
第3章 目标文件里有什么
文章总结
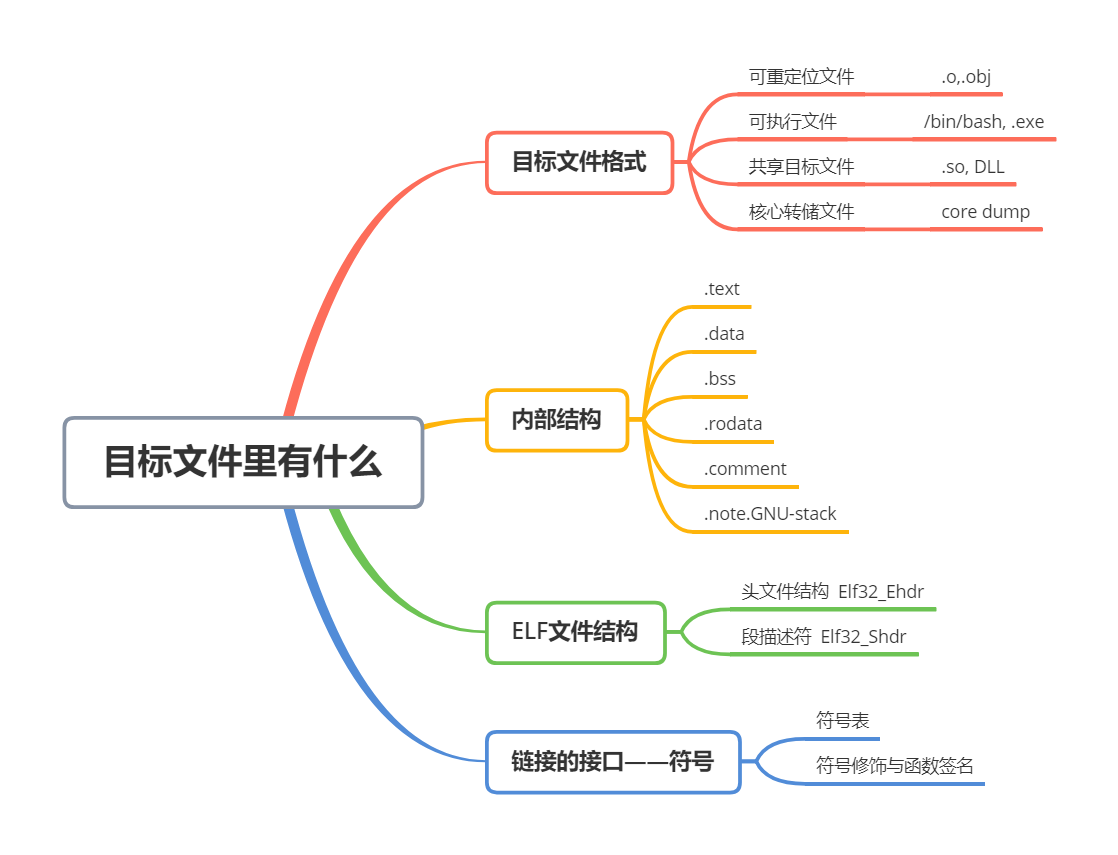
概述
编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。其实它本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同。
可执行文件格式涵盖了程序的编泽、链接、装载和执行的各个方面。了解它的结构并深入剖析它对于认识系统、了解背后的机理大有好处。
目标文件的格式
现在PC平台流行的可执行文件格式(Executable)主要是Windows下的PE(Portable Executable)和Linux的ELF(Executable Linkable Format),它们都是COFF(Common flle format)格式的变种。目标文件就是源代码编译后但未进行链接的那些中间文件(Windows的.obj和Linux下的.o),它跟可执行文件的内容与结构很相似,所以一般跟可执行文件格式一起采用一种格式存储。
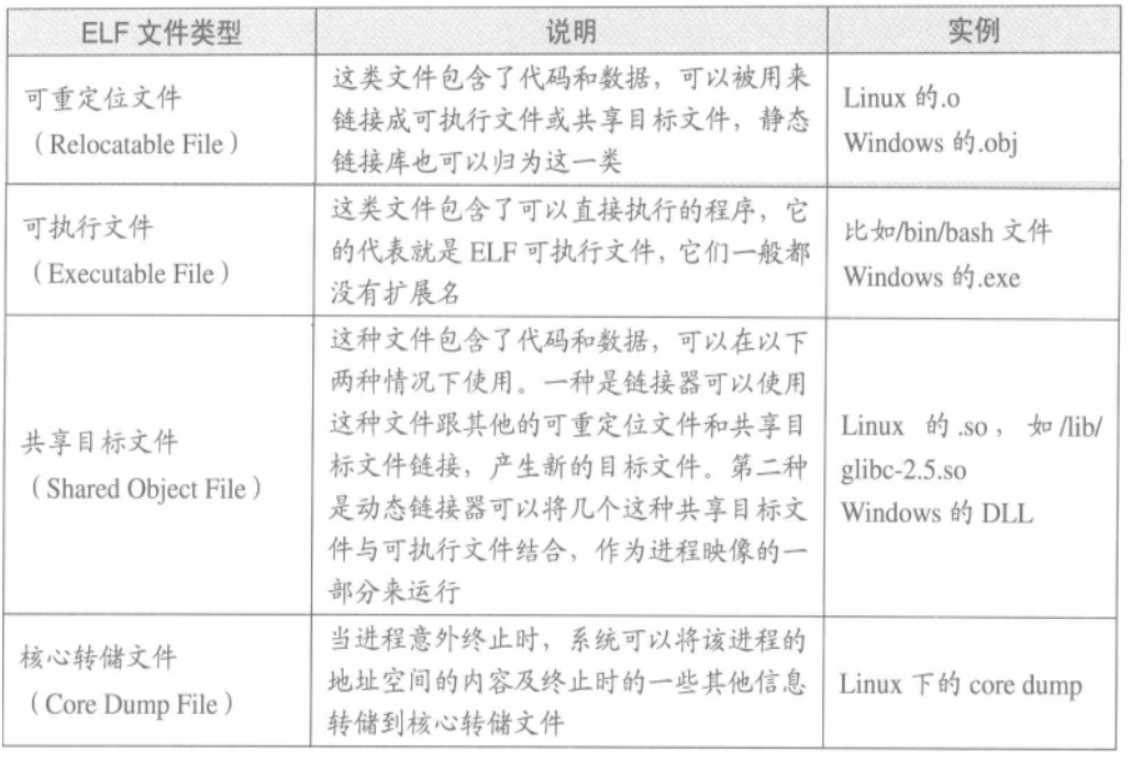
动态链接库(DLL,Dynamic Linking Library)(Windows的.dll和Linux的.so)及静态链接库(Static Linking Library)(Windows的.lib和Linux的.a)文件都按照可执行文件格式存储。ELF格式文件类型如下:
Linux下可以通过file命令查看相应的文件格式:

目标文件是什么样的
程序源代码编译后的机器指令经常被放在代码段(Code Section)里,代码段常见的名字有“.code”或“.text”:全局变量和局部静态变数据经常放在数据段(Data Section),数据段的一般名字都叫“.data”。看一个简单的程序被编译成目标文件后的结构:
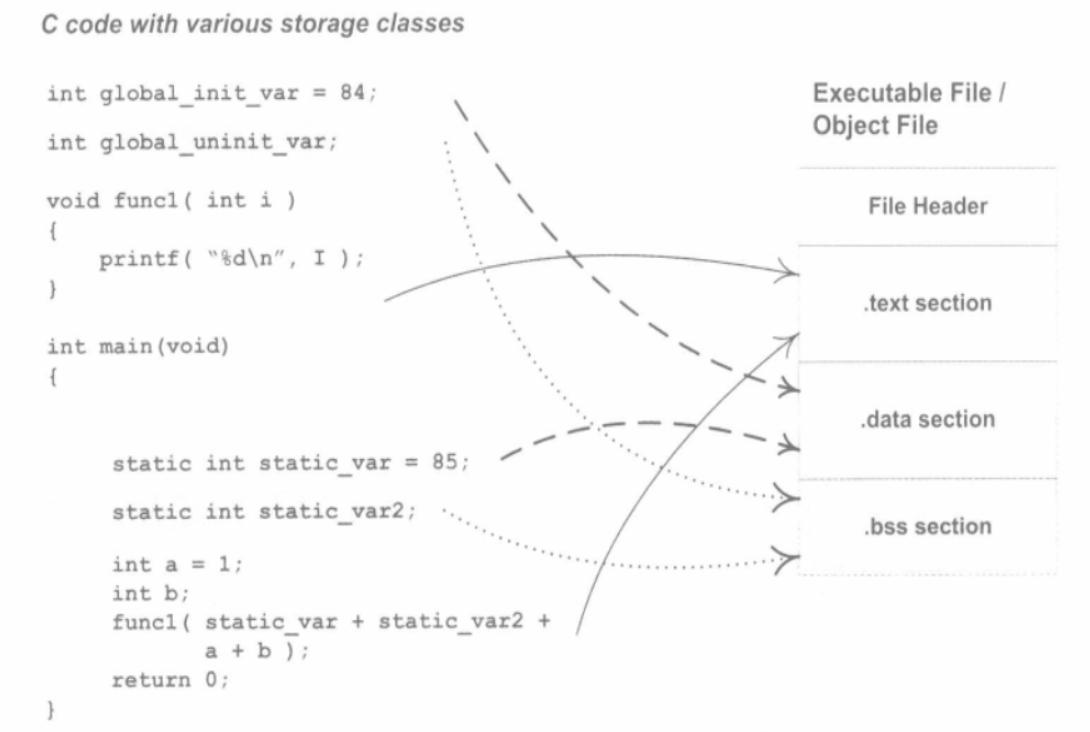
C语言的编译后执行语句都编译成机器代码,保存在.text段:已经初始化的全局变量和局部静态变量都保存在.data段:未初始化的全局变量和局部静态变量一般放在一个叫 .bss 的段里。
