
第11章 网络编程
参考资料
网络编程
客户端-服务器编程模型
网络应用都是基于客户端-服务器模型的。采用此模型,一个应用是由一个服务器进程和一个或多个客户端进程组成的。
服务器管理某种资源,并通过操作这种资源来为它的客户端提供服务。
客户端-服务器模型中的基本操作是事务。一个客户端-服务器事务包括以下四步:
- 客户端需要服务时,向服务器发送一个请求,发起一个事务。比如客户端请求下载某个文件。
- 服务器收到请求后,解释它并以适当方式操作自己的资源。比如服务器从磁盘读客户端所请求的文件。
- 服务器给客户端发送一个响应,并等待下一个请求。比如将客户端请求的文件发送给客户端。
- 客户端收到响应并处理它。比如客户端下载收到的文件。

注意客户端和服务器都是进程,两者可以在一台主机上也可以在不同的主机上。
网络
对主机而言,网络是只是又一种 I/O 设备,是数据源和数据接收方。
一个插到 I/O 总线扩展槽的**网络适配器(又称网卡)**提供了到网络的物理接口。从网络接收到的数据从适配器经过 I/O 和内存总线复制到内存,通常是 DMA 传送。相似地,数据也能从内存负责到网络。
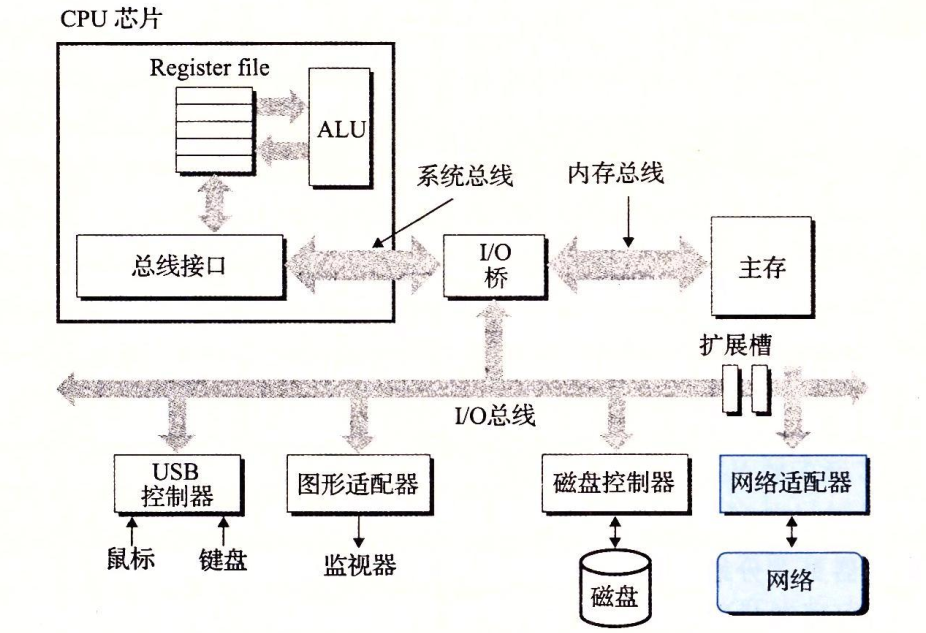
物理上而言,网络是一个按照地理远近组成的层次系统,最底层是 LAN(局域网),以太网是最流行的局域网技术。
在一个以太网中,多台主机通过电缆连接到一个集线器上。多个以太网可以通过网桥连接起来构成一个桥接以太网。
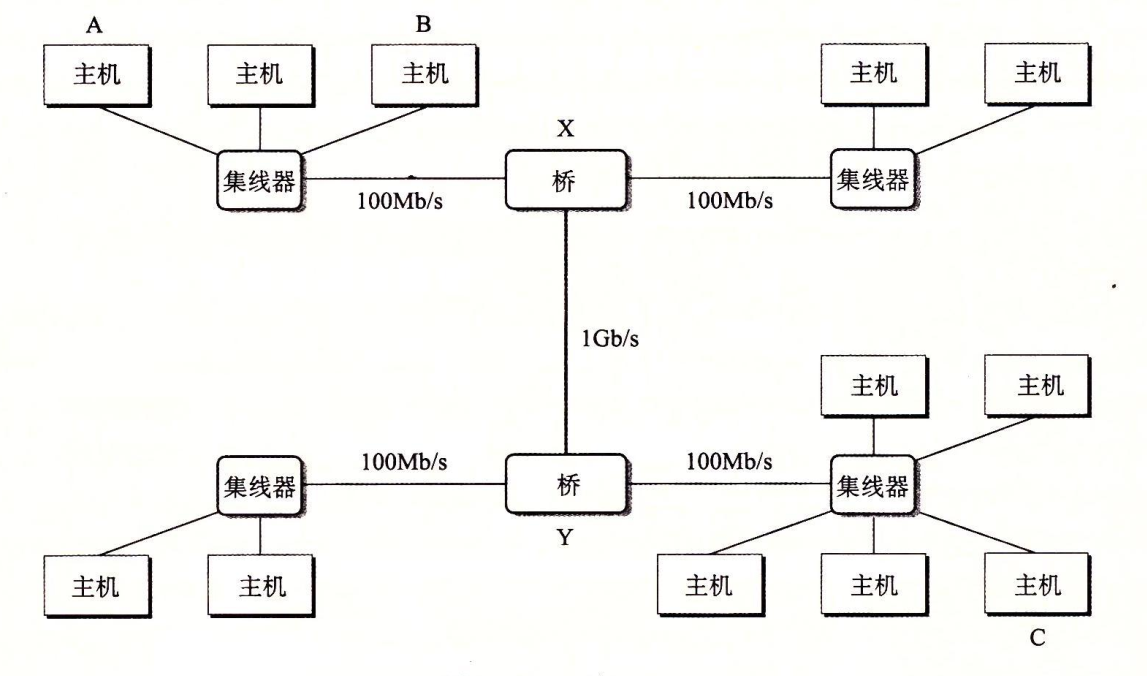
在层次的更高级别中,多个不兼容的局域网可以通过路由器的特殊计算机连接起来,组成internet。
每台路由器对于它所连接到的每个网络都有一个适配器。路由器也能连接高速点到点电话连接,这是称为WAN(Wide-Area-Network,广域网)
网络的重要特性:它能由采用完全不同和不兼容技术的各种局域网和广域网组成。
解决方法:利用主机和路由器上的协议软件,它消除了不同网格之间的差异。
