第6章 数据分区
概述
分区:每一条数据(或者每条记录,每行或每个文档)只属于某个特定分区。实际上,每个分区都可以视为一个完整的小型数据库,虽然数据库可能存在一些跨分区的操作。
采用数据分区的主要目的是提高可扩展性。不同的分区可以放在一个无共享集群的不同节点上。这样一个大数据集可以分散在更多的磁盘上,查询负载也随之分布到更多的处理器上。
对单个分区进行查询时,每个节点对自己所在分区可以独立执行查询操作,因此添加更多的节点可以提高查询吞吐量。超大而复杂的查询尽管比较困难,但也可能做到跨节点的并行处理。
数据分区与数据复制
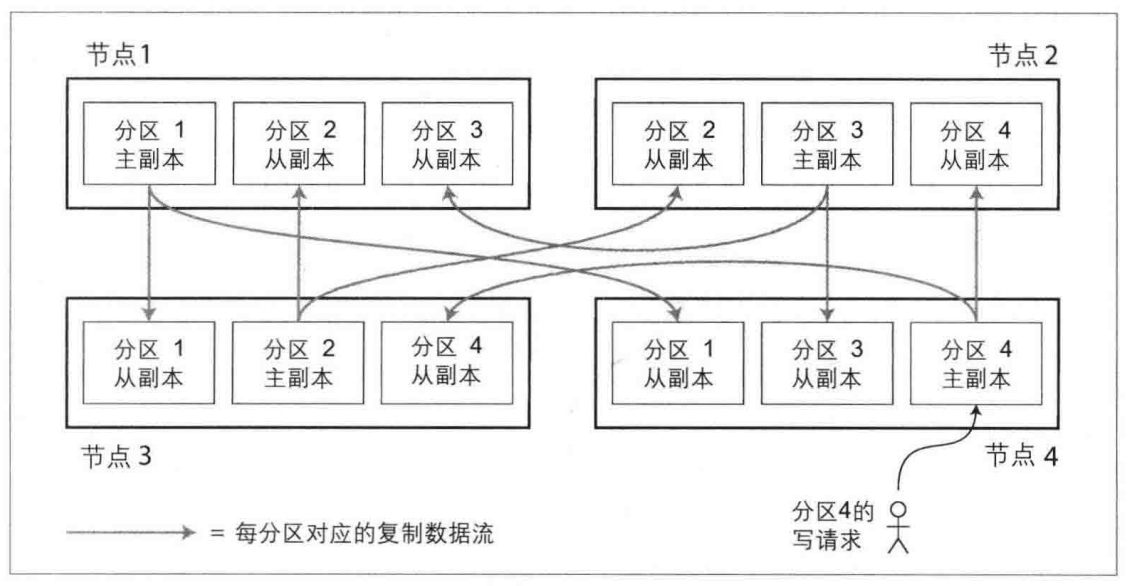
分区通常与复制结合使用,即每个分区在多个节点都存有副本。这意味着某条记录属于特定区,而同样的内容会保存在不同的节点上以提高系统的容错性。
键-值数据的分区
分区的目标时将数据和查询负载均衡分布在所有节点上。
如果分区不均匀,则会出现某些分区节点比其他分区承担更多的数据量或查询负载,称之为倾斜。倾斜会导致分区效率严重下降,在极端情况下,所有的负载可能会集中在一个分区节点上,这就意味着10个节点9个空闲,系统的瓶颈在最繁忙的那个 节点上。这种负载严重不成比例的分区即成为系统热点。
避免热点最简单的方法是将记录随机分配给所有节点上。这种方法可以比较均匀地分布数据,但是有一个很大的缺点:当试图读取特定的数据时,没有办法知道数据保存在哪个节点上,所以不得不并行查询所有节点。
可以改进上述方法。现在我们假设数据是简单的键-值数据模型,这意味着总是可以通过关键字来访问记录。
基于关键字区间分区
一种分区方式是为每个分区分配一段连续的关键字或者关键字区间范围(以最小值和最大值来指示),如图所示的纸质百科全书的卷目录。
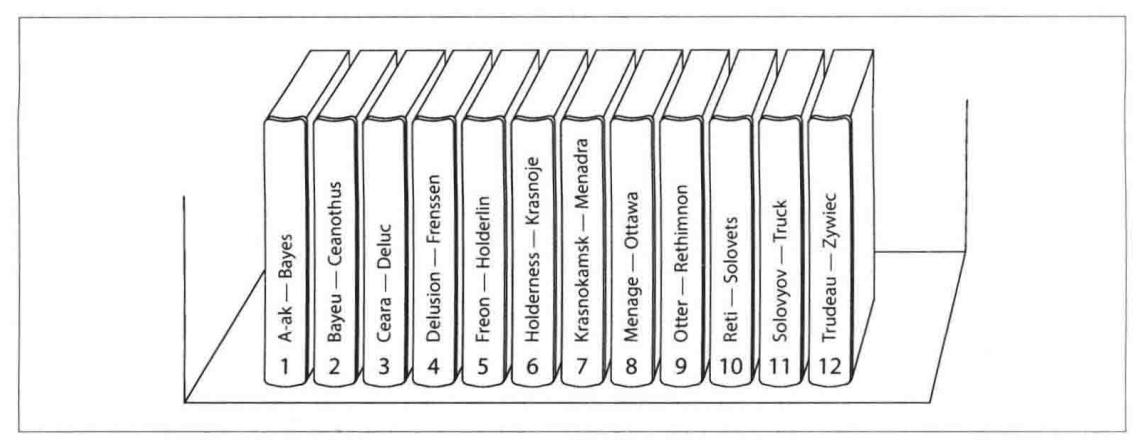
每个分区内可以按照关键字排序保存。但是,基于关键字的区间分区缺点是某些访问模式会导致热点。例如,关键字是时间戳则会击中同一个分区,导致该分区负载过高,而其他分区始终处于空闲状态。
为了避免上述问题,需要使用时间戳以外的其他内容作为关键字的第一项。
基于关键字哈希值分区
哈希函数可以处理数据倾斜并使其均匀分布。但是,通过关键字哈希进行分区,会丧失良好的区间查询特性。同时,出现大量对相同关键字的写操作(对热门人物的帖子评论),哈希也无法解决负载倾斜问题。

