
第3章 - Data 语意学
概述
//sizeof X == 1
class X{}
即使一个类什么内容都没有,它有隐藏的1byte大小,是被编译器安插进去的一个char, 这使得这一class的两个objects得以在内存中配置独一无二的地址。
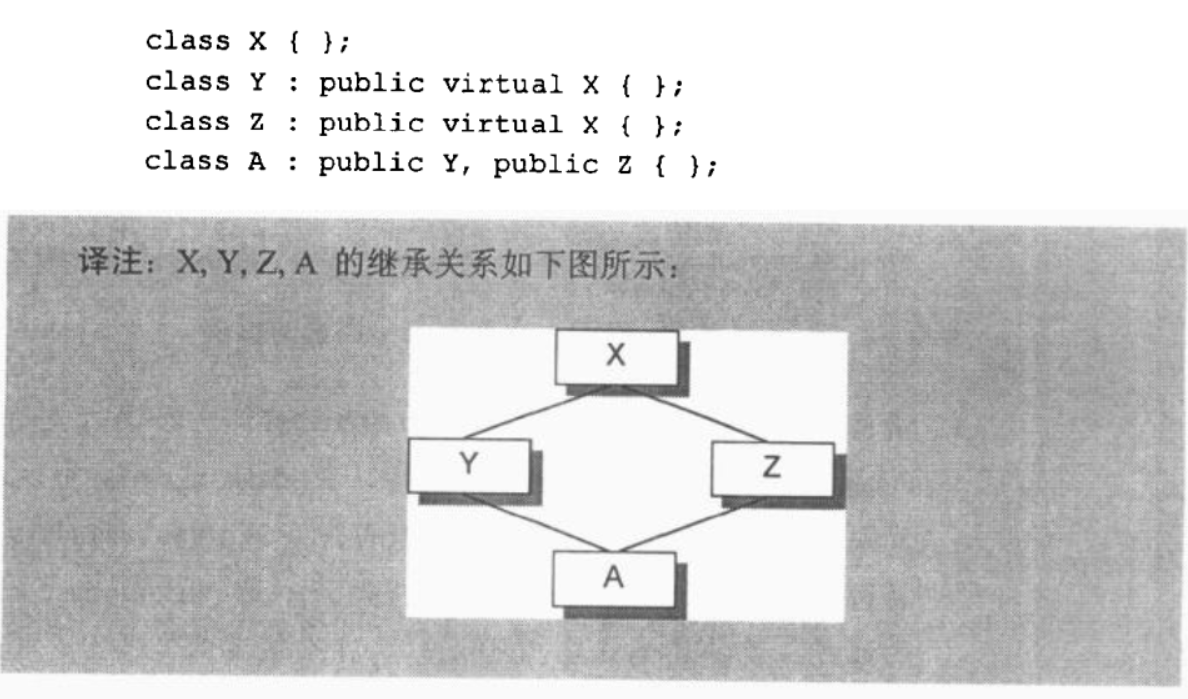
Y和Z的大小受到三个因素的影响:
- 语言本身所造成的额外负担。支持虚基类,需要引入vptr。
- 编译器对于特殊情况所提供的优化处理。Virtual base class X subobject的1 bytes大小也出现在 class Y 和 Z 身上。
- Alignment 的限制。字节对齐,Y和Z目前是5 bytes,需要填补3 bytes,最终结果是8 bytes。
对象布局如下:
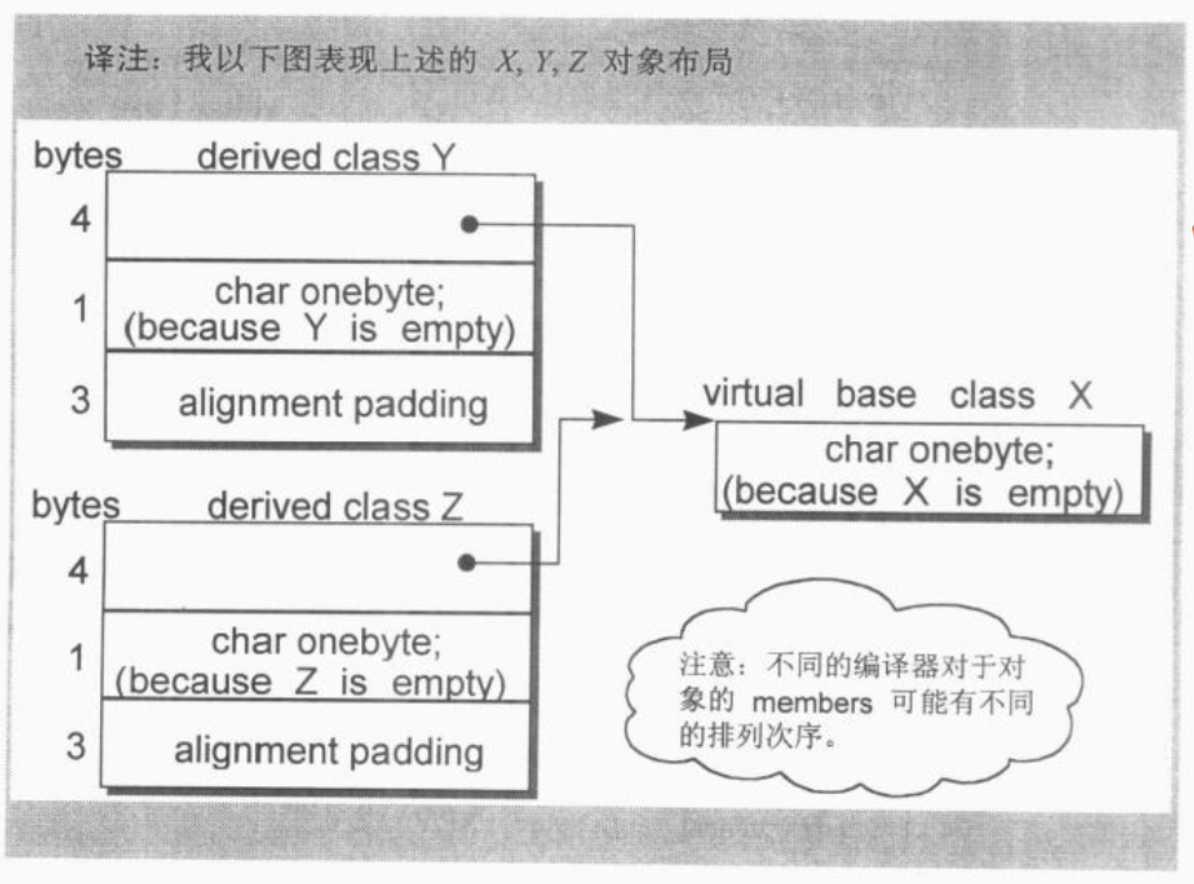
Empty virtual base class已经成为C++OO设计的一个特有术语了,它提供一个virtual interface,没有定义任何数据。某些新近的编译器对此提供了特殊处理。在这个策略之下,一个empty virtual base class被视为derived class object最开头的一部分,也就是说它并没有花费任何的额外空间。
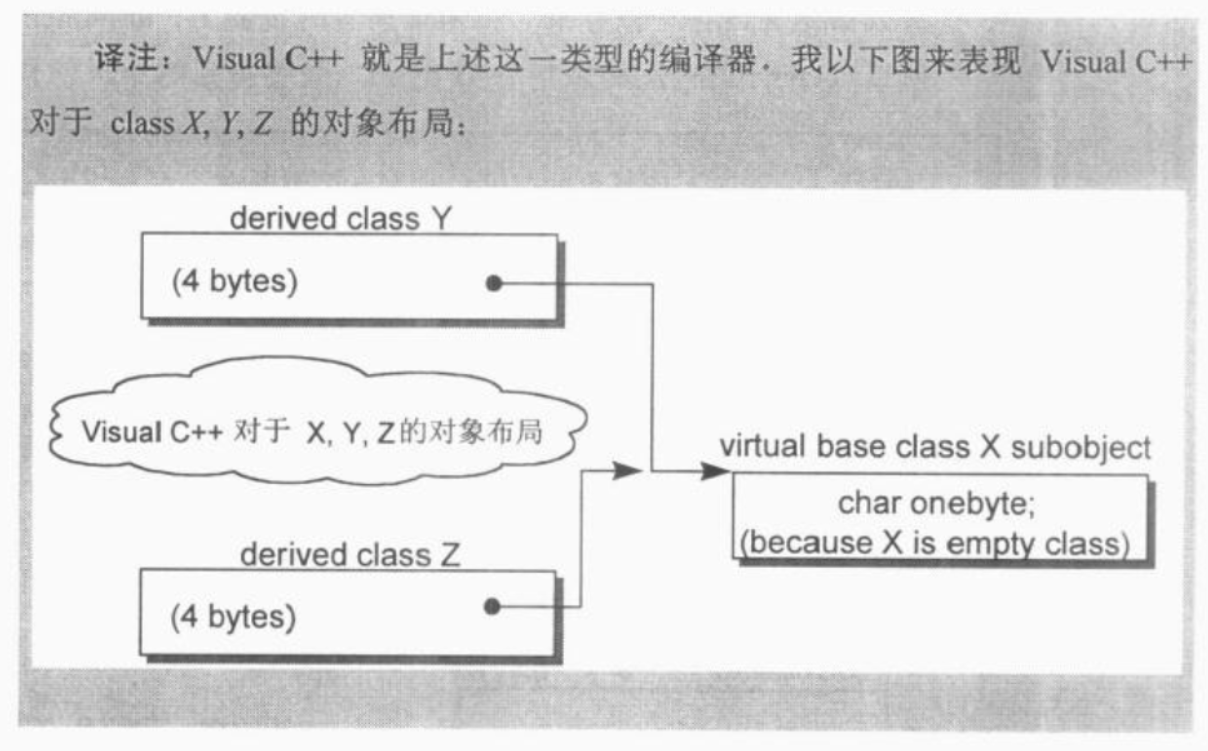
如果Virtual base class X中放置一个以上的data member,两种编译器(有特殊处理 和 没有特殊处理)就会产生出完全相同的对象布局。