网络协议要具备的两个基本能力:
- 命名机制:提供一种一致的主机地址格式来表示主机地址。
- 传送机制:定义了统一格式的协议数据单元来传送数据。
从客户端 A 发送数据到服务器端 B 的基本步骤
- 主机 A 上的客户端进行一个系统调用,从客户端的虚拟地址空间复制数据到内核缓冲区中。
- 主机 A 上的协议软件通过在数据前附加互联网络包头和 LAN1 帧头,创建了一个 LAN1 的帧,然后传送此帧到适配器。其中 LAN1 帧头寻址到路由器(理解:这应该是指链路层分组的首部,MAC地址),互联网络包头寻址到主机 B(理解:这应该指网络层 IP 数据报的首部,IP地址)。
- LAN1 适配器把该帧复制到网络上。
- 此帧到达路由器时,路由器的 LAN1 适配器从电缆上读取它,并把它传送到协议软件。
- 路由器从互联网络包头中提取出目的互联网络地址,并用它作为路由表的索引,确定向哪里转发这个包(本例中为 LAN2),路由器剥落掉旧的 LAN1 帧头,加上寻址到主机 B 的 LAN2 帧头,并把得到的帧传送到适配器。
- 路由器的 LAN2 适配器复制该帧到网络上。
- 此帧到达主机 B 时,它的适配器从电缆上读到此帧,并将它传送到协议软件。
- 主机 B 上的协议软件剥落掉包头和帧头。当服务器进行一个读取这些数据的系统调用时,协议软件最终将得到的数据复制到服务器的虚拟地址空间。
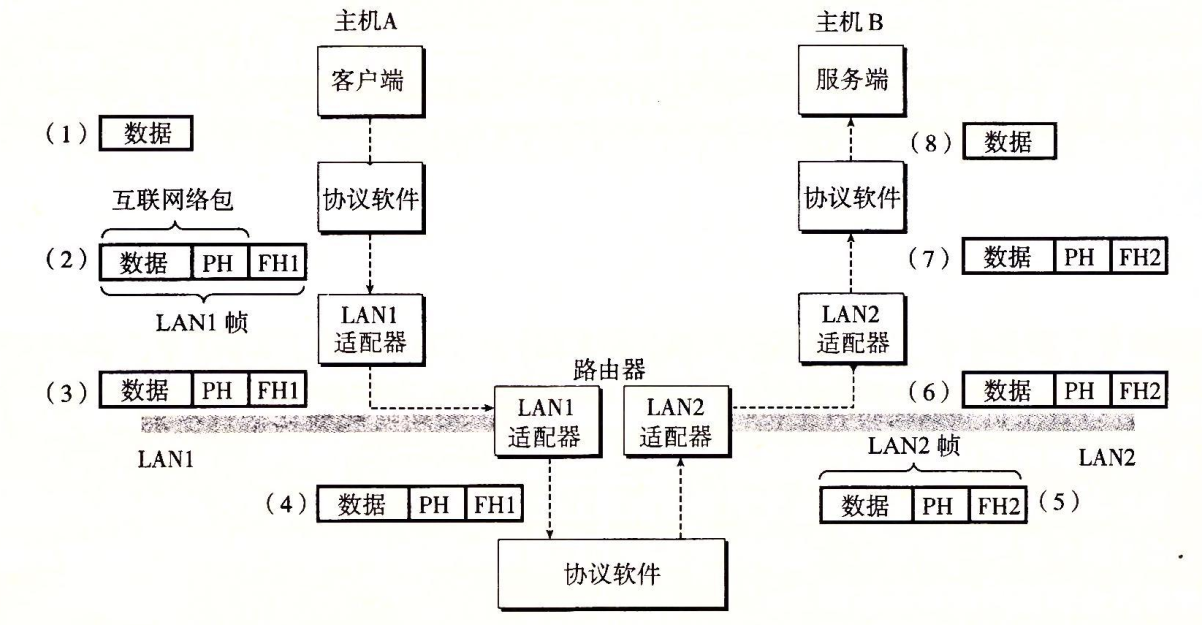
总结:以上 8 个步骤可以分为两部分:数据在主机上通过系统调用在进程的虚拟地址空间与内核间传送,数据在网络间传送。
全球IP因特网
全球 IP 因特网即互联网。互联网中的每台主机都有实现 TCP/IP 协议的软件。
互联网中的客户端和服务器混合使用套接字接口函数和 Unix I/O 函数来进行通信。通常将套接字函数实现为系统调用,这些系统调用会陷入内核,并调用各种内核模式的 TCP/IP 函数。
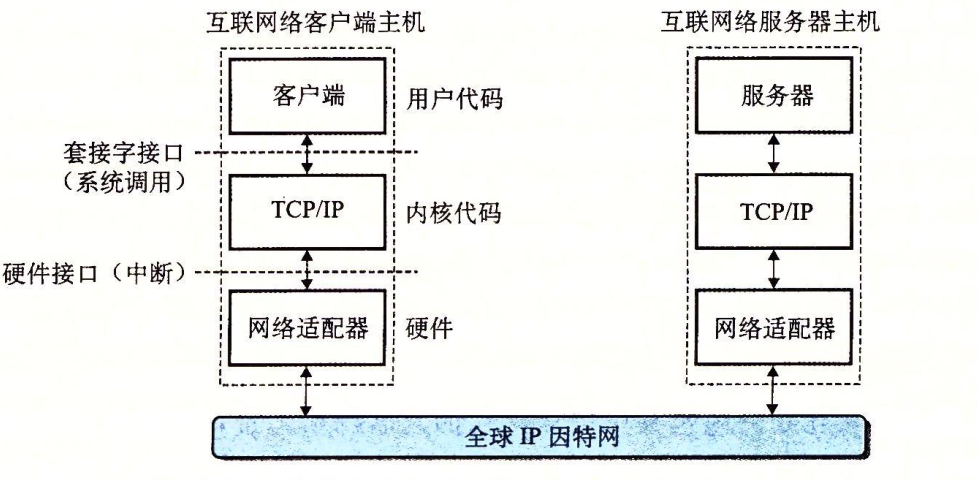
