
第2章:空间配置器
空间配置器概述
从STL的实现角度来看,空间配置器的位置尤为重要,整个STL的操作对象(所有的数值)都是存放在容器之内,而容器一定需要配置空间以存放资料。空间配置器就是为各个容器提供高效的管理空间。SGI STL的配置器与众不同,也与标准规范不同,其名称为alloc而非allocator,而且不接受任何参数。
不能采用标准写法:
vector<int,std::allocator<int>> iv; // inv VC or CB
应该写成:
vector<int,std::alloc> iv; // in GCC
而且在使用容器中,一般很少指定配置器名称,这时候默认缺省的配置器为alloc,例如:
template <class T,class Alloc = alloc> //缺省使用alloc为配置器
class vector {...};
其实SGI也存在标准的空间配置器std::allocator,但是因为效率不高,也不建议使用 一般而言,我们习惯的C++内存配置和释放操作是这样的:
class A {};
A* pa = new A;
//...执行其他操作
delete pa;
这过程中的new算式内含两阶段操作:
- 调用 ::operator new 配置内存;
- 调用 A::A() 构造对象内容。
delete算式也内含两阶段操作:
- 调用 A::~A() 将对象析构;
- 调用 ::operator delete 释放内存。
但是,为了最大化提升效率,SGI STL版本并没有简单的这样做,而是采取了一定的措施,实现了更加高效复杂的空间分配策略。在SGI STL中,将对象的构造切分开来,分成空间配置和对象构造两部分:
- 内存配置操作:alloc::allocate()实现
- 内存释放操作:alloc::deallocate()实现
- 对象构造操作: ::construct()实现
- 对象释放操作: ::destroy()实现
STL对象构造与释放结构图如下所示:
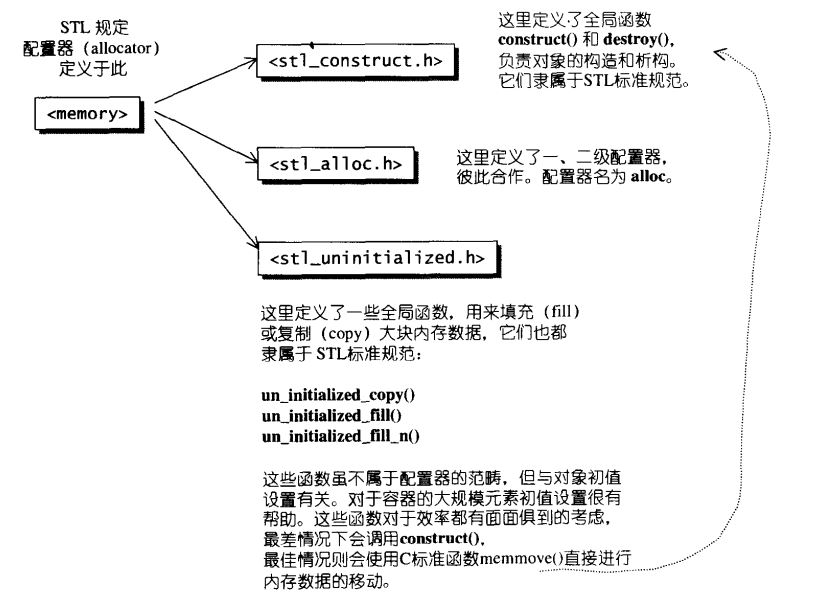
构造和析构基本工具
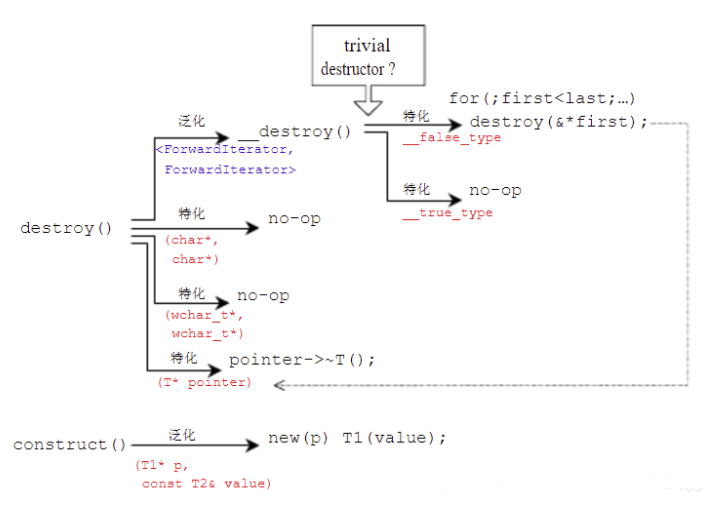
下面是<stl_construct.h>的部分内容,介绍了construct和destroy函数。
template <class T1, class T2>
inline void construct(T1* p, const T2& value) {
new (p) T1(value); // placement new; 唤起T1::T1(value)
}
// 第一个版本,接受一个参数
template <class Tp>
inline void destroy(Tp* pointer) {
pointer->~Tp(); // 调用dtor ~T()
}
// 第二个版本,接受两个迭代器,函数设法找出元素类别,进而利用 __type_traits<>使用最佳措施
template <class ForwardIterator>
inline void destroy(ForwardIterator first, ForwardIterator last) {
__destroy(first, last, VALUE_TYPE(first));
}
针对 construct和destroy函数的泛化和特化版本示意图如下:
空间的配置与释放,std::alloc
第二小节讲述了对象构造和对象析构的行为,现在来看看内存的配置和释放。在SGI版本的STL中,空间的配置和释放都由< stl_alloc.h > 负责。它的设计思想如下:
