
第10章 内存
文章总结
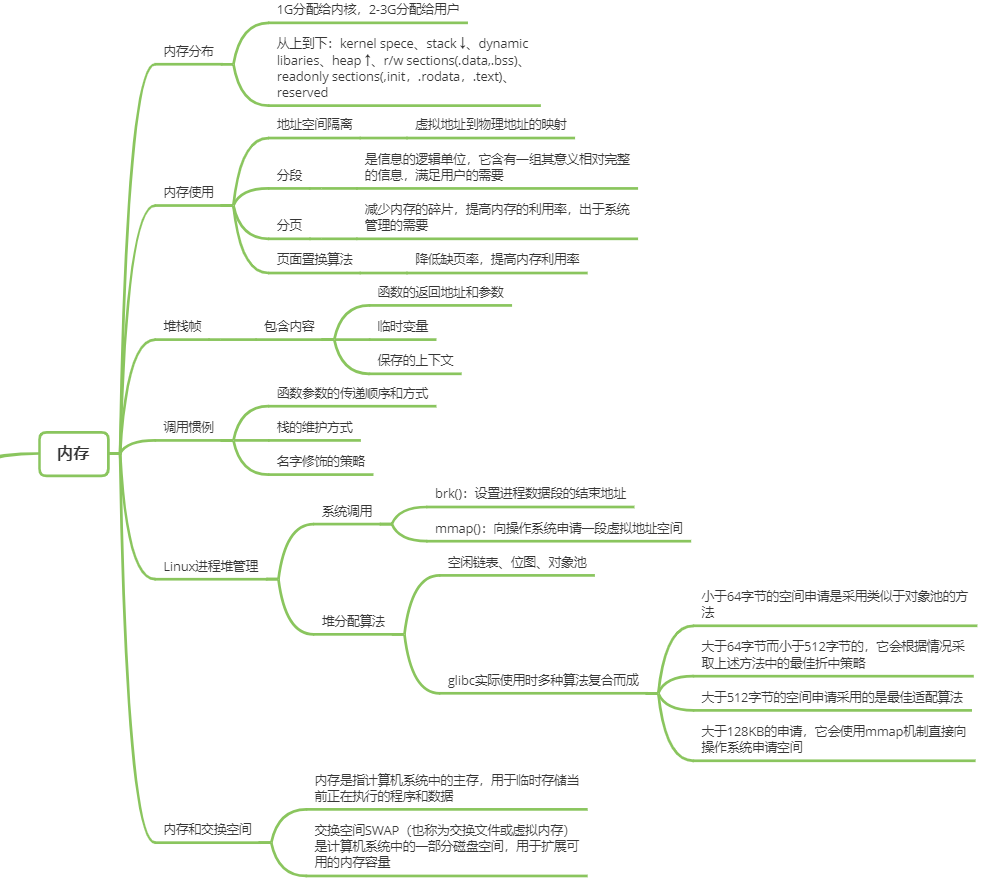
程序环境
程序的内存布局
Linux默认将高地址的1GB空间分配给内核,用户使用剩下2GB或3GB的内存空间,也称用户空间。
一个典型的Linux进程地址空间分布如下:

段错误(segment fault)或 非法操作,该内存地址不能 read/write 的错误信息。
栈和调用惯例
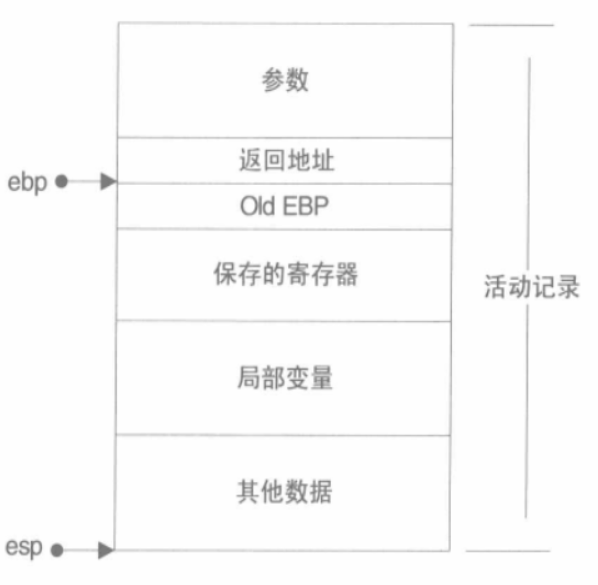
栈保存了一个函数调用所需要的维护信息,常被称为堆栈帧(Stack Frame)或活动记录(Activate Record)。
堆栈帧一般包括如下几方面内容:
- 函数的返回地址和参数。
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。
一个函数的活动记录用ebp和esp这两个寄存器划定范围。esp指向栈的顶部,ebp指向函数活动记录的一个固定位置,又称帧指针(Frame Pointer)
int foo()
{
return 123;
}
foo函数汇编代码分析:

连续的0xCCCC,汉字编码就是“烫”;0xCDCD,汉字编码就是“屯”。
调用惯例
调用惯例:函数的调用方和被调用方对函数如何调用有着统一的理解。
调用惯例规定内容:
- 函数参数的传递顺序和方式
- 栈的维护方式
- 名字修饰的策略
foo函数
int foo(int n, float m)
{
int a=0, b=0;
...