.bss段只是为未初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以它在文件中也不占据空间。
程序源代码被编译以后主要分成两种段:程序指令和程序数据。代码段属于程序指令,而数据段和,bss段属于程序数据。
数据和指令分段好处:
- 权限清晰:分别映射到不同的虚拟缓存中,程序指令为只读,程序数据为可读写。
- 指令和数据分离有利于提供程序的局部性。
详情
程序指令和数据分离可以提供程序的局部性,从而改善程序的性能和效率。这是因为程序的局部性原理认为,程序倾向于在较短的时间内访问相邻的指令和数据,而不是随机地访问整个内存空间。
当程序的指令和数据被分离存储时,可以利用不同的存储机制来优化对它们的访问。常见的做法是将指令存储在一种高速缓存(如指令缓存)中,以提高指令的访问速度;而将数据存储在另一种高速缓存(如数据缓存)中,以提高数据的访问速度。
这种分离存储的方式有以下几个好处:
缓存命中率提高:由于程序的指令和数据具有局部性,将它们分开存储可以提高缓存命中率。当程序频繁访问某个指令或数据时,它们很可能已经被加载到缓存中,从而加速了对它们的访问。
缓存策略优化:指令和数据分离存储可以针对它们的访问的特点分别采用不同的缓存策略。指令通常具有较好的空间局部性,即相邻的指令有较高的概率被访问,因此可以采用预取(prefetching)策略来提前将指令加载到缓存中,从而减少指令访问的等待时间。而数据通常具有较好的时间局部性,即最近访问过的数据很可能在短时间内再次被访问,因此可以采用缓存替换策略(如LRU)来保留最近访问的数据,提高缓存的命中率。
提高内存带宽利用率:将指令和数据分离存储可以通过并行处理来提高内存带宽的利用率。由于指令和数据可以同时从不同的存储单元(如指令高速缓存和数据高速缓存)中读取,可以在一次内存访问中同时获取指令和数据,从而减少了读取数据的等待时间,提高了内存带宽的利用效率。
总而言之,程序指令和数据分离存储可以通过优化缓存命中率、缓存策略和内存带宽利用率来提供程序的局部性。这能够改善程序的性能和效率,加快指令和数据的访问速度,提高系统的整体运行效率。
- 当系统中运行着多个该程序的副本时,仅需保存一份指令代码。
挖掘 SimpleSection.o
以 SimpleSection.c 为例,分析目标文件内容
