
muduo - timing wheel
概述
本文介绍如何使用 timing wheel 来踢掉空闲的连接,一个连接如果若干秒没有收到数据,就认为是空闲连接。代码见examples/idleconnection。
在严肃的网络程序中,应用层的心跳协议是必不可少的。应该用心跳消息来判断对方进程是否能正常工作,“踢掉空闲连接”只是权宜之计。如果一个连接在连续几秒时间内没有收到数据,就默认连接已经中断,将其断开,为此有两种简单粗暴的做法(以8s为例):
每个连接保存“最后收到数据的时间 lastReceiveTime”,然后用一个定时器,每秒钟遍历一遍所有连接,断开那些 (now - connection.lastReceiveTime) > 8s 的 connection。这种做法全局只有一个 repeated timer,不过每次 timeout 都要检查全部连接,如果连接数目比较大(几千上万),这一步可能会比较费时。
每个连接设置一个 one-shot timer,超时定为 8s,在超时的时候就断开本连接。当然,每次收到数据要去更新 timer。这种做法需要很多个 one-shot timer,会频繁地更新 timers。如果连接数目比较大,可能对 reactor 的 timer queue 造成压力。
使用 timing wheel 能够有效避免上述两种做法的缺点。其核心思想为:处理连接超时可以用一个简单的数据结构:8 个桶组成的循环队列。第一个桶放下一秒将要超时的连接,第二个放下 2 秒将要超时的连接。每个连接一收到数据就把自己放到第 8 个桶,然后在每秒钟的 callback 里把第一个桶里的连接断开,把这个空桶挪到队尾。这样大致可以做到 8 秒钟没有数据就超时断开连接。更重要的是,每次不用检查全部的 connection,只要检查第一个桶里的 connections,相当于把任务分散了。
Timing wheel 原理
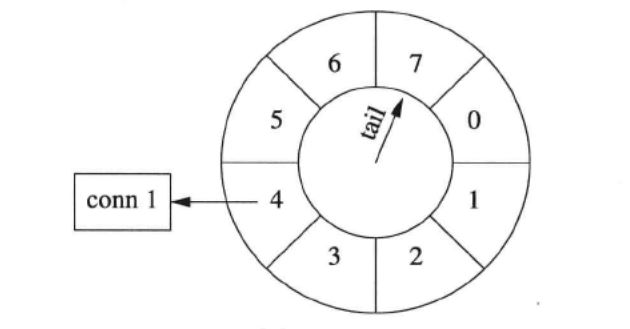
Simple timing wheel 的基本结构是 一个循环队列 + 一个指向队尾的指针 (tail),这个指针每秒钟移动一格,就像钟表上的时针,timing wheel 由此得名。以下是某一时刻 timing wheel 的状态,格子里的数字是倒计时(与通常的 timing wheel 相反),表示这个格子(桶子)中的连接的剩余寿命。一秒钟以后,tail 指针移动一格,原来四点钟方向的格子被清空,其中的连接已被断开。
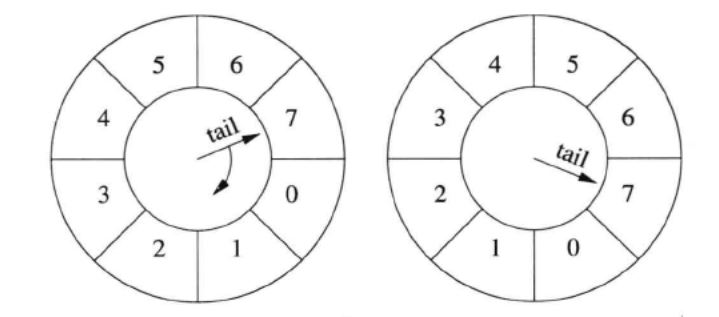
连接超时被踢掉的过程
假设在某个时刻,conn 1 到达,把它放到当前格子中,它的剩余寿命是 7 秒。此后 conn 1 上没有收到数据。1 秒钟之后,tail 指向下一个格子,conn 1 的剩余寿命是 6 秒。又过了几秒钟,tail 指向 conn 1 之前的那个格子,conn 1 即将被断开。下一秒,tail 重新指向 conn 1 原来所在的格子,清空其中的数据,断开 conn 1 连接。
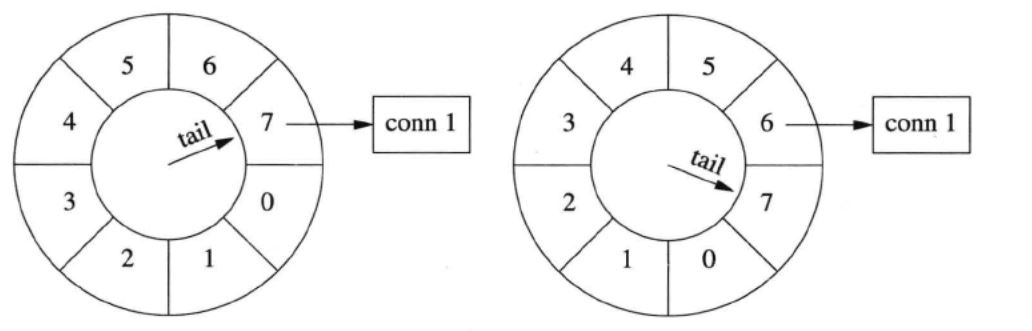
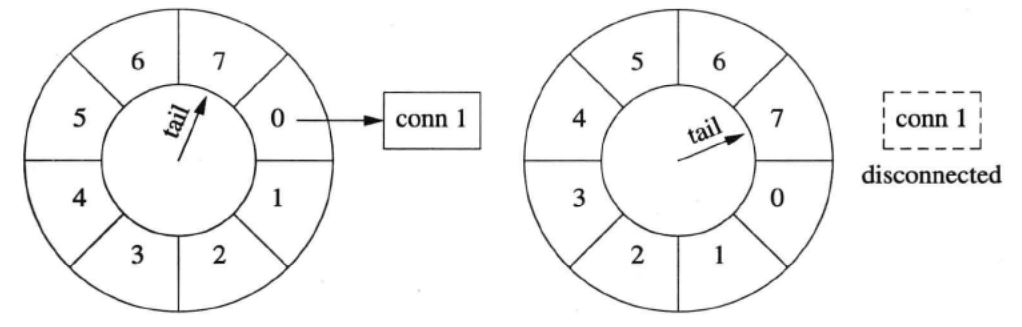
连接刷新
如果在断开 conn 1 之前收到数据,就把它移到当前的格子里。conn1的剩余寿命是3秒,此时conn1收到数据,conn 1 的寿命延长为 7 秒。时间继续前进,conn 1 寿命递减,不过它已经比第一种情况长寿了。
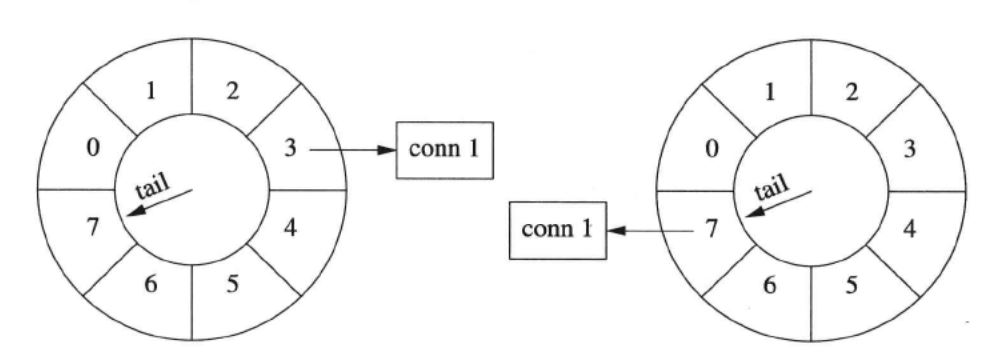
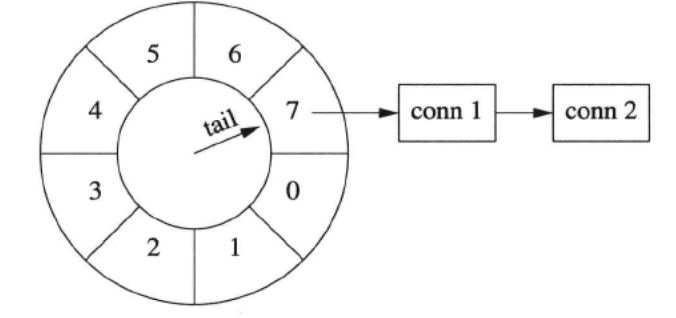
多个连接
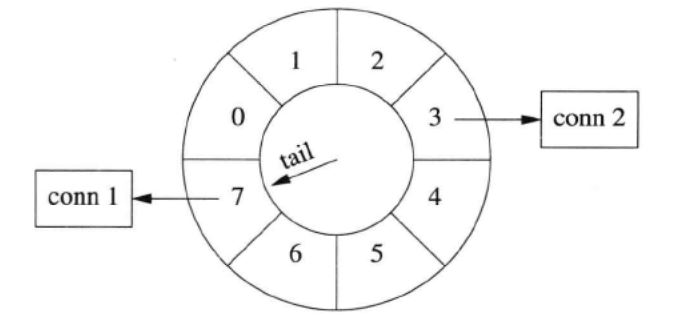