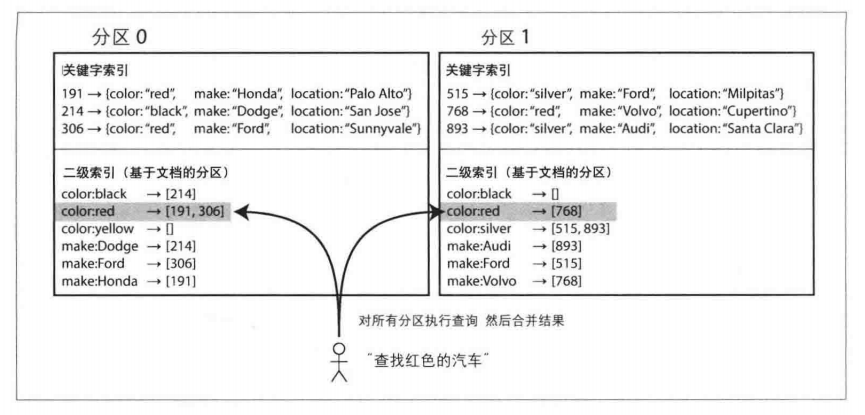
分区与二级索引
二级索引通常不能唯一标识一条记录,而是用来加速特定值的查询,例如查找用户123的所有操作,找到所有含有hogwash的文章,查找所有颜色为红色的汽车等。
二级索引的主要挑战是它们不能规整的地映射到分区中。有两种主要的方法来支持对二级索引进行分区:基于文档的分区和基于词条的分区。
基于文档分区的二级索引
例如,查询红色汽车,需要将查询发送到所有的分区,然后合并所有的返回结果。
基于词条的二级索引分区
所有数据分区中的颜色为红色的汽车被收录到在索引color:red中,而索引本身分区的,例如从a到r开始的颜色放在分区0中,从s到z的颜色放在分区1中。
分区再平衡
随着时间的推移,数据库可能总会出现某些变化:
- 查询压力增加,因此需要更多的CPU来处理负载。
- 数据规模增加,因此需要更多的磁盘和内存来存储数据。
- 节点可能出现故障,因此需要其他机器来接管失效的节点。
所有这些变化都要求数据和请求可以从一个节点转移到另一个节点。这样一个迁移负载的过程称为再平衡(或者动态平衡)。
无论对于哪种分区方案,分区再平衡通常至少要满足:
- 平衡之后,负载、数据存储、读写请求等应该在集群范围更均匀地分布。
- 再平衡执行过程中,数据库应该可以继续正常提供读写服务。
- 避免不必要的负载迁移,以加快动态再平衡,并尽量减少网络和磁盘I/O影响。
请求路由
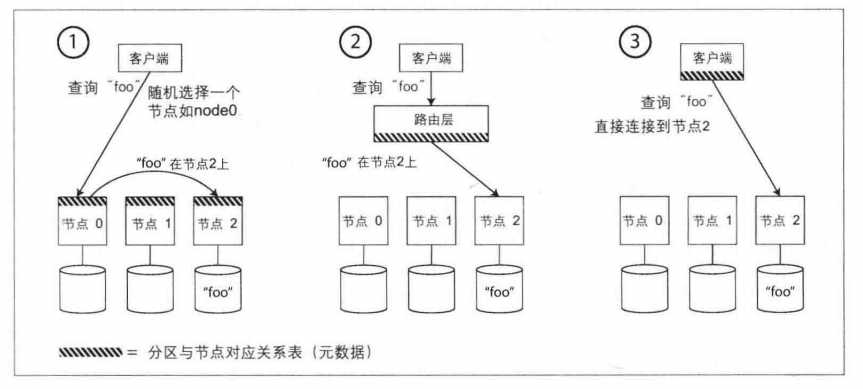
已经将数据集分布到多个节点上,但是仍然有一个悬而未决的问题:当客户端需要发送请求时,如何知道应该连接哪个节点?如果发生了分区再平衡,分区与节点的对应关系随之还会变化。
这其实属于一类典型的服务发现问题,服务发现并不限于数据库,任何通过网络访问的系统都有这样的需求,尤其是当服务目标支持高可用时(在多台机器上有冗余配置)。
概括来讲,这个问题有以下几种不同的处理策略:
- 允许客户端链接任意的节点。如果某节点恰好拥有所请求的分区,则直接处理该请求;否则,将请求转发到下一个合适的节 点,接收答复,并将答复返回给客户端。
- 将所有客户端的请求都发送到一个路由层,由后者负责将请求转发到对应的分区节点上。路由层本身不处理任何请求,它仅充一个分区感知的负载均衡器。
- 客户端感知分区和节点分配关系。此时,客户端可以直接连接到目标节点,而不需要任何中介。