C++对象模型尽量以空间优化和存取速度优化的考虑来表现non static data members,并且保持和c语言struct数据配置的兼容性,它把数据直接存放在每 一个class object之中。对于继承而来的non static data members(不管是virtual或non virtual base class)也是如此。不过并没有强制定义其间的排列顺序。
Data Member的绑定(The Binding of a Date Member)
抛砖引玉:
extern float x;
class Point3d
{
public:
Point3d(float,float,float);
float X() const { return x; }
void X(float new_x) const { x = new_x; }
//...
private:
float x, y, z;
};
Point3d::X() 返回的是class内部的x,还是外部extern的那个x。现在指向class内部的x,但是早期C++编译器是指向外部extern的那个x。从而引出早期C++的两种防御性程序设计风格。
- 把所有的data members放在class声明起头处,以确保正确的绑定。
class Point3d
{
float x, y, z;
public:
float X() const { return x; }
};
- 把所有的 inline functions 不管大小放在class声明之外。
inline float Point3d::X() const { return x; }
备注:类成员函数,在类体内部(类定义头文件中)定义的函数默认就是内联函数。
一个inline函数实体,在整个class声明未被完全看见之前,是不会评估求值的。

绑定:

上述这种语言状况,仍然需要某种防御性程序风格**:请始终把“nested type声明”放在class的起始处**,在上述例子中,如果把length的nested typedf定义于“在class中被参考”之前,就可以确保非直觉绑定的正确性。
Data Member 的布局(Data Member Layout)
目前各家编译器都是把一个以上的access sections连锁在一起,依照声明的顺序,成为一个连续区块,Access sections的多寡并不会招来额外负担。例如在一个section中声明8个members,或是在8个sections中总共声明8个members,得到的object大小是一样的。
Data Member 的存取
Static Data Members
Static Data Members 并不在class object之中,因此存取Static Data Members并不需要通过class object。
如果多个class 有同样的Static Data Members,可以采用名字修饰(Name Mangling),以获得独一无二的程序识别代码。
Nonstatic Data Members
每一个nonstatic data member的偏移量(offset)在编译时期即可获知,甚至如果member属于一个base class subobJect(派生自单一或多重继承串链)也是一样。因此,存取一个nonstatic,其效率和存取一个c struct member或一个nonderived class的member是一样的。
Point3d *pt;
Point3d origin;
//...