timing wheel 中的每个格子是个 hash set,可以容纳不止一个连接。比如一开始,conn 1 到达。随后,conn 2 到达,这时候 tail 还没有移动,两个连接位于同一个格子中,具有相同的剩余寿命。(下图中画成链表,代码中是哈希表。)几秒钟之后,conn 1 收到数据,而 conn 2 一直没有收到数据,那么 conn 1 被移到当前的格子中。这时 conn 1 的寿命比 conn 2 长。
代码实现与分析
在具体实现中,格子里放的不是连接,而是一个特制的 Entry struct,每个 Entry 包含 TcpConnection 的 weak_ptr。Entry 的析构函数会判断连接是否还存在(用 weak_ptr),如果还存在则断开连接。为了简单起见,我们不会真的把一个连接从一个格子移到另一个格子,而是采用引用计数的办法,用 shared_ptr 来管理 Entry。如果从连接收到数据,就把对应的 EntryPtr 放到这个格子里,这样它的引用计数就递增了。当 Entry 的引用计数递减到零,说明它没有在任何一个格子里出现,那么连接超时,Entry 的析构函数会断开连接。
Time wheel 通过 boost::circular_buffer + boost::unordered_set 实现:
typedef boost::unordered_set<EntryPtr> Bucket;
typedef boost::circular_buffer<Bucket> WeakConnectionList;
WeakConnectionList connectionBuckets_;
特性:
- 支持随机访问
- 固定容量
- 插入元素超过容量时会对头部或者尾部元素弹出
circular_buffer会自动弹出元素的特性:
- buffer的元素保存Bucket,这个Bucket是一个集合,保存在1秒内所有连接的shared_ptr
- 对buffer进行特定大小的初始化,并用空填满
- 当有一个连接的时候,将会把这个连接插入到Bucket里面
- 每一秒都会往buffer里面插入空的Bucket
- 这样基于circular_buffer的特性,现有的连接就会自动往前滚动
这里作者封装了一层结构Entry来管理TcpConnection,当circular_buffer将尾部 popback的时候,会依次调用其析构函数,并在析构函数主动断开连接。
成员函数分析
在构造函数中,注册每秒钟的回调(EventLoop::runEvery() 注册 EchoServer::onTimer() ),然后把 timing wheel 设为适当的大小。
EchoServer::EchoServer(EventLoop* loop,
const InetAddress& listenAddr,
int idleSeconds)
: server_(loop, listenAddr, "EchoServer"),
connectionBuckets_(idleSeconds)
{
server_.setConnectionCallback(
std::bind(&EchoServer::onConnection, this, _1));
server_.setMessageCallback(
std::bind(&EchoServer::onMessage, this, _1, _2, _3));
loop->runEvery(1.0, std::bind(&EchoServer::onTimer, this));
connectionBuckets_.resize(idleSeconds);//根据超时秒数设置Bucket大小
dumpConnectionBuckets();
}
其中 EchoServer::onTimer() 的实现只有一行(除了打印消息):往队尾添加一个空的 Bucket,这样 circular_buffer 会自动弹出队首的 Bucket,并析构之。在析构 Bucket 的时候,会依次析构其中的 EntryPtr 对象,这样 Entry 的引用计数就不用我们去操心,C++ 的值语意会帮我们搞定一切。