详情
int printf(const char *format, ...);
int global_init_var = 84;
int global_uinit_var;
void func1(int i)
{
printf("%d\n", i);
}
int main()
{
static int static_var = 85;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
return a;
}
使用GCC来编译文件:
gcc -c SimpleSection.c
使用 objdump 来查看object内部的结构。
objdump -h SimpleSection.o 显示目标文件各个section的头部摘要信息。
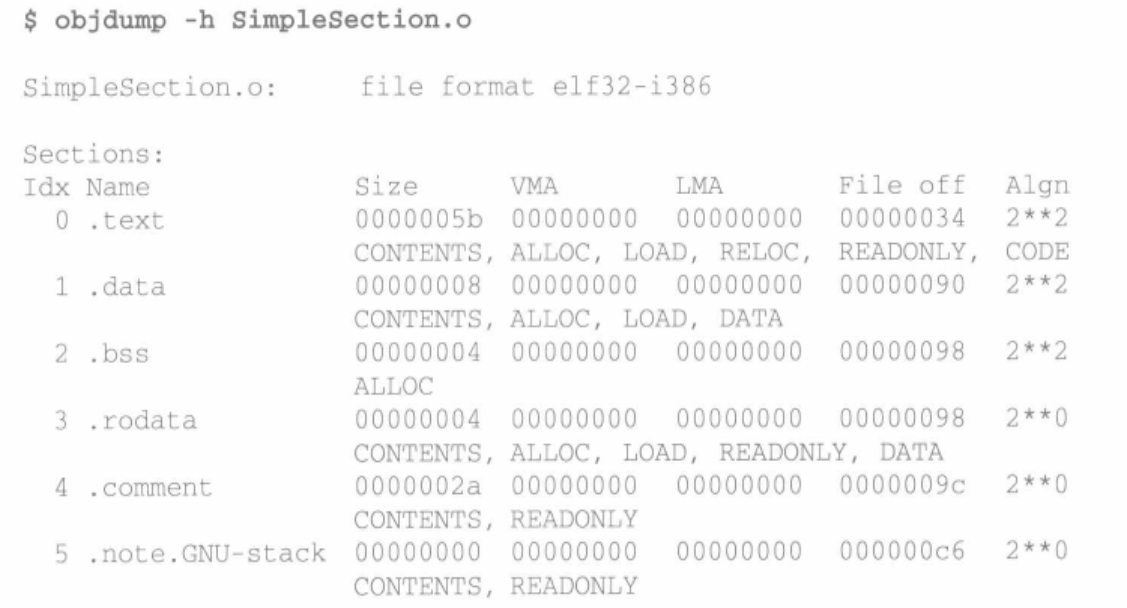
只读数据段(.rodata)、注释信息段(.comment)和堆栈提示段(.note.GNU-stack)。
段的长度(Size)和段所在的位置(File Offset),每个段的第2行中的“CONTENTS”、“ALLOC”等表示段的各种属性,“CONTENTS”表示该段在文件中存在。BSS段没有“CONTENTS”,表示它实际上在ELF文件中不存在内容。“.note.GNU-stack”段虽然有“CONTENTS”,但它的长度为0,我们暂且忽略它,认为它在ELF文件中也不存在。
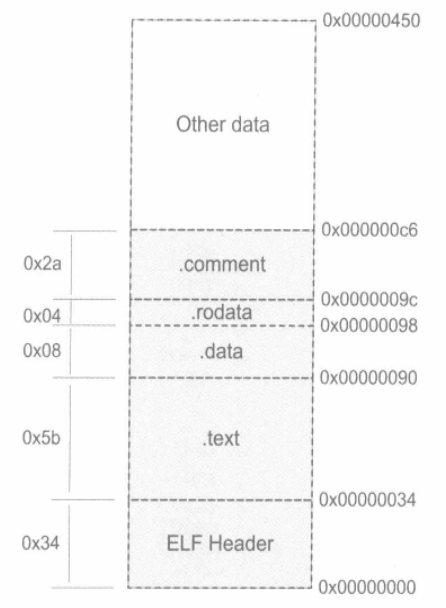
使用size命令,可以查看ELF文件的代码段、数据段和BSS段的长度。
[root@VM-16-6-centos test]# size SimpleSection.o
text data bss dec hex filename
95 8 4 107 6b SimpleSection.o
代码段
objdump -s -d SimpleSection.o
objdump的“-s”参数可以将所有段的内容以十六进制的方式打印出来,“-d”参数可以将所有包含指令的段反汇编。我
详情
<!-- @include: ./src/objdump_SimpleSection -->
数据段和只读数据段
