树 - 概述
树在数据结构中至关重要,下面介绍几种常见树类型,包括二叉树、二叉搜索树、AVL树、红黑树和B-树等。
树
树是一种数据结构,它是n(n>=0)个节点的有限集。n=0时称为空树。n>0时,有限集的元素构成一个具有层次感的数据结构。从图论角度看,树等价于连通无环图。
区别于线性表一对一的元素关系,树中的节点是一对多的关系。
树具有以下特点:
- n>0时,根节点是唯一的,不可能存在多个根节点。
- 每个节点有零个至多个子节点;除了根节点外,每个节点有且仅有一个父节点。根节点没有父节点。
- 综合性
- 兼容vector和List的优点
- 兼容高效的查找、插入和删除
相关概念
树有许多相关的术语与概念,在学习树的结构之前,需要熟悉这些概念。
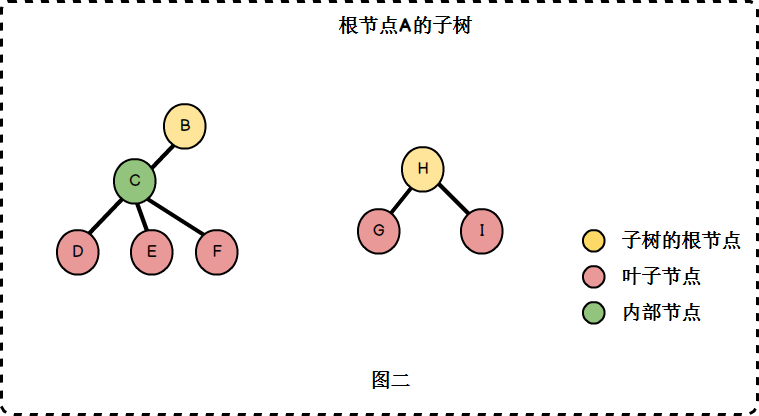
- 子树: 除了根节点外,每个子节点都可以分为多个不相交的子树。(图二)
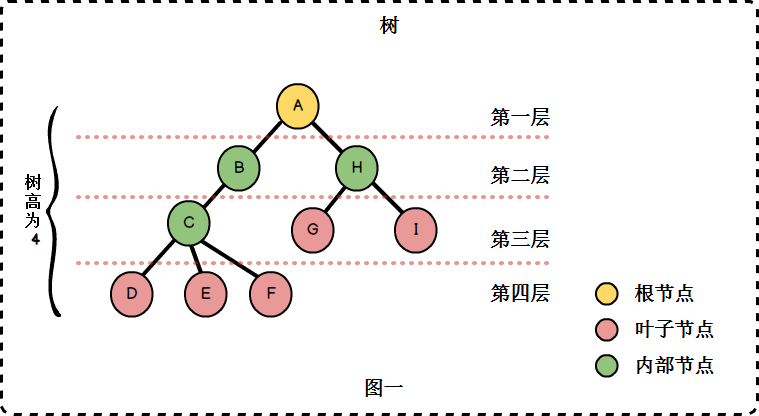
- 孩子与双亲: 若一个结点有子树,那么该结点称为子树根的"双亲",子树的根是该结点的"孩子"。在图一中,B、H是A的孩子,A是B、H的双亲。
- 兄弟: 具有相同双亲的节点互为兄弟,例如B与H互为兄弟。
- 节点的度: 一个节点拥有子树的数目。例如A的度为2,B的度为1,C的度为3.
- 叶子: 没有子树,也即是度为0的节点。
- 分支节点: 除了叶子节点之外的节点,也即是度不为0的节点。
- 内部节点: 除了根节点之外的分支节点。
- 层次: 根节点为第一层,其余节点的层次等于其双亲节点的层次加1.