- 向system heap要求空间
- 考虑多线程(multi-thread)状态
- 考虑内存不足的应变措施
- 考虑过多“小型区块”可能导致的内存碎片问题(fragment)
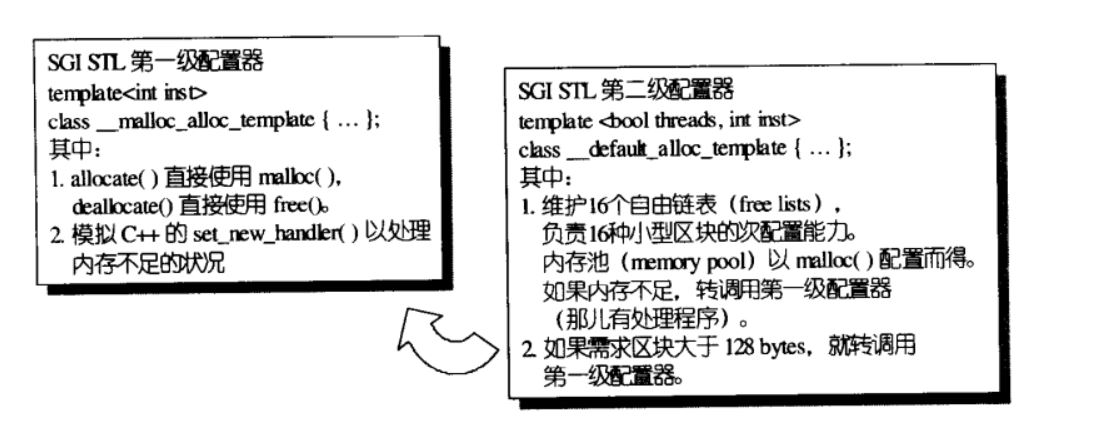
SGI采用malloc()和free()完成内存的配置与释放,考虑到小型区块所可能造成的内存碎片的问题,SGI设计了双层配置器,第一级配置器直接使用malloc()和free();第二级配置器则视情况采用不同的策略:当配置区块超过128bytes时,调用第一级配置器;当配置区块小于128bytes时,为了降低额外负担,便采用复杂的memory pool整理方式,而不再求助第一级配置。STL规定了 __USE_MALLOC 宏,如果它存在则直接调用第一级配置器,不然则直接调用第二级配置器。SGI STL未定义该宏,也就是说默认使用第二级配置器。
第一和第二级配置器的关系如下:
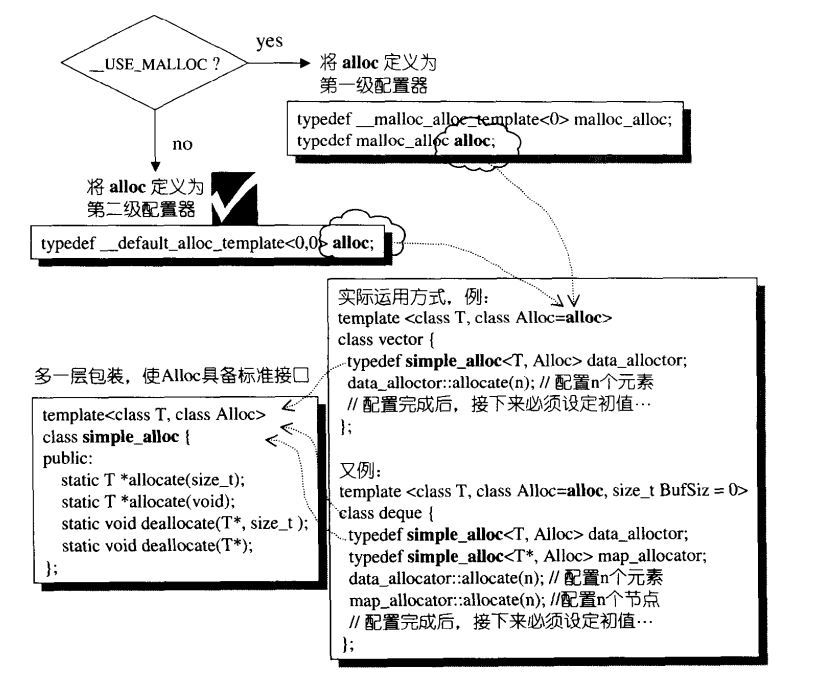
从上述图可以看出,SGI STL提供了一层更高级的封装,定义了一个simple _ alloc类,无论是用哪一级都以模板参数alloc传给simple _ alloc,这样对外体现都是只是simple _ alloc:
template<class _Tp, class _Alloc>
class simple_alloc {
public:
static _Tp* allocate(size_t __n)
{ return 0 == __n ? 0 : (_Tp*) _Alloc::allocate(__n * sizeof (_Tp)); }
static _Tp* allocate(void)
{ return (_Tp*) _Alloc::allocate(sizeof (_Tp)); }
static void deallocate(_Tp* __p, size_t __n)
{ if (0 != __n) _Alloc::deallocate(__p, __n * sizeof (_Tp)); }
static void deallocate(_Tp* __p)
{ _Alloc::deallocate(__p, sizeof (_Tp)); }
};
第一级配置器:直接调用malloc和free来配置释放内存,简单明了。
//㆒般而言是 thread-safe,并且对于空间的运用比较高效(efficient)。
//以下是第一级配置器。
//注意,无「template型别参数」。至于「非型别参数」inst,完全没派上用场。
template <int __inst>
class __malloc_alloc_template {
private:
// 函数指针,处理内存不足情况
static void* _S_oom_malloc(size_t);
static void* _S_oom_realloc(void*, size_t);
#ifndef __STL_STATIC_TEMPLATE_MEMBER_BUG
static void (* __malloc_alloc_oom_handler)();
#endif
public:
static void* allocate(size_t __n)
{
// 第一级配置器直接使用malloc
void* __result = malloc(__n);
// 无法满足需求时,改用oom方法
if (0 == __result) __result = _S_oom_malloc(__n);
return __result;
}