.data段保存的是那些己经初始化了的全局静态变量和局部静态变量。
“.rodata”段存放的是只读数据,一般是程序里面的只读变量(如const修饰的变量)和字符串常量。单独设立“.rodata”段有很多好处,不光是在语义上支持了C++的const关键字,而且操作系统在加载的时候可以将“.rodata”段的属性映射成只读,这样对于这个段的任何修改操作都会作为非法操作处理,保证了程序的安全性。
BSS段
.bss段存放的是未初始化的全局变量和局部静态变量,其实更准确的说法是.bss段为它们预留了空间。但是可以看到该段的大小只有4个字节,这与global-uninit-var和static-var2的大小的8个字节不符。实际上编译单元内部可见的静态变量的确是存在在.bss段的。
objdump -x -s -d SimpleSection.o
Sections:
Idx Name Size VMA LMA File off Algn
2 .bss 00000004 0000000000000000 0000000000000000 0000009c 2**2
ALLOC
tips
static int x1 = 0;
static int x2 = 1;
x1会被存放在.bss中,x2会被放在.data中。因为x1为0,可以认为是未初始化的,被优化放在.bss段,可以节省空间。
其他段
自定义段
GCC提供了一个扩展机制,使得程序员可以指定变量所处的段:
__attribute__((section("FOO"))) int global = 42;
__attribute__((section("BAR"))) void foo()
{
}
我们在全局变量或函数之前加上“attribute((section("name")))”属性就可以把相应的变量或函数放到以“name”作为段名的段中。
ELF文件结构描述
ELF目标文件格式的最前部是ELF文件头(ELF Header),它包含了描述整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。紧接着是ELF文件各个段。其中ELF文件中与段有关的重要结构就是段表(Section Header Table),该表描述了ELF文件包含的所有段的信息,比如每个段的段名、段的长度、在文件中的移、读写权限及段的其他属性。