origin.x = 0.0;
pt->x = 0.0;
执行效率在是一个struct member、一个class member、单一继承、多重继承的情况下都完全相同。但如果是一个virtual base class的member,存取速度会比较慢一点。
如果使用origin就不会有这些问题,其类型无疑是3Point3d,而即使它继承自virtual base class,members的offset位置也在编译时期就固定了,一个积极进取的编译器甚至可以静态地经由origin就解决掉对x的存取。
“继承” 与 Data Member
在大部分编译器上头,base class members总是先出现,但属于virtual base class的除外。
只需要继承不要多态(Inheritance without Polymorphism)
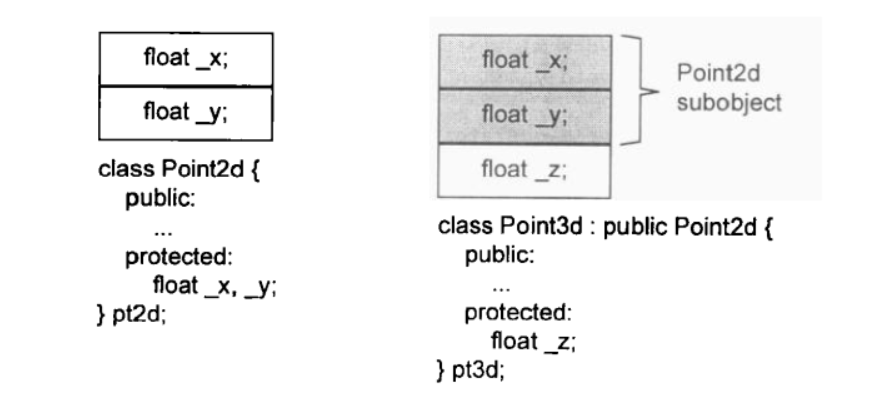
Point3d object的初始化操作或加法操作,将需要部分的Point2d object和部分的Point3d object作为成本。一般而言,选择某些函数做成inline函数,是设计class时的一个重要课题。
把一个class分解为两层或更多层,有可能会为了表现class体系之抽象化而膨胀所需的空间
以Concrete为例:
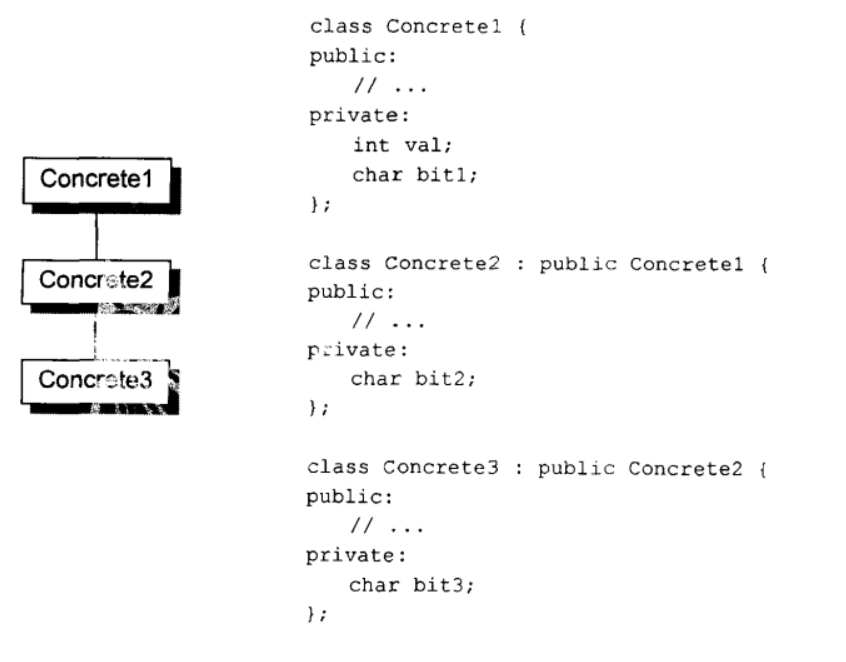
其对象布局如下:

加上多态(Adding Polymorphism)
如果处理坐标点时,不考虑是Point2d 或 Point3d 实例,则需要在继承关系中提供一个 virtual function接口:

Point3d 的新声明:
void operator+=(const Point2d& rhs)
{
Point2d::operator+=(rhs);
_z += rhs.z();
}
这样就可以实现 Point2d 和 Point3d 的加法。
把vptr放在class object的哪里比较好:
早期时将vptr放在class object的尾端,随着开始之初虚拟继承以及抽象基类等,某些编译器开始将vptr放在class object的头部。
多重继承(Multiple Inheritance)
多重继承的复杂度在于 derived class 和 其上一个base class乃至上上一个base class之间的非自然关系。
详情
class Point2d{
public:
// ... 有
protected:
float _x, _y;
};
class Point3d : public Point2d{
public:
// ... 有
protected:
float _z;
};
class Vertex{
public:
protected:
Vertex *next;
};
class Vertex3d :
public Point3, public Vertex{
public:
protected:
float mumble;
};
多重继承关系图:
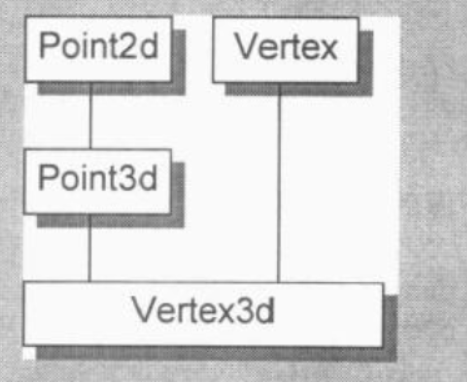
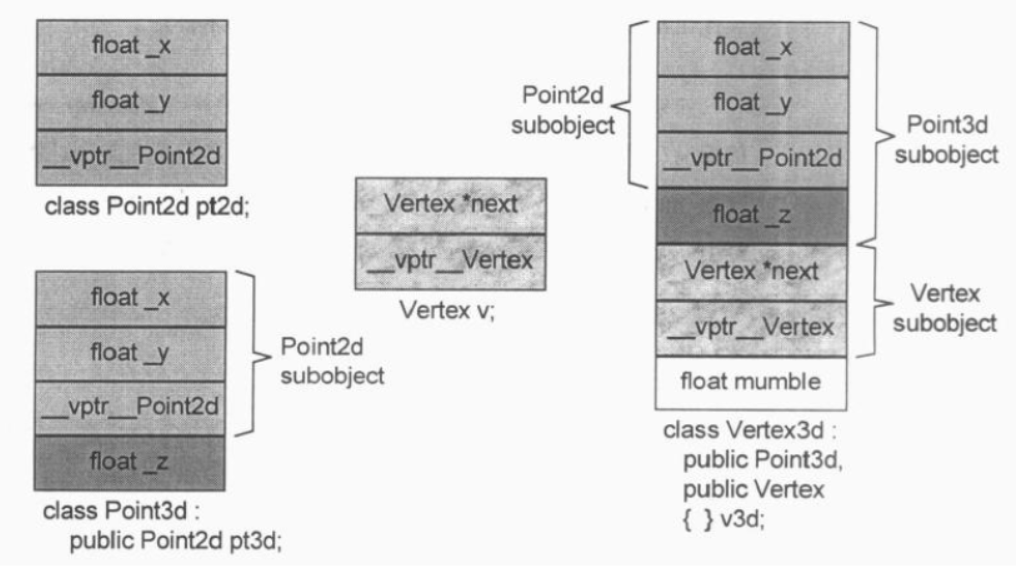
成员的位置在编译时就固定了,因此存取成员只是一个简单的offset运算,就像单一继承一样简单——不管是经由指针、引用还是对象来存取。
虚拟继承(Virtual Inheritance)
多重继承的一个副作用是,他必须支持某种形式的shared subobject继承。比如:
class ios{};
class istream : public ios{};
class ostream : public ios{};
class istream :
public istream, public ostream {};
不管istream还是ostream都内含一个ios subobject。然而在iostream的对象布局中,我们只需要单一一份ios subobject就好。解决方法是引入虚拟继承:
class ios{};