void EchoServer::onTimer()
{
connectionBuckets_.push_back(Bucket());
dumpConnectionBuckets();//打印消息
}
Entry封装:
struct Entry : public muduo::copyable
{
explicit Entry(const WeakTcpConnectionPtr& weakConn)
: weakConn_(weakConn)
{
}
~Entry()
{
muduo::net::TcpConnectionPtr conn = weakConn_.lock();
if (conn)
{
conn->shutdown();
}
}
WeakTcpConnectionPtr weakConn_;
};
在连接建立时,以对应的TcpConnection对象conn来创建一个 Entry 对象entry,把它放到 timing wheel 的队尾。另外,我们还需要把 entry的弱引用保存到 conn的 context 里,因为在收到数据的时候还要用到 Entry,且弱引用不影响引用计数。
void EchoServer::onConnection(const TcpConnectionPtr& conn)
{
LOG_INFO << "EchoServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
EntryPtr entry(new Entry(conn));//连接到来的时候,创建entry对象来管理conn
connectionBuckets_.back().insert(entry);
dumpConnectionBuckets();
WeakEntryPtr weakEntry(entry);
conn->setContext(weakEntry);
}
else
{
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
LOG_DEBUG << "Entry use_count = " << weakEntry.use_count();
}
}
在收到消息时,从 TcpConnection 的 context 中取出 Entry 的弱引用,把它提升为强引用 EntryPtr,然后放到当前的 timing wheel 队尾。(提升为强引用的时候,引用计数+1)
void EchoServer::onMessage(const TcpConnectionPtr& conn,
Buffer* buf,
Timestamp time)
{
string msg(buf->retrieveAllAsString());
LOG_INFO << conn->name() << " echo " << msg.size()
<< " bytes at " << time.toString();
conn->send(msg);
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
EntryPtr entry(weakEntry.lock());
if (entry)
{
connectionBuckets_.back().insert(entry);
dumpConnectionBuckets();
}
}
总结:每个TcpConnection有一个上下文Context变量保存Entry的WeakPtr。 所谓上下文,就是变量,因为回调机制,每个连接都需要有其关联的Entry,这里直接用WeakPtr来作为上下文变量,不影响其引用计数。有了上下文,服务器每当收到客户端的消息时(onMessage),可以拿到与该连接关联的Entry的弱引用,再把它提升到强引用,插入到circular_buffer,这样就相当于把更新了该连接在时间轮盘里面的位置了,相应的use_count会加1。