客户端和服务器通过因特网这个全球网络来通信。从程序员的观点来看,我们可以把因特网看成是一个全球范围的主机集合,具有以下几个属性:
1、每个因特网主机都有一个唯一的 32 为名字,称为它的 IP 地址。(现在已经扩展到IPV6,128位的IP地址)
2、IP 地址的集合被映射为一个因特网域名的集合
3、不同因特网主机上的进程能够通过链接互相通信
IP地址
一个 IP 地址就是一个 32 位无符号整数。网络程序将 IP 地址存放在下面的 IP 地址结构中。
struct in_addr {
uint32_t s_addr;
} // 以网络字节顺序(大端法)存储,即使主机字节顺序是小端法。
TCP/IP 定义的统一的网络字节顺序为大端字节顺序。Unix 提供了几个函数来在网络和主机字节顺序间实现转换。
现在的 intel 系统主要都是小端序。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort); //返回网络字节顺序
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort); //返回按照主机字节顺序的值
二进制IP地址与点分十进制串之间的转换
#include <arpa/inet.h>
int inet_pton(AF_INET, const char *src, void *dst); //将点分十进制转换为二进制的网络字节顺序的 IP 地址。成功则返回 1,如果 src 为非法地址则返回 0,出错返回 -1。
const char *inet_ntop(AF_INET, const void*src, char *dst, socklen_t size); //将二进制网络字节顺序的 IP 地址转换为点分十进制,并把得到的字符串最多 size 个字节复制到 dst。
//如果成功返回点分十进制串的指针,若出错返回 NULL。
因特网域名
域名到 IP 地址之间的映射通过分布在世界各地的数据库来维护。