}
foo函数栈布局:

函数返回值传递
eax是传递返回值的通道,8字节对象用eax和edx联合返回方式进行。大于8字节的返回类型,有以下处理:

- 首先main函数在栈上额外开辟了一片空间,并将这块空间的一部分作为传递返回值的临时对象,这里称为temp。
- 将temp对象的地址作为隐藏参数传递给return_test函数。
- return_test函数将数据拷贝给temp对象,并将temp对象的地址用eax传出。
- return_test返回之后,main函数将eax指向的temp对象的内容拷贝给n。
堆与内存管理
因为每次程序申请或者释放堆空间都需要进行系统调用,性能开销是很大的。比较好的做法就是程序向操作系统申清一块适当大小的堆空间,然后由程序自己管理这块空间,而具体来讲,管理着堆空间分配的往往是程序的运行库。 ———— tcmalloc
**运行库相当于是向操作系统“批发”了一块较大的堆空间,然后“零售”给程序用。**当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。当然运行 库在向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。于是运行库需要一个算法来管理堆空间,这个算法就是堆的分配算法。
Linux进程堆管理
Linux下的进程堆管理稍微有些复杂,因为它提供了两种堆空间分配的方式,即两个系统调用:一个是brk()系统调用,另外一个是mmap()。
int brk(void* end_data_segment)
brk()的作用就是设置进程数据段的结束地址,即它可以扩大或者缩小数据段(Linux下数据段和BSS合并在一起统称数据段)。如果我们将数据段的结束地址向高地址 移动,那么扩大的那部分空间就可以被我们使用,把这块空间拿来作为堆空间是最常见的做法。
mmap()的作用就是向操作系统申请一段虚拟地址空间,当然这块虚拟地址空间可以映射到某个文件(这也是这个系统调用的最初的作用),当它不将地址空间映射到某个文件时,我们又称这块空间为匿名(Anonymous)空间,匿名空间就可以拿来作为堆空间。它的声明如下:
man 2 mmap
#include<sys/mman.h>
/* 创建映射区 */
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
/* 释放映射区 */
int munmap(void *addr, size_t length);
mmap参数:
addr:指定映射区的首地址。通常传NULL,表示让系统自动分配
length:共享映射区的大小(<= 文件实际大小)
prot:共享内存区的读写属性
PROT_READ
PROT_WRITE
PROT_READ | PROT_WRITE
flag:标注共享内存的共享属性
MAP_SHARED(对内存的修改会反映到磁盘上)
MAP_PRIVATE(对内存的修改不会反映到磁盘上)
fd:用于创建共享内存映射区的那个文件的 文件描述符
offset:从文件偏移位置开始建立映射区 (必须是4k的整数倍4096)默认0,表示映射文件全部
参考:https://blog.csdn.net/m0_73604721/article/details/127928389
glibc的malloc函数处理机制:
- 当开辟的空间小于 128K 时,调用brk()函数,malloc 的底层实现是系统调用函数 brk(),其主要移动指针 _enddata。
- 当开辟的空间大于 128K 时,调用mmap()函数来分配一块匿名空间,然后在这个匿名空间中为用户分配空间。(mmap申请的空间的起始地址和大小都是必须是系统页大小的整数倍)
知识点:
内存和交换空间是计算机系统中用于存储数据和程序的两种重要资源。
内存是指计算机系统中的主存,用于临时存储当前正在执行的程序和数据。它是由物理内存芯片组成的,通过内存地址可以进行读取和写入操作。内存速度快,可以快速访问数据,但容量较有限。一般来说,内存中存放的是当前活跃的程序和数据,当程序执行完成或者不再活跃时,内存中的数据会被释放。
交换空间(也称为交换文件或虚拟内存)是计算机系统中的一部分磁盘空间,用于扩展可用的内存容量。当内存不足时,操作系统会将暂时不活跃或不常用的数据和程序从内存中移出,存储到交换空间中。这样可以释放内存空间,以便给活跃的程序和数据提供更多的空间。当需要访问被交换出去的数据时,操作系统会将其重新载入到内存中。然而,与内存相比,从交换空间中加载数据需要较长的时间,因为磁盘访问速度相对较慢。
内存和交换空间的组合可以帮助操作系统更有效地管理系统资源。内存用于存储活跃的程序和数据,而交换空间用于存储不活跃或不常用的数据。当需要更多内存时,可以将一部分内存中的数据移到交换空间,从而为活跃的程序和数据提供更多可用空间。
堆分配算法
堆分配算法:如何管理一大块连续的内存空间,能够按照需求分配、释放其中的空间。
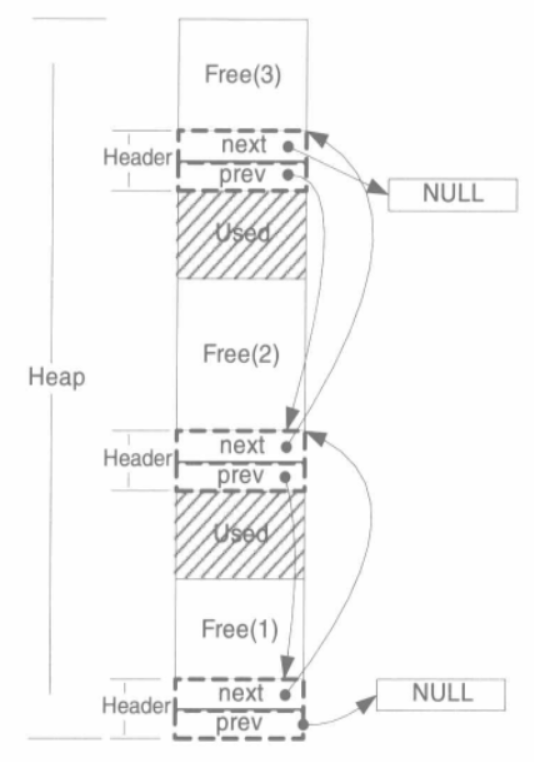
- 空闲链表:把堆中各个空闲的块按照链表的方式连接起来,当用户请求一块空间时,可以遍历整个列表,直到找到合适大小的块并且将它拆分:当用户释放空间时将它合并到空闲链表中。
- 位图:将整个堆划分为大量的块(block),每个块的大小相同。当用户请求内存的时候,总是分配整数个块的空间给用户,第一个块我们称为已分配区域的头(Head),其余的称为已分配区域的主体(Body)。而我们可以使用一个整数数组来记录块的使用情况,由于每个块只有头/主体/空闲三种状态,因此仅仅需要两位即可表示一个块,因此称为位图。
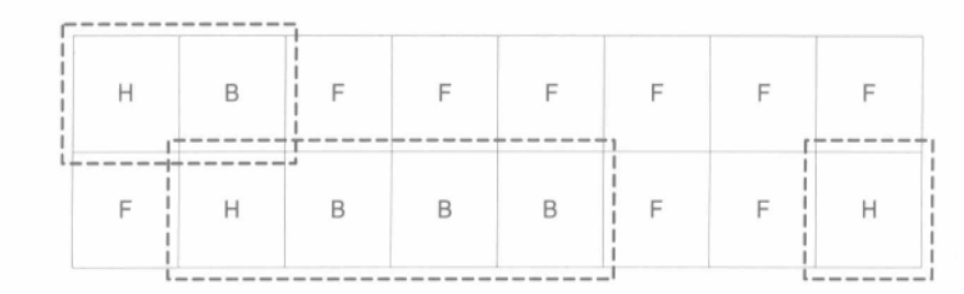
这个堆分配了3片内存,分别有2/4/1个块,用虚线框标出。其对应的位图将是: (HIGE) 11 00 00 10 10 10 11 00 00 00 00 00 00 00 10 11 (LOW)
其中11表示(Head),10表示主体(Body),00表示空闲(Free)。
- 对象池:如果每一次分配的空间大小都一样,那么就可以按照这个每次请求分配的大小作为一个单位,把整个堆空间划分为大量的小块,每次请求的时候只需要找到一个小块就可以了。对象池的管理方法可以采用空闲链表,也可以采用位图,与它们的区别仅仅在于它假定了每次请求的都是一个固定的大小,因此实现起来很容易。
实际上很多现实应用中,堆的分配算法往往是采取多种算法复合而成的。比如对于glibc来说,它对于小于64字节的空间申请是采用类似于对象池的方法:而对于大于512字节的空间申请采用的是最佳适配算法:对于大于64字节而小于512字节的,它会根据情况采取上述方法中的最佳折中策略;对于大于128KB的申请,它会使用mmap机制直接向操作系统申请空间。