readelf -h SimpleSection.o -h,--file-header:显示文件头信息
[root@VM-16-6-centos test]# readelf -h SimpleSection.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 1056 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 13
Section header string table index: 12
从上面输出的结果可以看到,ELF的文件头中定义了ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度及段的数量等。
ELF文件头结构及相关常数被定义在“/usr/include/elf.h”里,因为ELF文件在各种平台下都通用,ELF文件有32位版本和64位版本。它的文件头结构也有这两种版本,分别叫做“Elf32_Ehdr”和“Elf、64_Ehdr。32位版本与64位版本的ELF文件的文件头内容是一样的,只不过有些成员的大小不一样。
以32版本的头文件结构“Elf32_Ehdr”为例
typedef struct{
unsigned char e_ident[16];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;//Start of program headers
Elf32_Off e_shoff;//Start of section headers
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
}Elf32_Ehdr;
ELF魔数

最开始的4个字节是所有ELF文件都必须相同的标识码,分别为0x7F、0x45、0x4c、0x46,第一个字节对应ASCII字符里面的DEL控制符,后面3个字节刚好是ELF这3个字母的ASCII码。这4个字节又被称为ELF文件的魔数,几乎所有的可执行文件格式的最开始的几个字节都是魔数。接下来的一个字节是用来标识ELF的文件类的,0x01表示是32位的,0x02表示是64位的:第6个字是字节序,规定该ELF文件是人端的还是小端的(见附录:字节序)。第7个字节规定ELF文件的主版本号,一般是1,因为ELF标准自1.2版以后就再也没有更新了。后面的9个字节ELF标准没有定义,一般填0,有些平台会使用这9个字节作为扩展标志。
文件类型

机器类型
段表
前面使用了“objdump -h”来查看ELF文件中包含的段。可以使用read工具来查看ELF文件的段,它显示出来的结果才是真正的段表结构:
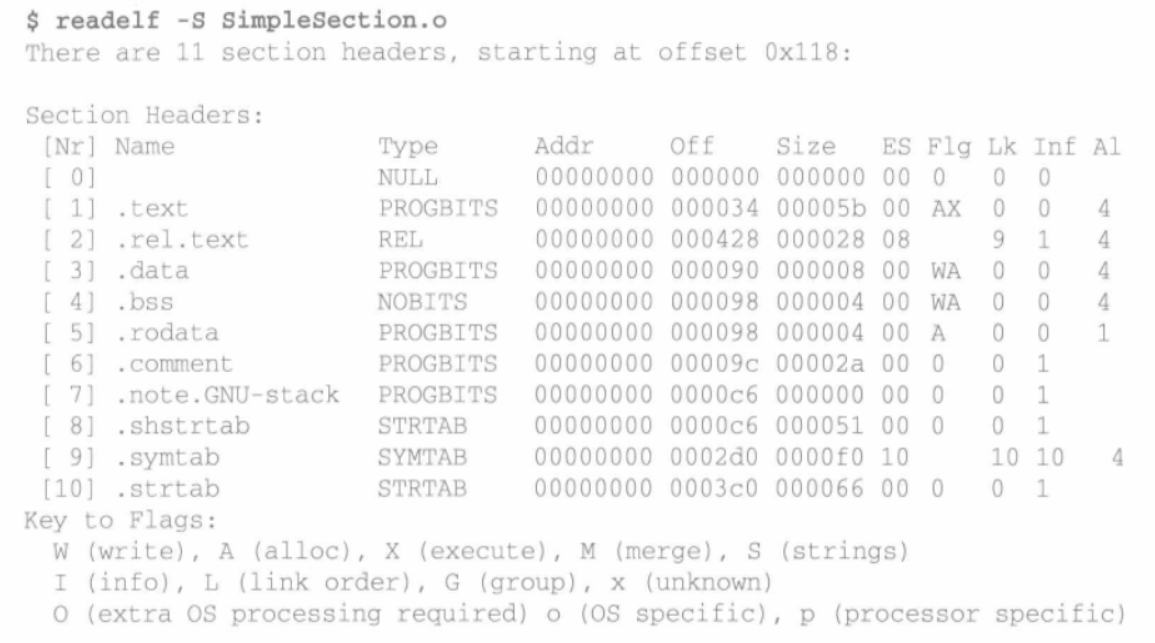
如图所示,段表就是有11个元素的数组。第一个元素时无效段,即共有10个有效段。
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags;/* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign;/* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
SimpleSection的所有段的位置和长度给分析清楚了。如图所示:
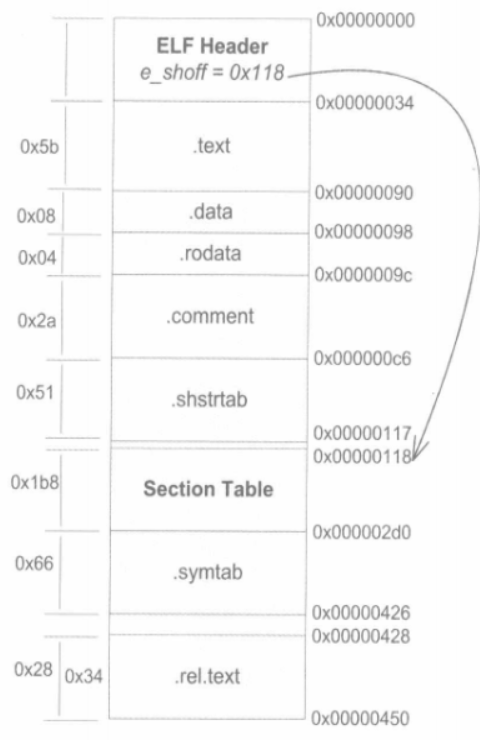
重定位表
SimpleSection.o中有一个叫做“.rel.text”的段,它的类型(sh-type)“SHTREL”,即是一个重定位表(Relocation Table)。**链接器在处理目标文件时,须要对目标文件中某些部位进行重定位,即代码段和数据段中那些对绝对地址的引用的位置。**这些重定位的信息都记录在ELF文件的重定位表里面,对于每个须要重定位的代码段或数据段,都会有一个相应的重定位表。
字符串表
常见的段名为“.strtab”或“.shstrtab”。这两个字符串表分别为字符串表(String Table)和段表字符串表(Section Header String Table)。字符串表用来保存普通的字符串,比如符号的名字:段表字符串表用来保存段表中用到的字符串,最常见的就是段名(sh-name)。
链接的接口 ———— 符号
