
第3章:迭代器(iterators)概念与traits编程技法(二)
迭代器相应型别分析
template <class I>
struct iterator_traits {
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
## 迭代器相应型别之一:value type
所谓 value type,是指迭代器所指对象的型别。任何一个打算与STL算法有完美搭配的class,都应该定义自己的value type内嵌型别,例如STL中的vector定义:
template <class T,class Alloc = alloc>
class vector
{
public:
// nested type 定义
typedef T value_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type* iterator;
typedef const value_type* const_iterator;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef size_t s ize_type;
typedef ptrdiff_t difference_type;
...
};
## 迭代器相应型别之二:difference type
difference type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大容量。如果一个泛型算法提供计数功能,例如STL的count(),其传回值就必须使用迭代器的diference type:
template <class I,class T>
typename iterator_traits<I>::difference_type
count (I first, I last, const T& value){
typename iterator_traits<I>::difference_type n=0;
for(;first!=last;++first)
if(*first == value)
++n;
return;
}
## 迭代器相应型别之三:reference type
从“迭代器所指之物的内容是否允许改变”的角度观之,迭代器分为两种:不允许改变“所指对象之内容“”者,称为constant iterators,例如const int* pic;允许改变“所指对象之内容”者,称为 mutable iterators,例如int* pi。 当我们对一个 mutable iterators做解引用时,获得的应该是个左值( lvalue) ,可以被赋值。在 C++中,函数如果要返回左值,都是以by reference的方式进行, 所以当p是个 mutable iterators时,如果其value type是T,那么p的型别不应该是T,应该是 T&。将此道理扩充,如果 p是一个 constant iterators,其value type是 T,那么p的型别不应该是const T,而应该是const T&。 *p的型别,即所谓的reference type。
## 迭代器相应型别之四:pointer type
pointers和 references 在 C++中有非常密切的关连。 如果“传回一个左值,令它代表p所指之物”是可能的,那么“传回一个左值,令它代表p所指之物的位址”也一定可以。 我们能够传回一个 pointer,指向迭代器所指之物。
这些相应型别已在先前的ListIter class中出现过:
Item& operator*() const { return *ptr; }
Item* operator->() const { return ptr; }
Item&便是 ListIter的reference type而 Item*便是其pointer type。
## 迭代器相应型别之五:iterator_category
最后一个(第五个)迭代器的相应型别会引发较大规模的写代码工程。在那之前,我必须先讨论迭代器的分类。
根据移动特性与施行操作,迭代器被分为五类:
- Input lterator:这种迭代器所指的对象,不允许外界改变。只读(read only)。
- Output terator:唯写(write only)。
- Forward lterator:允许“写入型”算法(例如replace())在此种迭代器所形成的区间上进行读写操作。
- Bidirectiona lterator:可双向移动。某些算法需要逆向走访某个迭代器区间(例如逆向拷贝某范围内的元素),可以使用Biairectional lterators。
- Random Access lterator:前四种迭代器都只供应一部分指针算术能力(前三种支持 operator++,第四种再加上operator--),第五种则涵盖所有指针算术能力,包括p+n,p-n,p[n],pl-p2,p1<p2。
迭代器的分类与从属关系如下图所示:
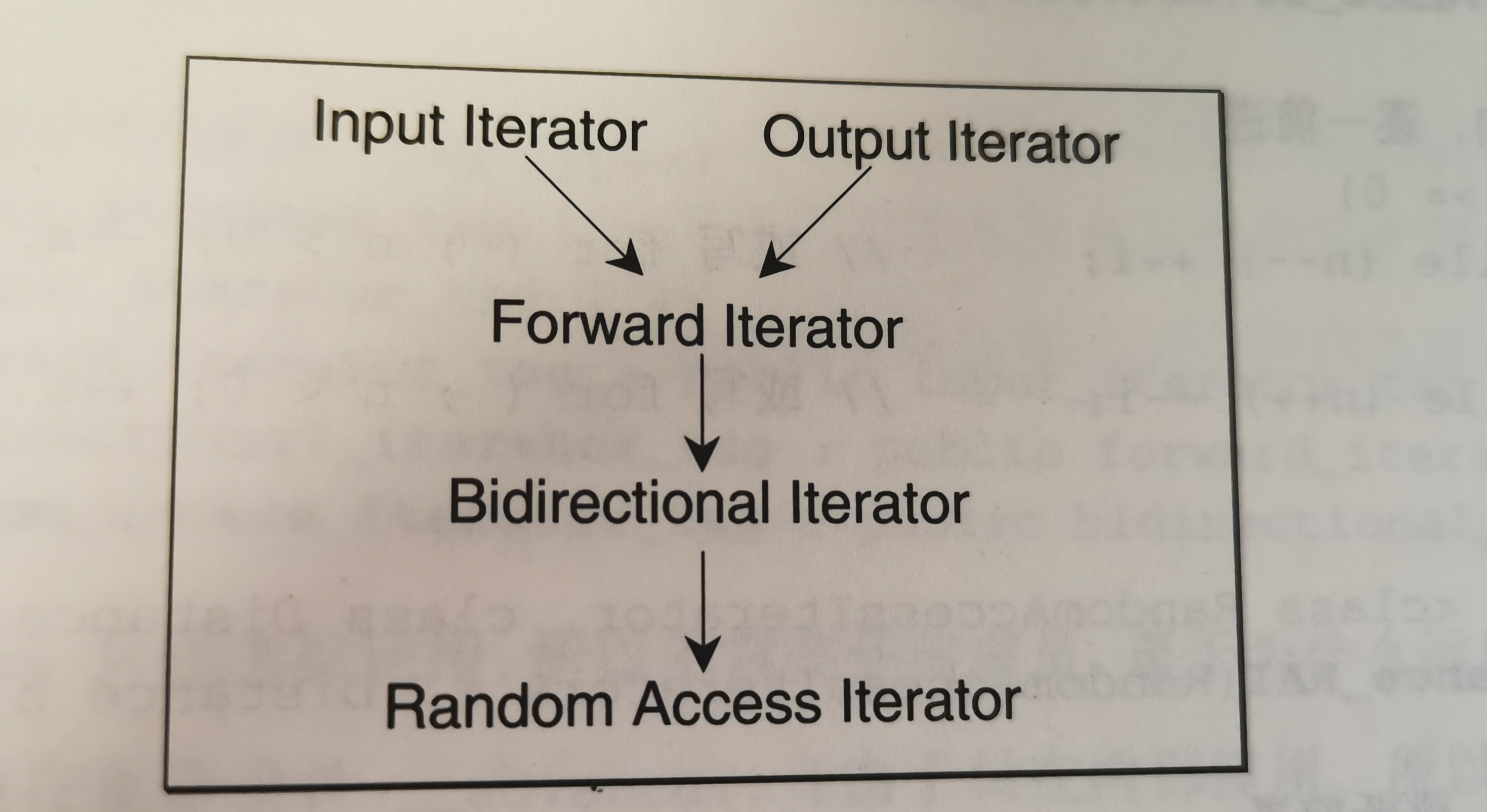
设计算法时,如果可能,我们尽量针对上图中某种迭代器提供一个明确定义,并针对更强化的某种迭代器提供另一定义,这样才能在不同情况下提供最大效率。假设有个算法接受 Forward Iterator,你以 Random Access Iterator 喂给它,也可用,但是可用不一定最佳。
下面以advanced()函数为例,介绍各类迭代器的性能差异:
template<class InputIterator,class Distance>
void advanced_II(InputIterator& i,Distance n)
{
//单向 逐一前进
while(n--) ++i;
}
template<class BidirectionalIterator, class Distance>
void advanced_BI(BidirectionalIterator& i,Distance n)
{
//双向 逐一前进
if(n>=0)
while(n--) ++i;
else
while(n++) --i;
}
template<class RandomAccessIterator, class Distance>
void advanced_RAI(RandomAccessIterator& i,Distance n)
{
//双向 跳跃前进
i += n;
}
当程序调用advance()时,应该调用哪一份函数定义呢?通常会采用以下处理方式:
template<class InputIterator,class Distance>
void advanced(InputIterator& i,Distance n)
{
if(is_random_access_iterator(i))//有待设计
advanced_RAI(i,n);
else if(is_bidirectional_iterator(i))//有待设计
advanced_BI(i,n);
else
advanced_II(i,n);
}
但是上述处理方式,**会在程序执行期间才能决定使用哪个处理函数,影响程序效率。最好能够在编译期就选择正确的版本,重载函数机制可以实现该目标。**我们可以给advanced( )添加第三个参数,即“迭代器类型”这个参数,然后利用traits萃取出迭代器的种类。
下面五个classes,即代表五种迭代器类型:
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
然后利用第三参数重新定义上面的advance()函数。
template<class InputIterator,class Distance>
inline void __advanced(InputIterator& i,Distance n,input_iterator_tag)
{
//单向 逐一前进
while(n--) ++i;
}
//这是一个单纯的传递调用参数(triv forwarding function) 稍后讨论如何免除之
template<class ForwardIterator,class Distance>
inline void __advanced(ForwardIterator& i,Distance n,forward_iterator_tag)
{
//单纯的进行传递调用
advance(i,n,input_iterator_tag);
}
template<class BidirectionalIterator, class Distance>
inline void __advanced(BidirectionalIterator& i,Distance n,bidirectionalIterator_iterator_tag)
{
//双向 逐一前进
if(n>=0)
while(n--) ++i;
else
while(n++) --i;
}
template<class RandomAccessIterator, class Distance>
inline void __advanced(RandomAccessIterator& i,Distance n,randomAccessIterator_iterator_tag)
{
//双向 跳跃前进
i += n;
}
对外开放的上层接口,调用上述各个重载的__advance()。这一上层接口只需两个参数,当它准备将工作转给上述的__advance()时,才自行加上第三参数:迭代器类型。因此,这个上层函数必须有能力从它所获得的迭代器中推导出其类型——这份工作自然交给traits机制:
template<class InputIterator, class Distance>
inline void advanced(InputIterator& i, Distance n)
{
__advace(i,n,iterator_traits<InputIterator>::iterator_categoty());
}
任何一个迭代器,其类型永远应该落在“该迭代器所隶属之各种类型中”,最强化的那个。同时,STL算法命名规则**:以算法所能接受之最低阶迭代器类型,来为其迭代器型别参数命名**,因此advance()中template参数名称为InputIterator。
消除“单纯传递调用的函数”:
由于各个迭代器之间存在着继承关系,“传递调用”的行为模式自然存在,即如果不重载Forward Iterators或BidirectionalIterator时,统统都会传递调用InputIterator版的函数。
std::iterator的保证
STL提供了一个iteratots class如下,如果每个新设计的迭代器都继承自它,则可以保证符合STL规范(即需要提供五个迭代器相应的类型)。
template <class Category, class T, class Distance = ptrdiff_t,
class Pointer = T*, class Reference = T&>