static void deallocate(void* __p, size_t /* __n */)
{
free(__p); // 第一级配置器直接使用free
}
static void* reallocate(void* __p, size_t /* old_sz */, size_t __new_sz)
{
// 第一级配置器直接使用realloc()
void* __result = realloc(__p, __new_sz);
// 无法满足需求时使用oom_realloc()
if (0 == __result) __result = _S_oom_realloc(__p, __new_sz);
return __result;
}
// 以下模拟c++的set_new_handler(),可以指定自己的oom handler
static void (* __set_malloc_handler(void (*__f)()))()
{
void (* __old)() = __malloc_alloc_oom_handler;
__malloc_alloc_oom_handler = __f;
return(__old);
}
};
第二级配置器:根据情况来判定,如果配置区块大于128bytes,说明“足够大”,调用第一级配置器,而小于等于128bytes,则采用复杂内存池(memory pool)来管理。第二级空间配置器的过程,重点关注allocate和deallocate这两个函数的具体实现。
static void* allocate(size_t n)
{
if (n > (size_t)__MAX_BYTES) // 字节数大于128,调用一级空间配置器
return malloc_alloc::allocate(n);
//不然到freelist去找
Obj* volatile* myFreeList = FreeList + FreeListIndex(n); //定位下标
Obj* ret = *myFreeList;
if (ret == NULL)
{
void* r = refill(Round_UP(n));//没有可用free list 准备装填
}
*myFreeList = ret->freeListLink;
return ret;
}
可以看出allocate的处理逻辑为:
- 如果用户需要的区块大于128,则直接调用第一级空间配置器
- 如果用户需要的区块小于等于128,则到自由链表中去找
- 如果自由链表有,则直接去取走
- 不然则需要装填自由链表(refill)
static void deallocate(void* p, size_t n)
{
if (n > (size_t)__MAX_BYTES) //区块大于128, 则直接由第一级空间配置器收回
malloc_alloc::deallocate(p, n);
Obj* volatile* myFreeList = FreeList + FreeListIndex(n);
Obj* q = (Obj*)p;
q->freeListLink = *myFreeList;
*myFreeList = q;
}
释放操作deallocate和上面处理类似:
- 如果区块大于128, 则直接由第一级空间配置器收回
- 如果区块小于等于128, 则有自由链表收回
我们在上面重点分析了整体思路,也就是二级配置器如何配置和申请内存,他们和一级配置器一样都提供allocate和deallocate的接口(其实还有个reallocate也是用于分配内存,类似于C语言中realloc函数),我们都提到了一点自由链表,那么自由链表是个什么?