- 树的高度: 也称为树的深度,树中节点的最大层次。
- 有序树: 树中节点各子树之间的次序是重要的,不可以随意交换位置。
- 无序树: 树种节点各子树之间的次序是不重要的。可以随意交换位置。
- 森林: 0或多棵互不相交的树的集合。例如图二中的两棵树为森林。
二叉树、完全二叉树、满二叉树
二叉树
二叉树:每个节点最多有两个子节点的树。
特点:
- 有序树,区分左子树与右子树,不可以随意交换子树位置。
- 叶子节点有0个字节点,根节点或者内部节点有一个或者两个字节点。
根据定义,一棵二叉树有5中基本形态:
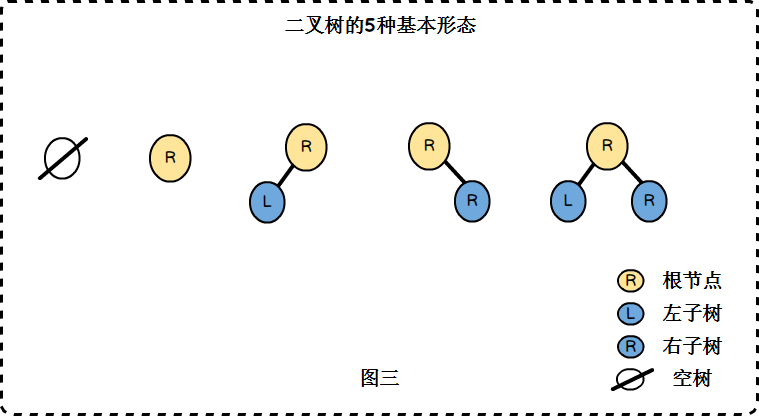
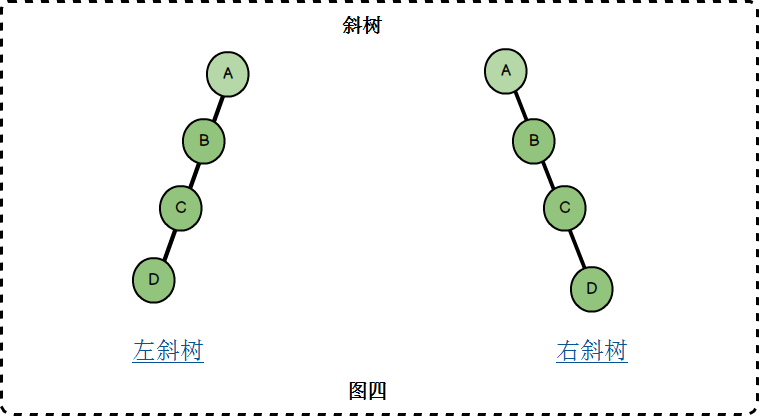
斜树
斜树:所有节点都只有左子树的二叉树叫做左斜树,所有节点都只有右子树的二叉树叫做右斜树。斜树已经退化成线性结构,二叉树在查找上表现出来优异性能在斜树得不到体现。
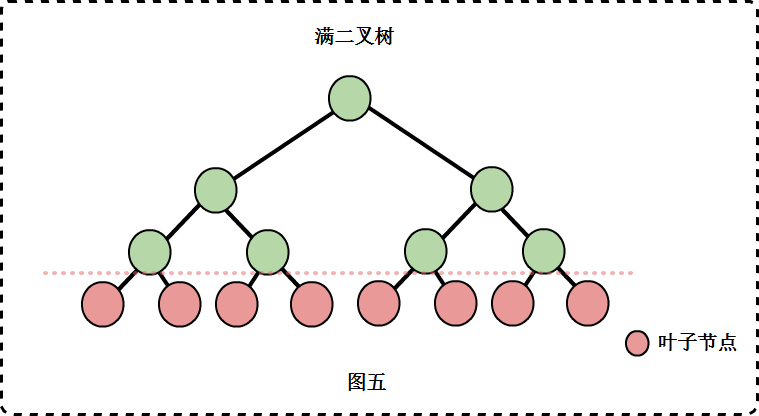
满二叉树
满二叉树要满足两个条件:
- 所有的节点都同时具有左子树和右子树。
- 所有的叶子节点都在同一层上。
在同样深度的二叉树中,满二叉树的节点数目是最多的,叶子数也是最多的。
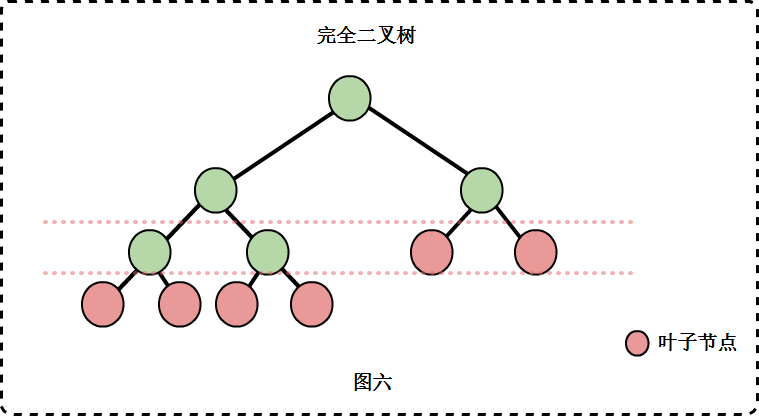
完全二叉树
在一棵二叉树中,只有最下两层的度可以小于2,并且最下一层的叶子节点集中出现在靠左的若干位置上。
或者这样定义:对一棵具有n个节点的二叉树按层序从左到右编序,二叉树树某个节点的编序与同样位置的满二叉树节点的编序相同如果所有节点都满足这个条件,则二叉树为完全二叉树。
从定义可以看出: 满二叉树一定是完全二叉树;完全二叉树不一定是满二叉树。
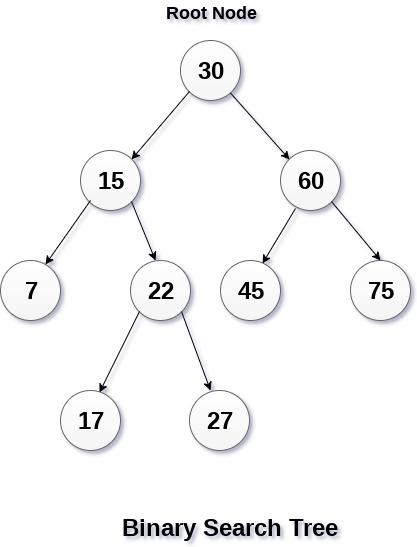
二叉搜索树 - BST
它或者是一棵空树,或者是具有下列性质的二叉树:
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉搜索树。
没有键值相等的节点。
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低为 O ( log n ) 。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、多重集、关联数组等。
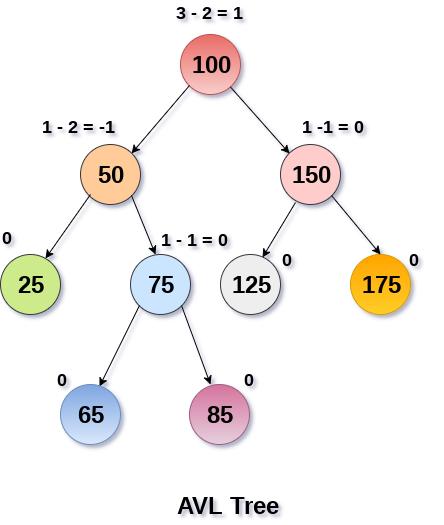
平衡二叉树 -AVL
平衡二叉树:当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
其中AVL树是最先发明的自平衡二叉查找树,是最原始典型的平衡二叉树。
平衡二叉树是基于二叉查找树的改进。由于在某些极端的情况下(如在插入的序列是有序的时),二叉查找树将退化成近似链或链,此时,其操作的时间复杂度将退化成线性的,即O(n)。所以我们通过自平衡操作(即旋转)构建两个子树高度差不超过1的平衡二叉树。
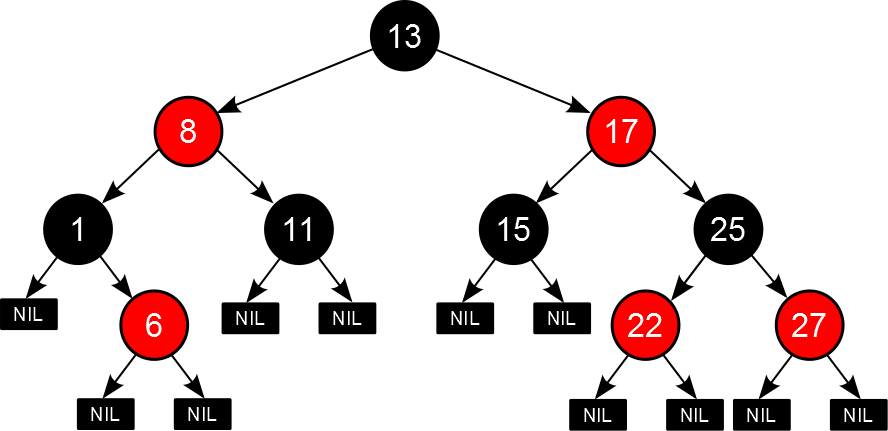
红黑树
红黑树也是一种自平衡的二叉查找树。
- 每个结点要么是红的要么是黑的。(红或黑)
- 根结点是黑的。(根黑)
- 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。(叶黑)
- 如果一个结点是红的,那么它的两个儿子都是黑的。(红子黑)
- 对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。(路径下黑相同)
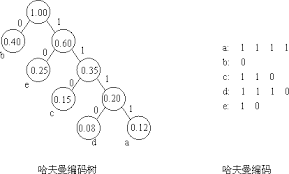
哈夫曼树(Huffman Tree)
哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。
一般可以按下面步骤构建:
- 将所有左,右子树都为空的作为根节点。
- 在森林中选出两棵根节点的权值最小的树作为一棵新树的左,右子树,且置新树的附加根节点的权值为其左,右子树上根节点的权值之和。注意,左子树的权值应小于右子树的权值。
- 从森林中删除这两棵树,同时把新树加入到森林中。
- 重复2,3步骤,直到森林中只有一棵树为止,此树便是哈夫曼树。
哈夫曼编码就是哈夫曼树的应用。即如何让电文中出现较多的字符采用尽可能短的编码且保证在译码时不出现歧义。
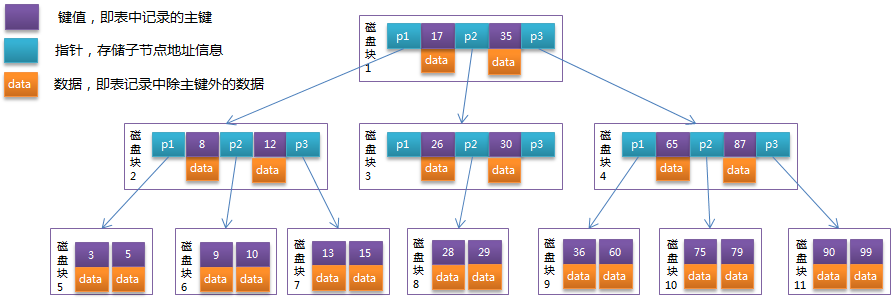
B树
B树是一种自平衡的树,能够保持数据有序。
这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。
B树,概括来说是一种自平衡的m阶树,与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。
定义如下:
- 根结点至少有两个子女。
- 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
- 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
- 所有的叶子结点都位于同一层。
- 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
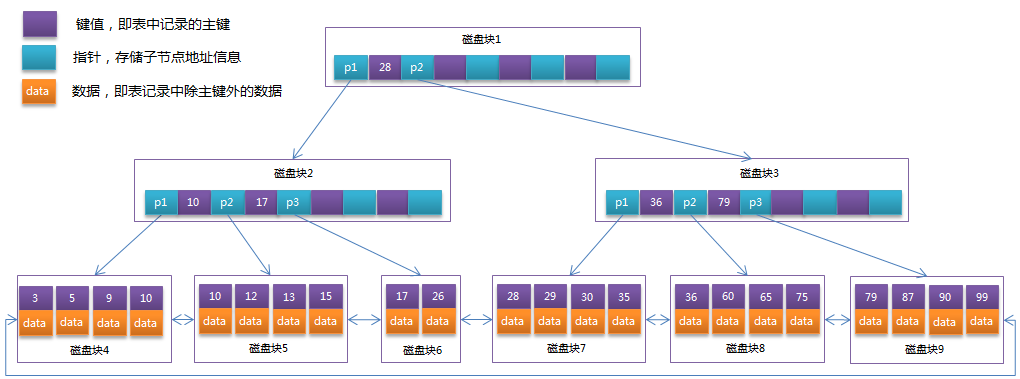
B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个3阶的B-Tree:
由于相比于磁盘IO的速度,内存中的耗时几乎可以省略,所以只要树的高度足够低,IO次数足够小,就可以提升查询性能。
B树的增加删除同样遵循自平衡的性质,有旋转和换位。
B树的应用是文件系统及部分非关系型数据库索引。
B+ 树