struct iterator {
typedef Category iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef Pointer pointer;
typedef Reference reference;
};
SGI STL的私房菜:__type_traits
traits编程技法很棒,适度弥补了 C++ 语言本身的不足。 STL只对迭代器加以规范,制定出iterator_traits这样的东西。 SGI 把这种技法进一步扩大到迭代器以外的世界,于是有了所谓的__type_traits。
iterator_traits负 责萃取迭代器的特性, __type_traits 则负责萃取型别(type)的特性。 型别特性是指:这个型别是否具备non-trivial defalt ctor ?是否具备 non-trivial copy ctor?是否具备 non-trivial assignment operator?是否具备 non-trivial dtor?如果答案是否定的,我们在对这个型别进行建构、解构、拷贝、赋值等动作时,就可以采用最有效率的措施(例如根本不调用身居高位,不谋其职的那些constructor, destructor), 而采用内存直接处理动作 如malloc()、 memcpy()等等,获得最高效率。这对于大规模而动作频繁的容器,有着显著的效率提升!
template <class type>
struct __type_traits {
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
以下是<type_traits.h>对所有C++标量类型所定义的__type_traits特化版本:
__STL_TEMPLATE_NULL struct __type_traits<char> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
__STL_TEMPLATE_NULL struct __type_traits<int> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
template <class T>
struct __type_traits<T*> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
前面第2章提到过的uninitialized_fill_n等函数就在实现中使用了__type_traits机制。
template <class ForwardIterator, class Size, class T, class T1>
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n,
const T& x, T1*) {
typedef typename __type_traits<T1>::is_POD_type is_POD;
return __uninitialized_fill_n_aux(first, n, x, is_POD());
}
————————————————————————————————————————————————————————————————————————————————
// 如果不是POD型别 就会派送(dispatch)到这里
template <class ForwardIterator, class Size, class T>
ForwardIterator
__uninitialized_fill_n_aux(ForwardIterator first, Size n,
const T& x, __false_type) {
ForwardIterator cur = first;
__STL_TRY {
for ( ; n > 0; --n, ++cur)
construct(&*cur, x);//需要逐个进行构造
return cur;
}
__STL_UNWIND(destroy(first, cur));
}
————————————————————————————————————————————————————————————————————————————————
//如果是POD型别 就会派送到这里 下两行是源文件所附注解
//如果copy construction 等同于 assignment 而且有 trivival destructor
//以下就有效
template <class ForwardIterator, class Size, class T>
inline ForwardIterator
__uninitialized_fill_n_aux(ForwardIterator first, Size n,
const T& x, __true_type) {
return fill_n(first, n, x); //交由高阶函数执行
}
//以下定义于<stl_algobase.h>中的fill_n()
template <class OutputIter, class _Size, class _Tp>
OutputIter fill_n(OutputIter first, Size n, const Tp& value) {
for ( ; n > 0; --n, ++first)
*first = value;
return first;
}