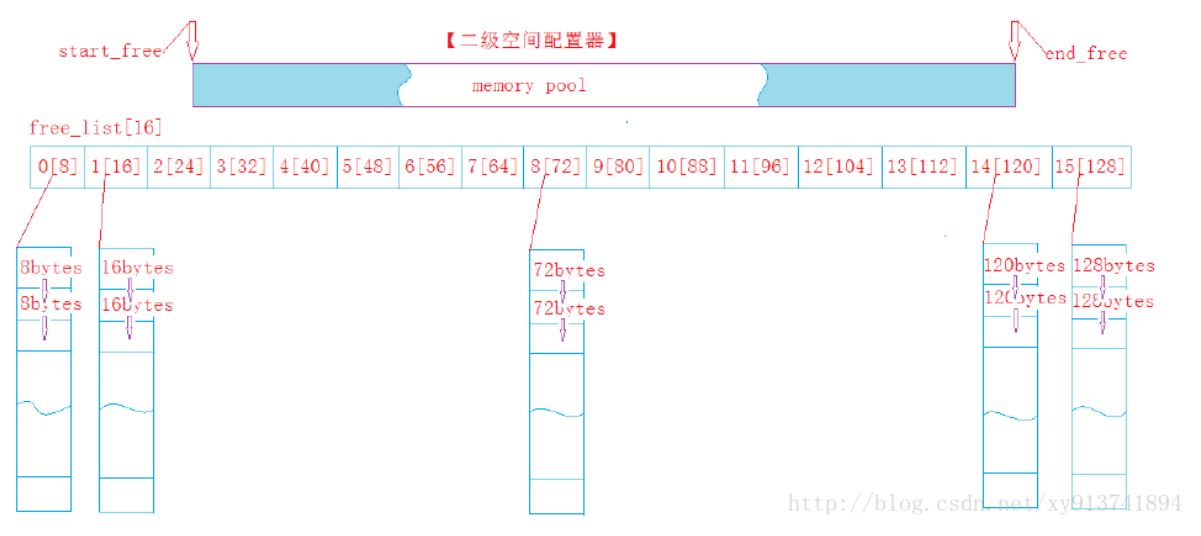
如上图所示,自由链表是一个指针数组,有点类似与hash桶,它的数组大小为16,每个数组元素代表所挂的区块大小,比如free _ list[0]代表下面挂的是8bytes的区块,free _ list[1]代表下面挂的是16bytes的区块…….依次类推,直到free _ list[15]代表下面挂的是128bytes的区块。同时,我们还有一个被称为内存池地方,以start _ free和 end _ free记录其大小,用于保存未被挂在自由链表的区块,它和自由链表构成了伙伴系统。
我们之前讲了,如果用户申请小于等于128的区块,就到自由链表中取,但是如果自由链表对应的位置没了怎么办???这下子就轮到我们的内存池就发挥作用了!
下面重点讲述一下,如果自由链表对应的位置没有所需的内存块,那么应该如何处理,即refill函数的实现。
static void* allocate(size_t n)
{
//...
if (ret == NULL)
{
void* r = refill(Round_UP(n));//没有可用free list 准备装填
}
//...