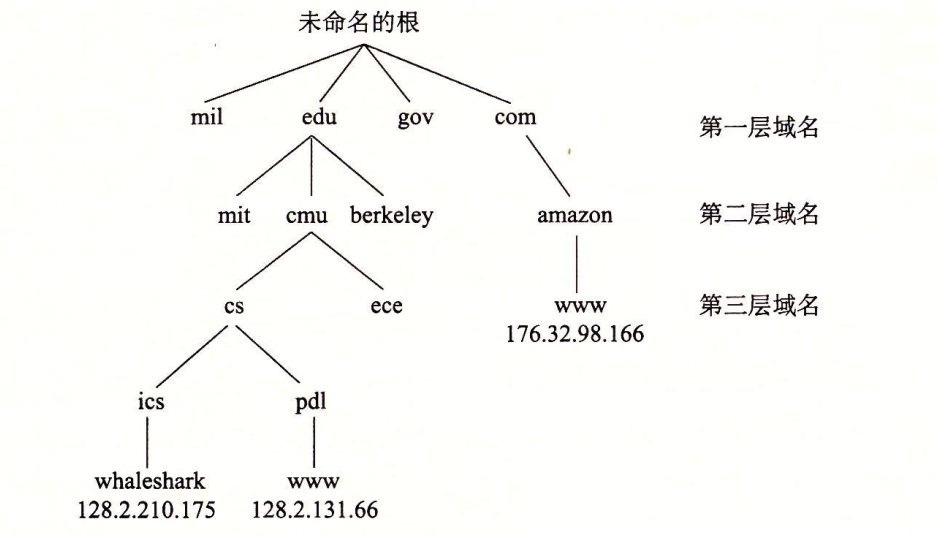
DNS 数据库包含上百万条主机条目结构,每一条定义了一组域名和一组 IP 地址之间的映射。
每台主机都有本地定义的域名 localhost,这个域名总是映射为回送地址 127.0.0.1。
linux>>nslookup localhost // 查看域名 localhost 的地址
Address:127.0.0.1
linux>>hostname // 查看本机的域名
多个域名可以映射到同一个 IP 地址,最常见的情况是多个域名映射到同一组的多个 IP 地址。
因特网连接
客户端和服务器通过在连接上接收和发送字节流来通信。连接是点对点的与全双工的。
连接的端点是套接字,套接字地址由一个 IP 地址和一个 16 位的端口号组成。用 “地址:端口” 来表示。
客户端套接字地址中的端口是由内核自动分配的临时端口,服务器套接字地址中的端口通常是某个熟知端口。
Web 服务器常用端口 80,熟知名字为 http;邮件服务器使用端口 80,熟知名字为 smtp。
文件/etc/services 中包含一张主机提供的熟知端口与熟知名字之间的映射。
一个连接由两端的套接字地址唯一确定。

套接字接口
套接字接口是一组函数,和 Unix I/O 函数结合起来创建网络应用。
套接字地址结构
从内核角度看,套接字是通信的端点;从程序的角度看,套接字是一个有相应描述符的打开文件。
套接字地址存放在 sockaddr_in 结构中。
'互联网套接字地址结构'
struct sockaddr_in {
uint16_t sin_family; // 协议族
uint16_t sin_port; // 网络字节顺序的端口号
struct in_addr sin_addr; // 网络字节顺序的 IP 地址
unsigned char sin_zero[8];
}
'通用套接字地址结构'
struct sockaddr {
uint16_t sa_family; // 协议族