class istream : public virtual ios{};
class ostream : public virtual ios{};
class istream :
public istream, public ostream {};
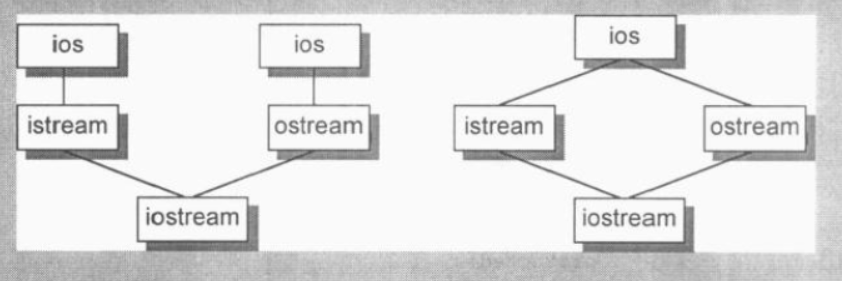
虚拟继承技术要求必须能够找到一个有效的方法:
将istream和ostream各自维护的一个ios subobject,折叠成一个由iostream维护的单一ios subobject,并且还可以保存基类和派生类的指针(或者引用)之间的多态指定操作。
一般的实现方法如下:
- 类如果内含一个或多个虚基类子对象,将被分割成两部分:一个不变区域和一个共享区域。
- 不变区域中的数据,不管后继如何演化,总是有固定的偏移量(从对象的开头算起),所以这一部分的数据可以被直接存取。
- 共享区域表现的就是虚基类子对象。这部分的数据,其位置会因为每次的派生操作而变化,所以它们只可以被间接存取。
一般的布局策略是先安排好派生类的不变部分,然后再建立其共享部分。
怎么存取类的共享部分呢?
cfront编译器会在每一个派生类对象中安插一些指针,每一个指针指向一个虚基类要存取继承到的虚基类成员,可以用指针间接完成。
这个实现模型有两个缺点:
- 每一个对象必须针对每个虚基类背负一个额外的指针。然而理想上我们却希望类对象有固定的负担,不因为其虚基类的数目而变化。这应该怎么解决呢?
- 引入虚基类表。每一个类对象如果有虚基类,就会由编译器安插一个指针,指向这个虚基类表。
- 在虚函数表中放置虚基类的偏移量。
- 由于虚拟继承串链的加长,导致间接存取层次增加。比如如果有3层虚拟衍化,就需要3次间接存取(经由三个虚基类指针)。然而理想上我们希望有固定的存取时间。这应该怎么解决呢?
- 拷贝所有的nested virtual base class指针,放到派生类对象中。这就解决了“固定存取时间”的间隔,虽然付出了一些空间上的代价。
一般来说,虚基类最有效的一种运用形式是:一个抽象的虚基类,没有任何数据成员。