}
//freelist没有可用区块,将要填充,此时新的空间取自内存池
static void* refill(size_t n)
{
size_t nobjs = 20;
char* chunk = (char*)ChunkAlloc(n, nobjs); //默认获得20的新节点,但是也可能小于20,可能会改变nobjs
if (nobjs == 1) //如果只有一块直接返回调用者,此时freelist无结点
return chunk;
//有多块,返回一块给调用者,其他挂在自由链表中
Obj* ret = (Obj*)chunk;
Obj* cur = (Obj*)(chunk + n);
Obj* next = cur;
Obj* volatile *myFreeList = FreeList + FreeListIndex(n);
*myFreeList = cur;
for (size_t i = 1; i < nobjs; ++i)
{
next = (Obj*)((char*)cur + n);
cur->freeListLink = next;
cur = next;
}
cur->freeListLink = NULL;
return ret;
}
这里面的重点函数为ChunkAlloc,它的逻辑相对复杂,代码如下:
static char* ChunkAlloc(size_t size, size_t& nobjs)
{
size_t bytesLeft = endFree - startFree; //内存池剩余空间
size_t totalBytes = size * nobjs;
char* ret = NULL;
if (bytesLeft >= totalBytes) // 内存池大小足够分配nobjs个对象大小
{
ret = startFree;
startFree += totalBytes;
return ret;
}
else if (bytesLeft >= size) // 内存池大小不够分配nobjs,但是至少分配一个
{
size_t nobjs = bytesLeft / size;
totalBytes = size * nobjs;
ret = startFree;
startFree += totalBytes;
return ret;
}
else // 内存池一个都分配不了
{
//让内存池剩余的那么点挂在freelist上
if (bytesLeft > 0)
{
size_t index = FreeListIndex(bytesLeft);
((Obj*)startFree)->freeListLink = FreeList[index];
FreeList[index] = (Obj*)startFree;
}
size_t bytesToGet = 2 * totalBytes + RoundUP(heapSize >> 4);
startFree = (char*)malloc(bytesToGet);
if (startFree == NULL)
{
//申请失败,此时试着在自由链表中找
for (size_t i = size; i <= __MAX_BYTES; i += __ALIGN)
{
size_t index = FreeListIndex(i);
Obj* volatile* myFreeList = FreeList + index;
Obj* p = *myFreeList;
if (FreeList[index] != NULL)
{
FreeList[index] = p->freeListLink;
startFree = (char*)p;
endFree = startFree + i;
return ChunkAlloc(size, nobjs);
}
}
endFree = NULL;
//试着调用一级空间配置器
startFree = (char*)MallocAlloc::Allocate(bytesToGet);
}
heapSize += bytesToGet;
endFree = startFree + bytesToGet;
return ChunkAlloc(size, nobjs);
}
}
分析上述代码,我们知道当自由链表中没有对应的内存块,系统会执行以下策略:
如果用户需要是一块n字节的区块,且n <= 128(调用第二级配置器),此时refill填充是这样的:(需要注意的是**:系统会自动将n字节扩展到8的倍数也就是Round_UP(n),再将Round_UP(n)传给refill)。用户需要n块,且自由链表中没有,因此系统会向内存池申请nobjs * n大小的内存块**,默认nobjs=20
- 如果内存池大于 nobjs * n,那么直接从内存池中取出
- 如果内存池小于nobjs * n,但是比一块大小n要大,那么此时将内存最大可分配的块数给自由链表,并且更新nobjs为最大分配块数x (x < nobjs)
- 如果内存池连一个区块的大小n都无法提供,那么首先先将内存池残余的零头给挂在自由链表上,然后向系统heap申请空间,申请成功则返回,申请失败则到自己的自由链表中看看还有没有可用区块返回,如果连自由链表都没了最后会调用一级配置器.
