
第12章 系统调用与API
文章总结
系统调用介绍
每个操作系统都会提供一套接口,以供应用程序使用。这些接口往往通过中断来实现,比如Linux使用0x80号中断作为系统调用的入口,Windows采用0x2E号中断作为系统调用入口。
事实上Windows系统从Windows1.0以来到最新的Windows Vista,这数十年间API的数量从最初1.0时的450个增加到了现在的数千个,但是很少对已有的API进行改变。因为API一旦改变,很多应用程序将无法正常运行。
Linux系统调用
在x86下,调用由0x80中断完成,各个通用寄存器用于传递参数,EAX寄存器用于表示系统调用的接口号,比如EAX=1表示退出进程(exit);EAX=2表示创建进程(fork);EAX=3表示读取文件或IO(read);EAX=4表示写文件或IO(write),每个系统调用都对应于内核源代码中的一个函数,它们都是以“sys_”开头的,比如exit调用对应内核中的sys_exit函数。当系统调用返回时,EAX又作为调用结果的返回值。
弊端
大部分系统调用有两个特点:
- 使用不便
- 各个操作系统之间系统调用不兼容
运行时库将不同的操作系统的系统调用包装为统一固定的接口,使得同样的代码,在不同的操作系统下都可以直接编译,一致的效果。这就是源代码级上的可移植性。
但是运行库也有运行库的缺陷,比如c语言的运行库为了保证多个平台之间能够相互通用,于是它只能取各个平台之间功能的交集。
系统调用原理
特权级与中断
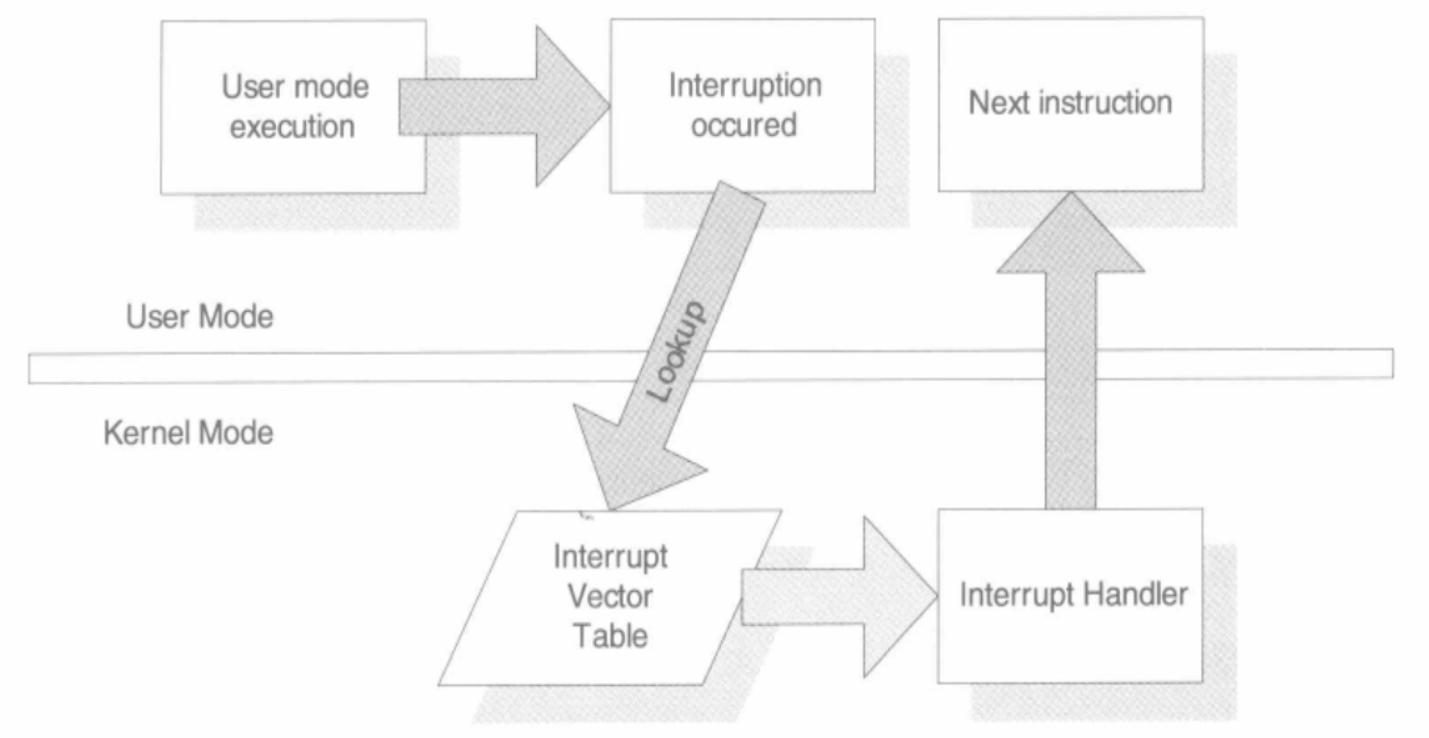
操作系统一般是通过中断(Interrupt)来从用户态切换成内核态。中断一般具有两个属性,一个称为中断号(从0开始),一个称为中断处理程序(Interrupt Service Routine, ISR)。不同的中断具有不同的中断号,而同时一个中断处理程序一一对应一个中断号。在内核中,有一个数组称为中断向量表(lnterrupt Vector Table),这个数组的第n项包含了指向第n号中断的中断处理程序的指针。当中断到来时,CPU会暂停当前执行的代码,根据中断的中断号,在中断向量表中找到对应的中断处理程序,并调用它。中断处理程序执行完成之后,CPU会继续执行之前的代码。
基于int的Linux的经典系统调用实现
以fork为例的Linux系统调用的执行流程:

- 触发中断
- 切换堆栈
- ESP的值从位于用户栈,切换到内核栈
- 中断处理程序