char sa_data[14]; // 地址
}
connect, bind, accept 函数都接受一个指向通用 sockaddr 结构的指针,然后要求应用程序将于协议特定结构相关的指针强制转换成这个通用结构。
对应头文件需要包含#include<sys/types.h>,#include<sys/socket.h>。
socket函数
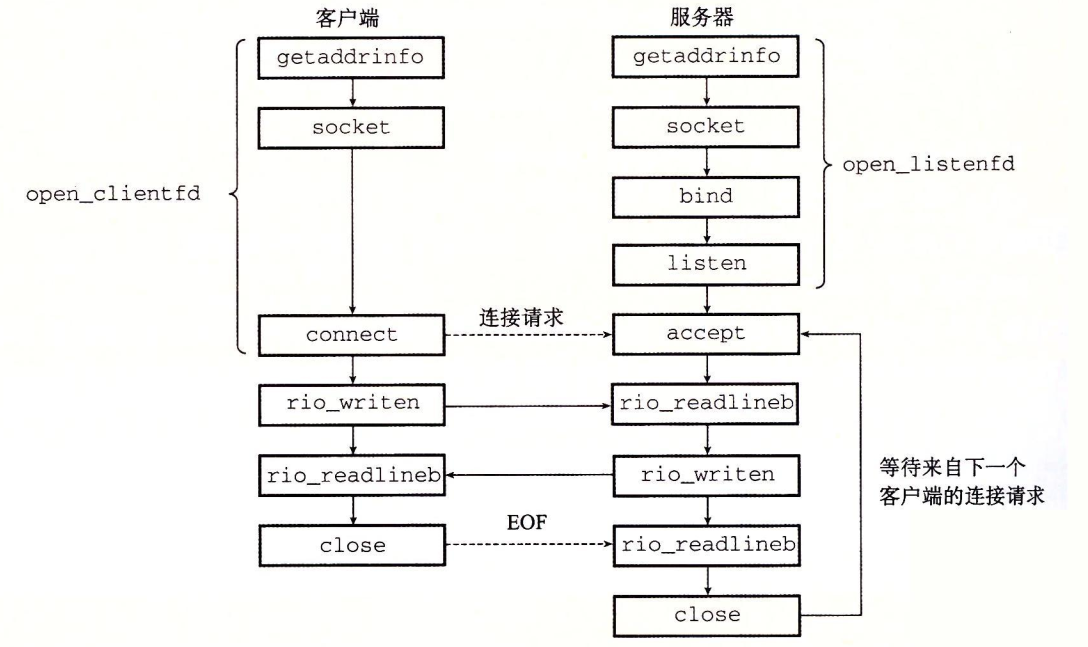
客户端和服务器都使用 socket 函数来创建一个套接字描述符。
int socket(int domain, int type, int protocol); // 如果成功返回描述符,出错返回 -1
socket 函数的使用
可以通过如下方式使套接字成为连接的一个端点。但最好使用 getaddrinfo 函数来自动生成这些参数,这样可以让代码与协议无关。
clientfd = socket(AF_INET, SOCK_STREAM, 0); // AF_INET 表示使用 32 位 IP 地址, SOCK_STREAM 表示这个套接字是连接的一个端点。
socket 返回的 clientfd 描述符仅是部分打开的,还不能用于读写。如何完成打开套接字的工作,取决于是客户端还是服务器。
connect函数
客户端通过调用 connect 函数来建立和服务器的连接。
int connect(int clientfd, const struct sockaddr* addr, socklen_t addrlen); // 若成功返回 0,若出错返回 -1。
connect 函数会阻塞,一直到连接成功建立或发生错误。
bind函数
bind, listen 和 accept 函数都是服务器端用的函数。
bind 函数用来将套接字描述符和套接字地址关联起来。
int bind(int sockfd, const struct sockaddr* addr, socklen_t addrlen); // 若成功返回 0,若出错返回 -1。