链接过程的本质就是要把多个不同的目标文件之间相互“粘”到一起。在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。在链接中,我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名(Symbol Name)。
可以将符号看作是链接中的粘合剂,整个链接过程正是基于符号才能够正确完成。链接过程中很关键的一部分就是符号的管理,**每一个目标文件都会有一个相应的符号表(Symbol Table),这个表里面记录了目标文件中所用到的所有符号。**每个定义的符号有一个对应的值,叫做符号值(Symbol Value),对于变量和函数来说,符号值就是它们的地址。除了函数和变鼠之外,还存在其他几种不常用到的符号。
可以使用 nm 命令查询 “SimpleSection.o” 的符号结果:

符号修饰与函数签名
为了防止类似的符号名冲突,UNIX下的c语言就规定,c语言源代码文件中的所有全局的变量和函数经过编译以后,相对应的符号名前加上下划线“_”。C++增加了命名空间的方法来解决多模块的符号冲突问题。
C语言符号修饰
详情
int func(int x)
{
return 0;
}
int main(int argc, char *argv[])
{
int j = func(1);
return 0;
}
gcc test.c -o testc
nm testc
00000000004004ed T func
00000000004004fb T main
g++ test.c -o testcpp
nm testcpp
000000000040051b T main
000000000040050d T _Z4funci
通过nm区分到底是C还是C++的编译结果
C++符号修饰
众所周知,强大而又复杂的C++拥有类、继承、虚机制、重载、名称空间等这些特性,它们使得符号管理更为复杂。最简单的例子,两个相同名字的函数func(int)和func(double),尽管函数名相同,但是参数列表不同,这是c++里面函数重载的最简单的一种情况。为了支持c++这些复杂的特性,人们发明了符号修饰(Name Decoration)或符号改编(Name Mangling)的机制。
int func(int);