这就是ChunkAlloc所执行的操作,在执行完ChunkAlloc函数后会获得内存(失败就抛出异常),此时也就是这段代码:
if (nobjs == 1) //如果只有一块直接返回调用者,此时freelist无结点
return chunk;
//有多块,返回一块给调用者,其他挂在自由链表中
Obj* ret = (Obj*)chunk;
Obj* cur = (Obj*)(chunk + n);
Obj* next = cur;
Obj* volatile *myFreeList = FreeList + FreeListIndex(n);
*myFreeList = cur;
for (size_t i = 1; i < nobjs; ++i)
{
next = (Obj*)((char*)cur + n);
cur->freeListLink = next;
cur = next;
}
cur->freeListLink = NULL;
如果只有一块返回给调用者,有多块,返回给调用者一块,剩下的挂在对应的位置。
# 内存基本处理工具
STL定义有五个全局函数,这五个函数分别是construct(),destory(),uninitialized_copy(),uninitialized_fill(),uninitialized_fill_n(),都作用与未初始化的内存空间上。construct()和destory()上述章节已经讲解过,不再赘述。现在让我们了解下另外三个函数:uninitialized_copy(),uninitialized_fill(),uninitialized_fill_n(),分别对应于高层次函数copy()、fill()、fill_n()——这些都是STL的算法。它们都能够将内存的配置和对象的构造行为分离开来。
- uninitialized_copy() 首先会在内存中分配一片内存(未构造),然后接受输入端的开始迭代器和输入端结束迭代器,对此输入的对象进行copy,然后放进分配的未构造的内存中。
template inline ForwardIterator uninitialized_copy(InputIterator first, InputIterator last, ForwardIterator result)
{
return _uninitialized_copy(first, last, result, value_type(result));
//以上利用value_type()取出first的value_type
}
template inline ForwardIterator _uninitialized_copy(InputIterator first, InputIterator last, ForwardIterator result, T*)
{
typedef typename _type_traits::is_POD_type is_POD;
return _uninitialized_copy_aux(first,last,result,is_POD());
}
//如果是POD型别,执行流程就会转到以下函数
template inline ForwardIterator _uninitialized_copy_aux(InputIterator first, InputIterator last, ForwardIterator result, _true_type)
{
return copy(first,last,result); //调用STL算法copy,效率高
}
//如果不是POD型别,执行流程就会转到以下函数
template
ForwardIterator _uninitialized_copy_aux(InputIterator first, InputIterator last, ForwardIterator result, _false_type)
{
ForwardIterator cur = result;
for (; first != last; ++first, ++cur)
construct(&*cur,*first); //必须一个一个元素构造,无法批量处理
return cur;
}
这个函数的逻辑是,首先萃取出迭代器result的value type,然后判断该型别是否为POD型别。POD意指Plain Old Data,也就是标量型别(scalar types)或传统的C struct型别。POD型别必然拥有 trivial ctor/dtor/copy/assignment函数,因此我们可以对POD型别采用最有效率的复制手法(采用STL的copy函数),而对non-POD型别采用最保险安全的做法(采用construct函数,一个个构造)。
uninitialized_fill()接受输入端的开始迭代器和输入端的结束迭代器(此范围内的迭代器指向未构造的内存),然后接受一个对象,把对象copy到此迭代器指向的未初始化的内存,也就是它会将指定范围内的未构造的内存指定相同的对象。
template inline void uninitialized_fill(ForwardIterator first,ForwardIterator last,const T& x)
{
_uninitialized_fill(first, last, x, value_type(first));
//以上利用 value_type()取出first的 value_type
}
template inline void _uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x, T1*)
{
typedef typename _type_traits::is_POD_type is_POD;
_uninitialized_fill_aux(first, last, x, is_POD());
}
//如果是POD型别,执行流程就会转到以下函数
template inline void _uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, _true_type)
{
fill(first, last, x); //调用STL算法fill
}
//如果不是POD型别,执行流程就会转到以下函数
template inline void _uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, _false_type)
{
ForwardIterator cur = first;
for (; cur!=last;++cur)
construct(&*cur, x); //必须一个一个元素构造,无法批量处理
}
这个函数的逻辑是,与上述uninitialized_fill处理类似。对POD型别采用最有效率的复制手法(采用STL的fill函数),而对non-POD型别采用最保险安全的做法(采用construct函数,一个个构造)。
uniniyialized_fill_n()接受输入端的开始处的迭代器(此分配的内存是未构造的)和初始化空间的大小,最重要的是它会给指定范围内的未构造的内存指定相同的对象。
template inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x)
{
return uninitialized_fill_n(first,n,x,value_type(first));
//以上利用 value_type()取出first的 value_type
}
template inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x, T1*)
{
typedef typename _type_traits::is_POD_type is_POD;
return uninitialized_fill_n_aux(first, n, x, is_POD());
}
//如果是POD型别,执行流程就会转到以下函数
template inline ForwardIterator uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, _true_type)
{
return fill_n(first,n,x); //调用STL算法fill_n
}
//如果不是POD型别,执行流程就会转到以下函数
template ForwardIterator uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, _false_type)
{
ForwardIterator cur = first;
for (; n > 0; --n, ++cur)
construct(&*cur,x); //必须一个一个元素构造,无法批量处理
return cur;
}
这个函数的逻辑是,与上述uninitialized_fill处理类似。对POD型别采用最有效率的复制手法(采用STL的fill_n函数),而对non-POD型别采用最保险安全的做法(采用construct函数,一个个构造)。
总结
uninitialized_copy(),uninitialized_fill(),uninitialized_fill_n()都会根据迭代器的value type,判断其是否为POD型别:
- 为POD型别的对象提供高阶函数以提高处理效率;
- 为non-POD型别提供construct函数以保证构造过程。