listen函数
listen 函数将套接字转换为监听状态。
int listen(int sockfd, int backlog) // 若成功返回 0,若出错返回 -1。
accept函数
accept 函数用来接受来自客户端的连接请求。
int accept(int listenfd, struct sockaddr* addr, int* addrlen); // 若成功返回已连接描述符,若出错返回 -1。
总结
每个网络应用都是基于客户端-服务器模型的。根据这个模型,一个应用是由一个服务器和一个或多个客户端组成的。服务器管理资源,以某种方式操作资源,为它的客户端提供服务。客户端-服务器模型中的基本操作是客户端-服务器事务,它是由客户端请求和跟随其后的服务器响应组成的。
客户端和服务器通过因特网这个全球网络来通信。从程序员的观点来看,我们可以把因特网看成是一个全球范围的主机集合,具有以下几个属性:(1)每个因特网主机都有一个唯一的 32 位名字,称为它的 IP 地址。(2)IP 地址的集合被映射为一个因特网域名的集合。(3)不同因特网主机上的进程能够通过连接互相通信。
客户端和服务器通过使用套接字接口建立连接。一个套接字是连接的一个端点,连接以文件描述符的形式提供给应用程序。套接字接口提供了打开和关闭套接字描述符的函数。客户端和服务器通过读写这些描述符来实现彼此间的通信。
Web 服务器使用 HTTP 协议和它们的客户端(例如浏览器)彼此通信。浏览器向服务器请求静态或者动态的内容。对静态内容的请求是通过从服务器磁盘取得文件并把它返回给客户端来服务的。对动态内容的请求是通过在服务器上一个子进程的上下文中运行一个程序并将它的输出返回给客户端来服务的。CGI 标准提供了一组规则,来管理客户端如何将程序参数传递给服务器,服务器如何将这些参数以及其他信息传递给子进程,以及子进程如何将它的输出发送回客户端。只用几百行 C 代码就能实现一个简单但是有效的 Web 服务器,它既可以提供静态内容,也可以提供动态内容。