cur->next;
while (next) {
if (equals(get_key(next->val), key)) {
cur->next = next->next;
delete_node(next);
next = cur->next;
++erased;
--num_elements;
}
else {
cur = next;
next = cur->next;
}
}
if (equals(get_key(first->val), key)) {
buckets[n] = first->next;
delete_node(first);
++erased;
--num_elements;
}
}
return erased;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
hashtable运用实例
// file: 5hashtable-test.cpp
// #include <hash_set> // for hashtable
#include <backward/hashtable.h> // for hashtable in mingw c++
#include <iostream>
using namespace std;
int main() {
// hash-table
// <value, key, hash-func, extract-key, equal-key, allocator>
// note: hash-table has no default ctor
__gnu_cxx::hashtable<int,
int,
hash<int>,
_Identity<int>,
equal_to<int>,
allocator<int>>
iht(50, hash<int>(), equal_to<int>()); // 指定50个buckets与函数对象
cout << iht.size() << endl;
cout << iht.bucket_count() << endl; // 第一个质数
cout << iht.max_bucket_count() << endl; // 最后一个质数
iht.insert_unique(59);
iht.insert_unique(63);
iht.insert_unique(108);
iht.insert_unique(2);
iht.insert_unique(53);
iht.insert_unique(55);
cout << iht.size() << endl;
// 声明hashtable迭代器
// __gnu_cxx::hashtable<int,
// int,
// hash<int>,
// _Identity<int>,
// equal_to<int>,
// allocator<int>>
// ::iterator ite = iht.begin();
// 使用auto可以避免上述长串,注意auto做函数返回类型时不会是引用
auto ite = iht.begin();
// 使用迭代器遍历hashtable输出所有节点值
for (int i = 0; i < iht.size(); ++i, ++ite)
cout << *ite << ' ';
cout << endl;
// 遍历所有buckets,如果节点个数不为0则打印
for (int i = 0; i < iht.bucket_count(); ++i) {
int n = iht.elems_in_bucket(i);
if (n!=0)
cout << "bucket[" << i << "] has " << n << " elems." << endl;
}
// 验证bucket(list)的容量就是buckets vector的大小
for (int i = 0; i <= 47; ++i) {
iht.insert_equal(i);
}
cout << iht.size() << endl;
cout << iht.bucket_count() << endl;
// 遍历所有buckets,如果节点个数不为0则打印
for (int i = 0; i < iht.bucket_count(); ++i) {
int n = iht.elems_in_bucket(i);
if (n!=0)
cout << "bucket[" << i << "] has " << n << " elems." << endl;
}
// 使用迭代器遍历hashtable输出所有节点值
ite = iht.begin();
for (int i = 0; i < iht.size(); ++i, ++ite)
cout << *ite << ' ';
cout << endl;
cout << *(iht.find(2)) << endl;
cout << iht.count(2) << endl;
// template argument deduction/substitution failed
// iht.insert_unique(string("jjhou"));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
执行结果:
[root@192 5_STL_associated_container]# ./5_7_6_hashtable-test
0
53
4294967291
6
53 55 2 108 59 63
bucket[0] has 1 elems.
bucket[2] has 3 elems.
bucket[6] has 1 elems.
bucket[10] has 1 elems.
54
97
bucket[0] has 1 elems.
bucket[1] has 1 elems.
bucket[2] has 2 elems.
bucket[3] has 1 elems.
bucket[4] has 1 elems.
bucket[5] has 1 elems.
bucket[6] has 1 elems.
bucket[7] has 1 elems.
bucket[8] has 1 elems.
bucket[9] has 1 elems.
bucket[10] has 1 elems.
bucket[11] has 2 elems.
bucket[12] has 1 elems.
bucket[13] has 1 elems.
bucket[14] has 1 elems.
bucket[15] has 1 elems.
bucket[16] has 1 elems.
bucket[17] has 1 elems.
bucket[18] has 1 elems.
bucket[19] has 1 elems.
bucket[20] has 1 elems.
bucket[21] has 1 elems.
bucket[22] has 1 elems.
bucket[23] has 1 elems.
bucket[24] has 1 elems.
bucket[25] has 1 elems.
bucket[26] has 1 elems.
bucket[27] has 1 elems.
bucket[28] has 1 elems.
bucket[29] has 1 elems.
bucket[30] has 1 elems.
bucket[31] has 1 elems.
bucket[32] has 1 elems.
bucket[33] has 1 elems.
bucket[34] has 1 elems.
bucket[35] has 1 elems.
bucket[36] has 1 elems.
bucket[37] has 1 elems.
bucket[38] has 1 elems.
bucket[39] has 1 elems.
bucket[40] has 1 elems.
bucket[41] has 1 elems.
bucket[42] has 1 elems.
bucket[43] has 1 elems.
bucket[44] has 1 elems.
bucket[45] has 1 elems.
bucket[46] has 1 elems.
bucket[47] has 1 elems.
bucket[53] has 1 elems.
bucket[55] has 1 elems.
bucket[59] has 1 elems.
bucket[63] has 1 elems.
0 1 2 2 3 4 5 6 7 8 9 10 11 108 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 53 55 59 63
2
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
hashtable扩展
SGI hashtable定义了有数个现成的hash functions,针对hashtable进行取模运算,其中char,int,long等整数类型,是直接返回取模的值,但是对于字符串(const char*),设计了专门的转换函数:
inline size_t __stl_hash_string(const char *s)
{
unsigned long h = 0;
for( ; *s ; ++s)
h = 5*h + *s;
return size_t(h);
}
2
3
4
5
6
7
即除了整型和char *,SGI hashtable无法处理其他的元素类型,例如string,double,float等,需要用户自己定义。
hash_set
- hash_set以hashtable为底层机制,hash_set的操作几乎都是转调用hashtable的函数而已。
- hash_set的元素没有自动排序功能。(由于底层实现决定,RB-tree能自动排序,hashtable不能)
- hash_set的使用方式与set完全相同。
hash_map
- hash_map以hashtable为底层机制,hash_set的操作几乎都是转调用hashtable的函数而已。
- hash_map的元素没有自动排序功能。(由于底层实现决定,RB-tree能自动排序,hashtable不能)
- hash_map的使用方式与map完全相同。
hash_multiset
hash_multiset的特性及用法和multiset完全相同,唯一的差别在于它的底层机制是hashtable,元素不会被自动排序。
hash_multimap
hash_multimap的特性及用法和multimap完全相同,唯一的差别在于它的底层机制是hashtable,元素不会被自动排序。