float func(float);
class C {
int func(int);
class C2{
int func(int);
};
};
namespace N{
int func(int);
class C {
int func(int);
};
};
引入一个术语叫做函数签名(Function Signature), 函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息。函数签名用于识别不同的函数。
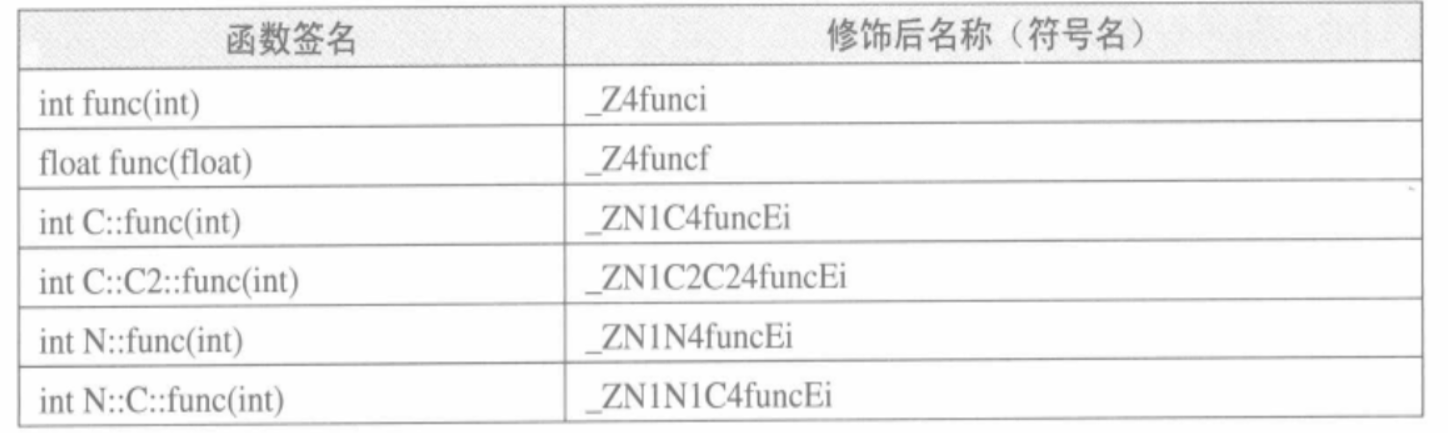
GCC的基本c++名称修饰方法如下:所有的符号都以 “_Z” 开头,对于嵌套的名字(在名称空间或在类里面的),后面紧跟“N”,然后是各个名称空间和类的名字,每个名字前是名字字符串长度,再以 “E” 结尾。比如N::C::func经过名称修饰以后就是 _ZN1N1C4funcE。对于一个函数来说,它的参数列表紧跟在"E”后面,对于int类型来说,就是字母“i”。所以整个N::C::func(int)函数签名经过修饰为 _ZN1N1C4funcEi。
Visual C++ 编译器下,修饰后名称如图:
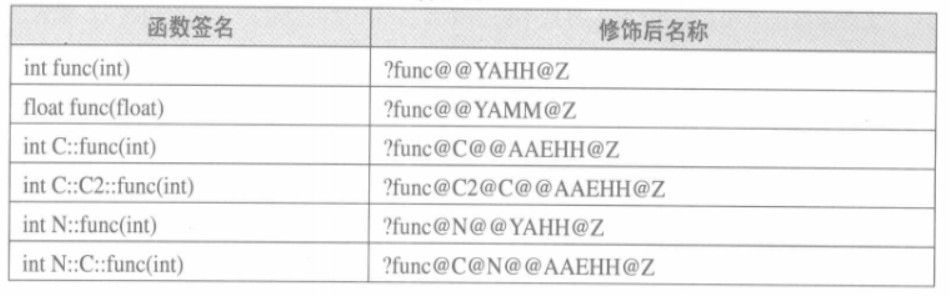
由于不同的编译器采用不同的名字修饰方法,必然会导致由不同编译器编译产生的目标文件无法正常相互链接,这是导致不同编译器之间不能互操作的主要原因之一。
extern "C"
c++为了与c兼容,在符号的管理上,c++有一个用来声明或定义一个C符号的 extern "C" 关键字用法:
extern "C"
int func(int);
int var;
}
c++编译器会将在extern "C"的大括号内部的代码当作C语言代码处理。所以很明显,上面的代码中,c++的名称修饰机制将不会起作用。
使用C++的宏“__cplusplus”判断当前编译单元是不是C++代码,实现平滑过渡
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endif
如果当前编译单元是C++代码,那么memset会在extern "C"里面被声明:如果是C代码,就直接声明。