B+ 树是一种树数据结构,通常用于关系型数据库(如MySQL)和操作系统的文件系统中。
特点:
- 能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度
- B+ 树元素自底向上插入,这与二叉树恰好相反。
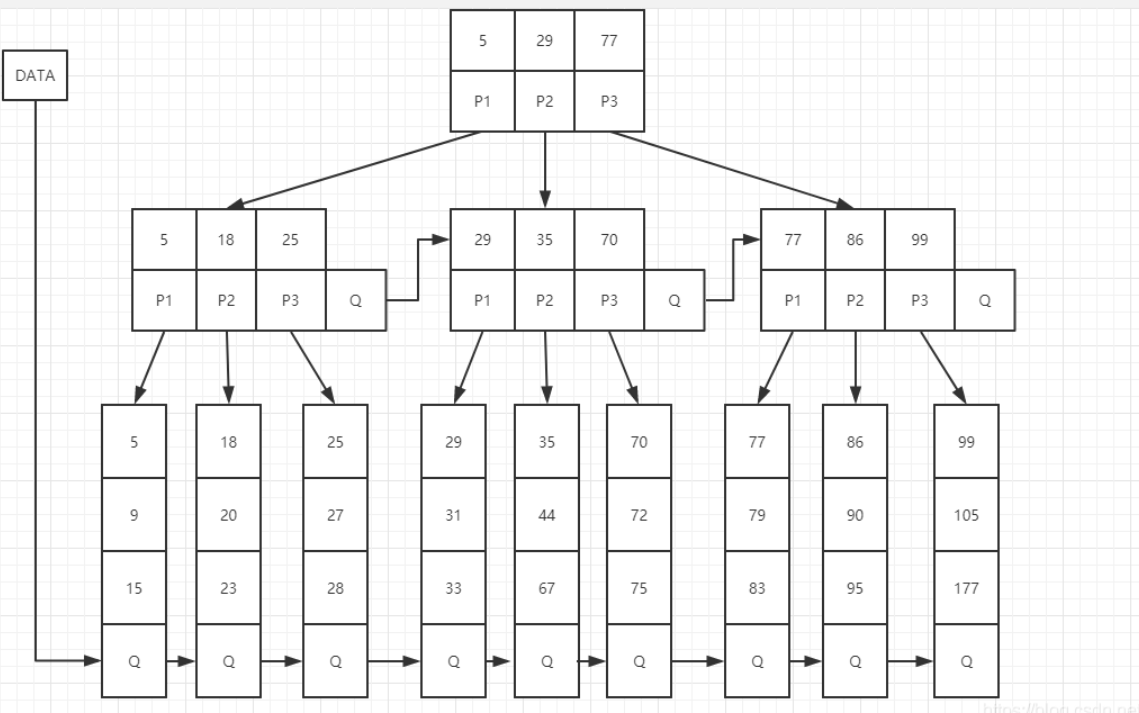
在B树基础上,为叶子结点增加链表指针(B树+叶子有序链表)
- 所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;
- B+树总是到叶子结点才命中。
B+树的非叶子节点不保存数据,只保存子树的临界值(最大或者最小),所以同样大小的节点,B+树相对于B树能够有更多的分支,使得这棵树更加矮胖,查询时做的IO操作次数也更少。
B*树
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针
在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3。
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
B*树分配新结点的概率比B+树要低,空间使用率更高;
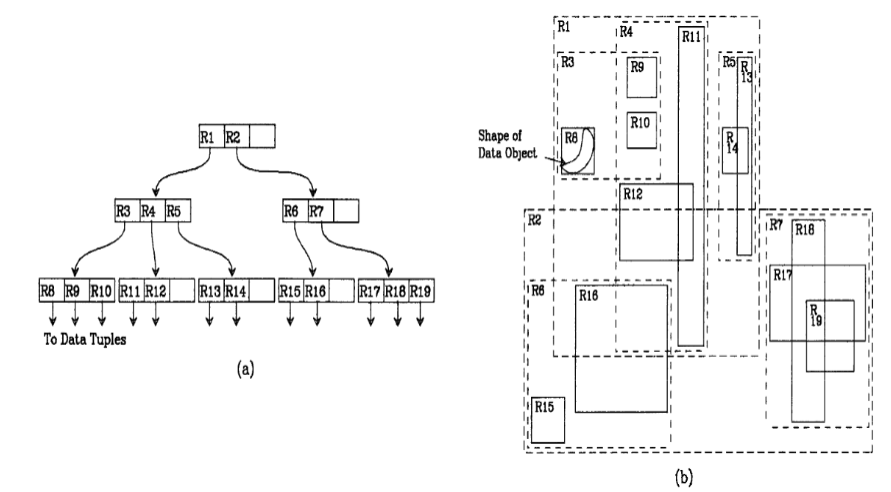
R树
R树是用来做空间数据存储的树状数据结构。例如给地理位置,矩形和多边形这类多维数据建立索引。
R树的核心思想是聚合距离相近的节点并在树结构的上一层将其表示为这些节点的最小外接矩形(MBR),这个最小外接矩形就成为上一层的一个节点。因为所有节点都在它们的最小外接矩形中,所以跟某个矩形不相交的查询就一定跟这个矩形中的所有节点都不相交。叶子节点上的每个矩形都代表一个对象,节点都是对象的聚合,并且越往上层聚合的对象就越多。也可以把每一层看做是对数据集的近似,叶子节点层是最细粒度的近似,与数据集相似度100%,越往上层越粗糙。